







2022.08.27 李航老师《统计学习方法》: 一. 统计学习及监督学习概论
# 本文目的就是为学者简化学习内容,提取我认为的重点 把书读薄;
# 本文重点:1.5 正则化理解
一. 统计学习及监督学习概论
1.4+1.5 L1、L2正则化
文章目录
1.4 模型评估与模型选择
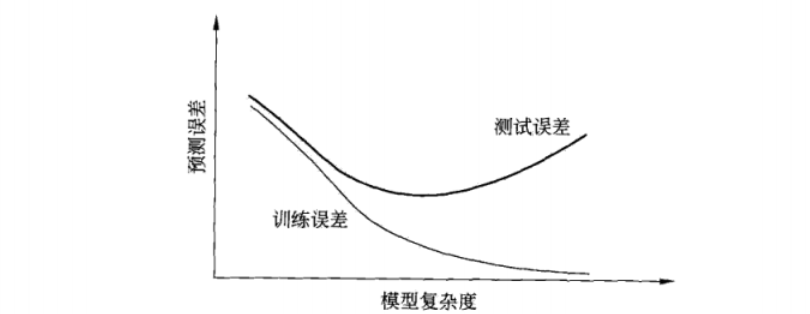
1.4.1 训练误差与测试误差
- 目的不仅仅是对已知数据,更重要的是未知数据有更好的预测能力。测试误差越小,预测能力越强。
- 不同的学习方法,测试误差可能不同,所以较小的是更好的。
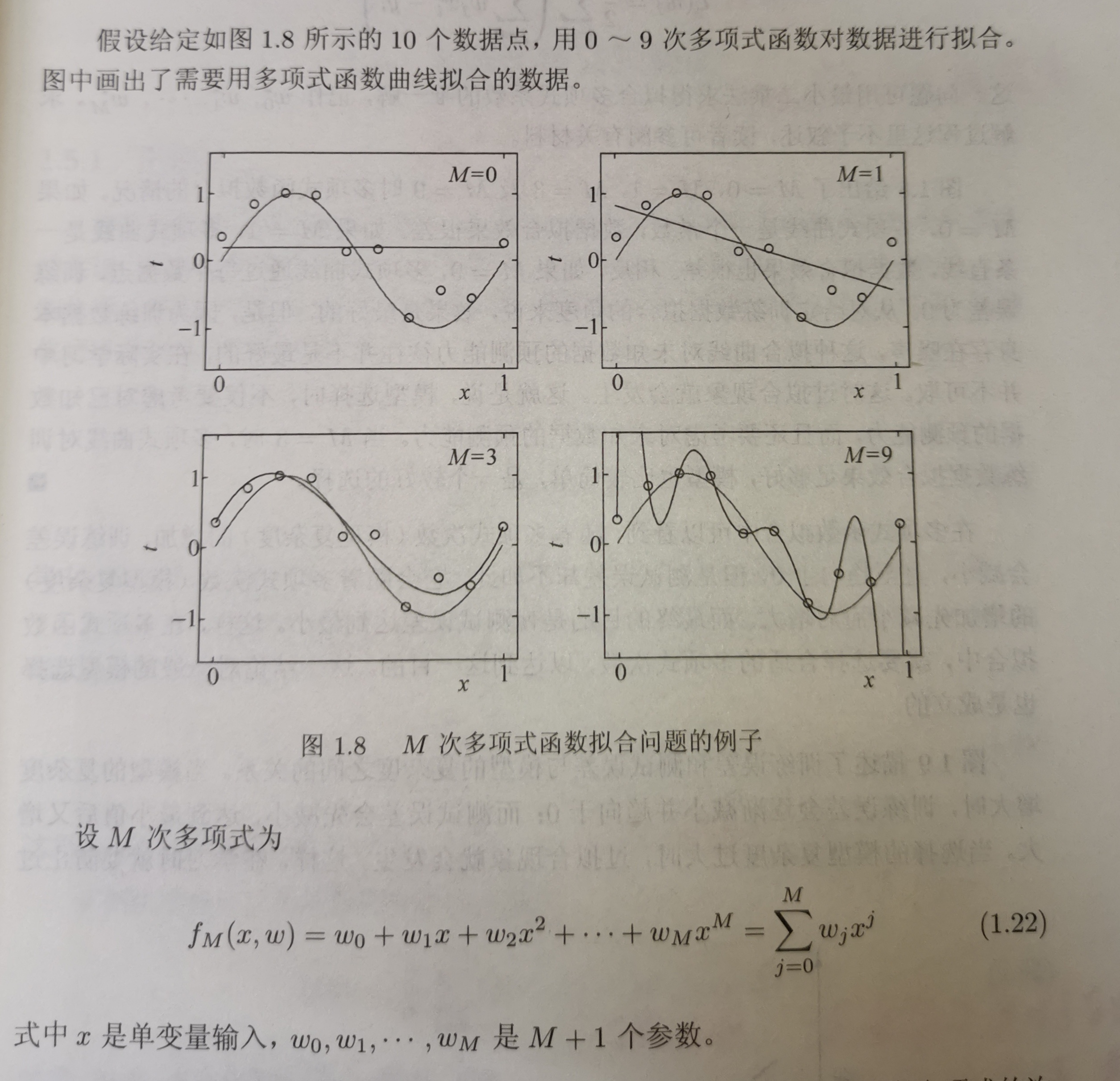
m=0: 就是未知数最高是0次幂 y=C 是条平行于x轴的线;
m=1:就是未知数最高是1次幂 y=kx+b 是条斜线;
- 我们发现:次数越高,穿过的训练数据越多,图形越复杂。也就是:函数越复杂,对训练集拟合就约好。
越复杂的函数,训练数据误差是逐步减小的,但在预测未知数据时是误差是先减小后增大的,原因就是过拟合。
1.5 正则化与交叉检验
1.5.1.1 正则化
机器学习会出现过拟合的现象,如何解决? 正则化。
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \mathop{\min}\limits_{f\in F}\frac{1}{N}\sum_{i=1}^N L(y_i,f(x_i))+\lambda J(f) f∈FminN1i=1∑NL(yi,f(xi))+λJ(f)
其中, λ J ( f ) \lambda J(f) λJ(f)为正则化项。
-
什么是正则化?
减少泛化误差的方法,也就是减少过拟合的方法,也就是不是减少训练误差而是减少测试误差的方法。 -
我们怎么思考去正则化限制测试误差? 有两个角度
第一种理解:见【图 1.8】,上一章有讲,未知数次数越高,泛化能力就约差,越容易过拟合,我们应该适当的限制次数;限制方法就是在适当的位置
m开始小到 w m , w m + 1 , . . . w_m,w_{m+1},... wm,wm+1,...均为0;
第二种理解:我们在训练神经网络的时候,比如输出层的输入:
z [ l ] = W [ l ] T ⋅ a [ l − 1 ] + b [ l ] z^{[l]}=W^{[l]^T}·a^{[l-1]}+b^{[l]} z[l]=W[l]T⋅a[l−1]+b[l]l是输出层,之前是隐藏层。就是用第l-1层输出的结果a带入到第l层神经网络上计算。- 我们把隐藏层的
w和b均扩大2倍时,那么l层输入变为了 2 ( l − 1 ) a [ l − 1 ] 2^{(l-1)}a^{[l-1]} 2(l−1)a[l−1], 我们把输出层W缩小 2 ( l − 1 ) 2^{(l-1)} 2(l−1)倍,那么
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











