







关于反向传播算法,很早之前就了解,但是关于细节问题一直未能理解,看了这篇翻译的文章写的很好
原文:http://blog.csdn.net/shijing_0214/article/details/51923547
Backpropagation算法是目前绝大多数神经网络在优化参数时用到的算法,具有快速方便容易实现的优点。那么它是如何实现的呢?
首先看一张典型神经网络结构图:
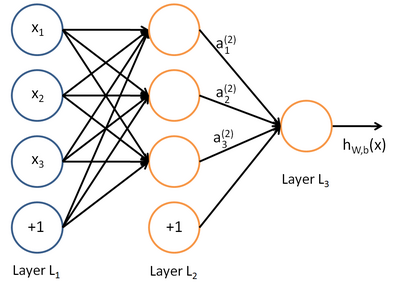
上图是一个包含了输入层L1、一个 隐含层L2和输出层L3的简单神经网络,它的处理流程为根据输入层的input以及相应的权重和偏置(图中黑色带箭头的边),通过隐含层的加工,最终将结果映射到输出层得到结果。模型可以抽象表示为 y=f(x),x,y分别表示输入输出向量,在分类问题中,y表示相应的类别 ,显然这是一个判别模型。
由神经网络的处理过程,想要得到输出 y ,我们必须知道上图中每条边的参数值,这也是神经网络中最重要的部分。在神经网络中是通过迭代的方法来计算这些参数的,具体来讲就是,首先初始化这些参数,通过神经网络的前向传导过程计算得到输出 y ,这些值与真实值存在着误差,不妨设累计误差函数为 err(x) ,然后利用梯度法极小化 err(x) 来更新参数,直至误差值达到要求停止计算。在更新参数这一过程中我们就用到了大名鼎鼎的反向传播算法。
为了能清楚说明神经网络的传播算法,我们取上图中的一条路径来做说明,不失一般性,假设路径为:
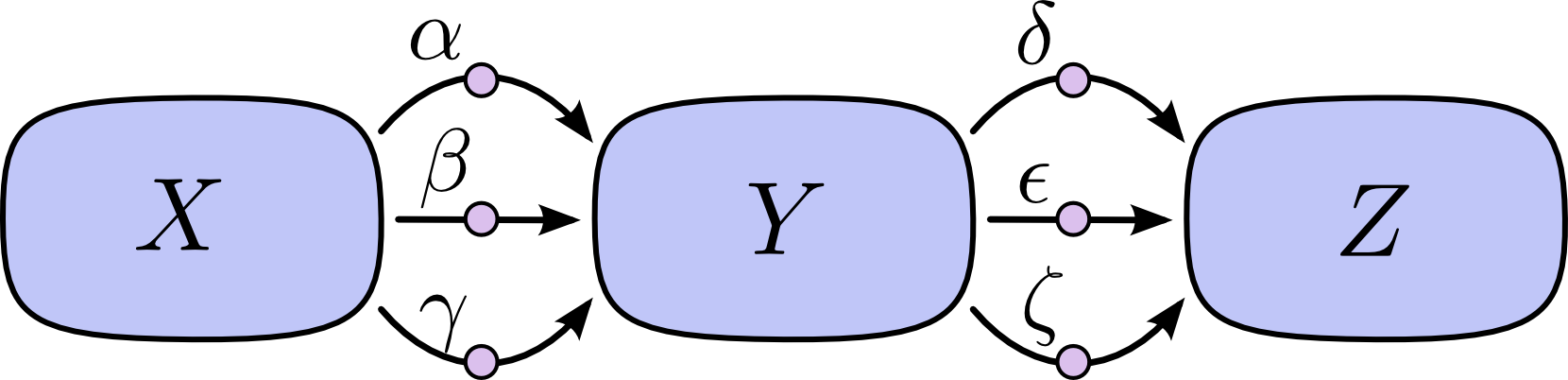
图中的边表示偏导数,如 α=∂Y∂X
想要知道输入 X 对输出 Z 的影响,我们可以用偏导数 ∂Z∂X=∂Z∂Y⋅∂Y∂X ,即:
∂Z∂X=αδ+αϵ+αζ+βδ+βϵ+βζ+γδ+γϵ+γζ⋯式子1
如果直接使用链式法则进行求导会出现一个问题,当路径数目增加时,该式子中的子项数目会呈指数增长,考虑到这种情况,我们把上式右侧进行合并,得到:
∂Z∂X=(α+β+γ)(δ+ϵ+ζ)⋯式子2
合并后的式子是不是非常清晰,关键是与式子1相比,只需要进行一次乘法就可以得出结果,大大提高了运算速度。
现在的问题是,对于式子2,应该如何实现?我们知道,假设一条
北京→郑州→武汉
的路径,我们可以先分析北京至郑州,再分析郑州至武汉;也可以先分析郑州至武汉,再分析北京至郑州。同理,根据计算方向的不同,可以分为正向微分与反向微分。我们先看针对上图的正向微分算法:
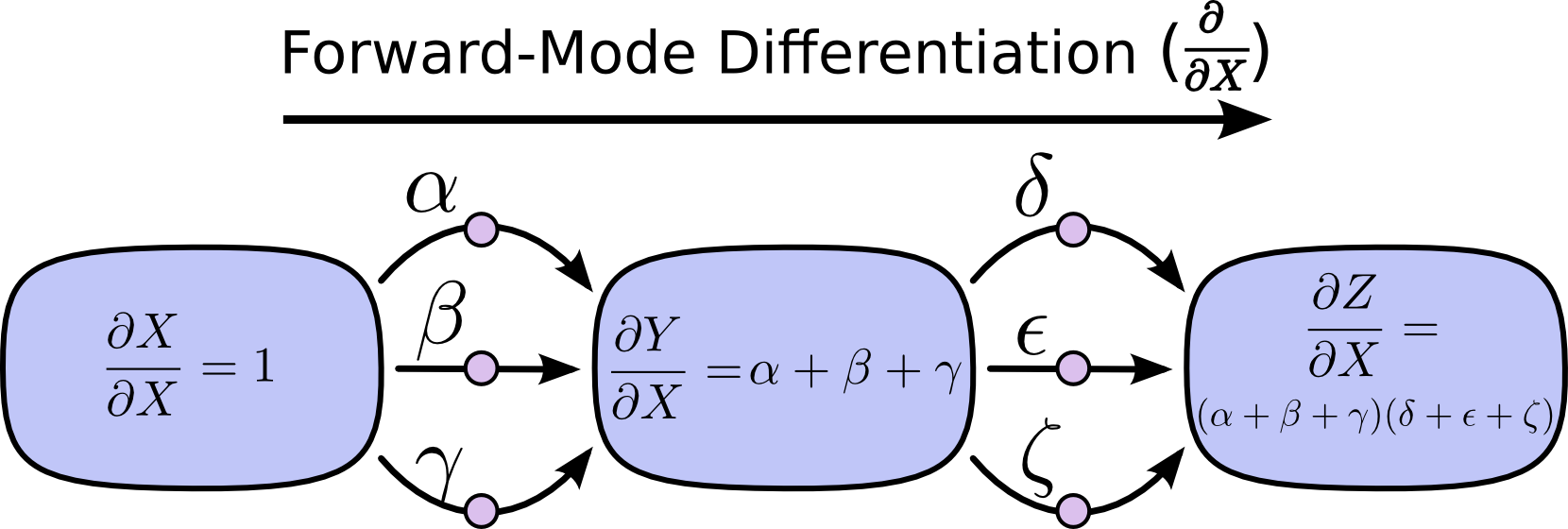
可以看到,正向微分算法根据路径的传播方向,依次计算路径中的各结点对输入 X 的偏导数,结果中保留了输入对各结点的影响。
我们再看下反向微分算法:

可以看到,该算法从后向前进行计算,结果中保留了路径中各结点对输出的影响。
这里就有一个问题了,既然正向反向都可以实现式子2的计算,那么我们应该选择哪个算法来实现呢?答案是反向微分算法,为什么呢?
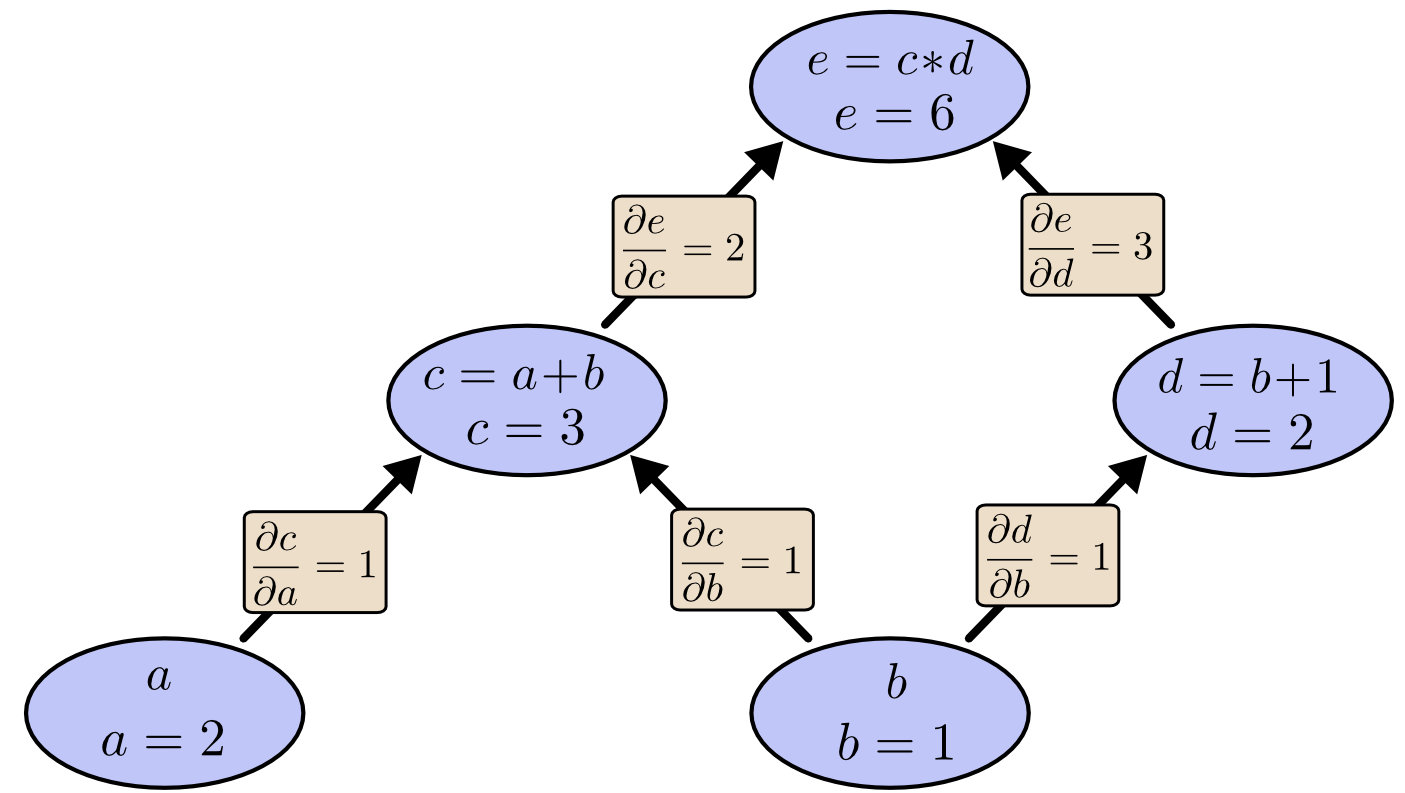
首先我们看一个计算式子
e=(a+b)∗(b+1)
的图模型:
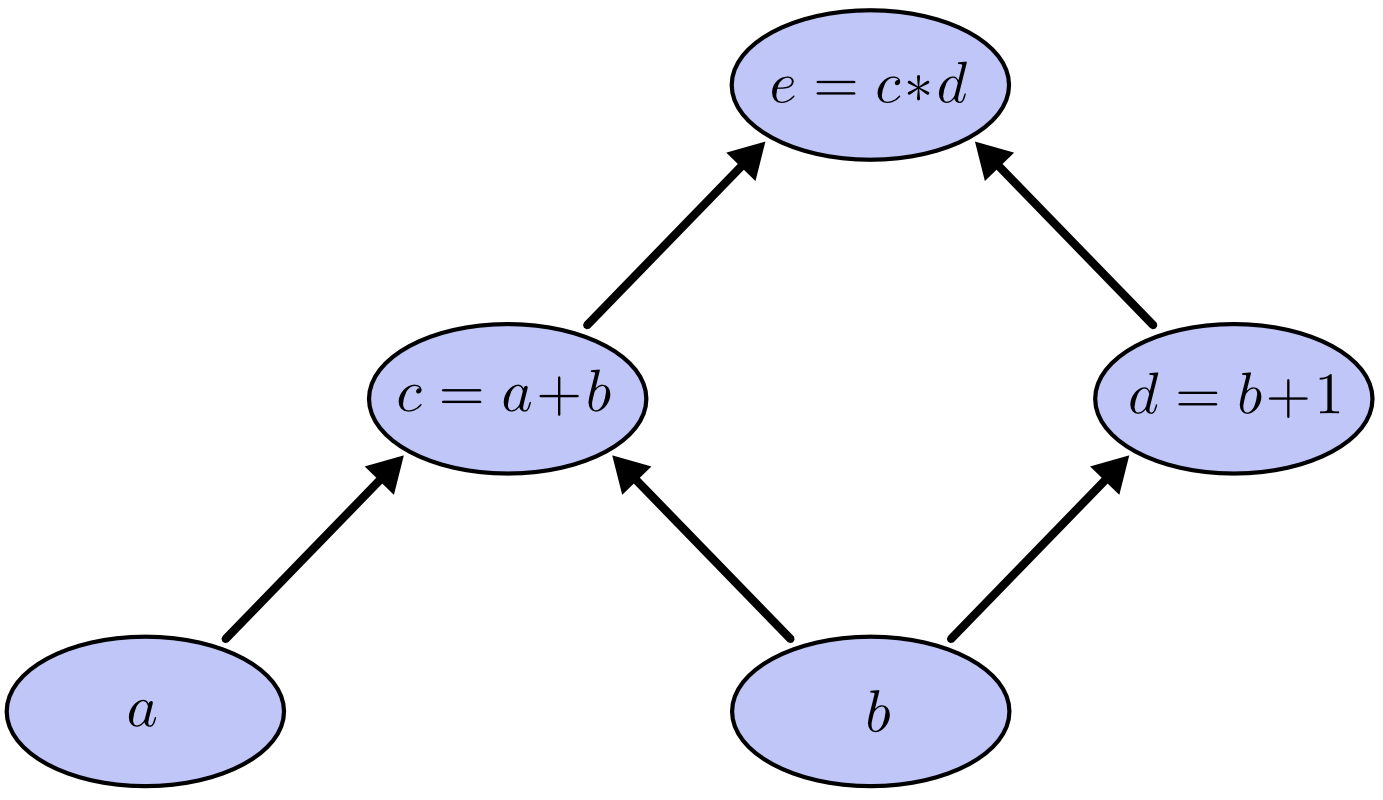
其中, c,d 表示中间结果,边的方向表示一个结点是另一个结点的输入。
假设输入变量 a=2,b=1 时,图中各结点的偏导计算结果如下:
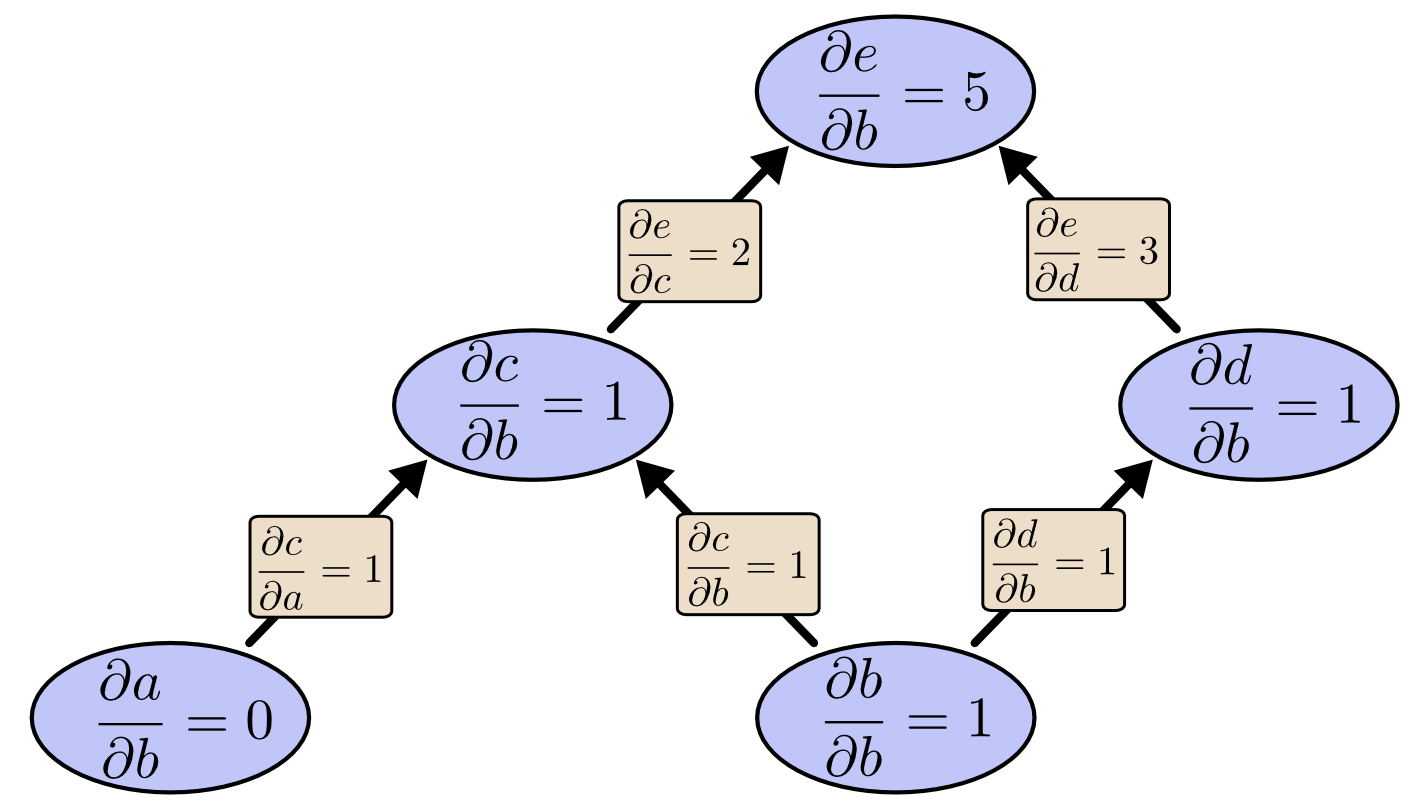
利用正向微分算法,我们得到关于变量b的偏导计算结果如下:
而利用反向微分算法,我们得到的偏导计算结果如下:
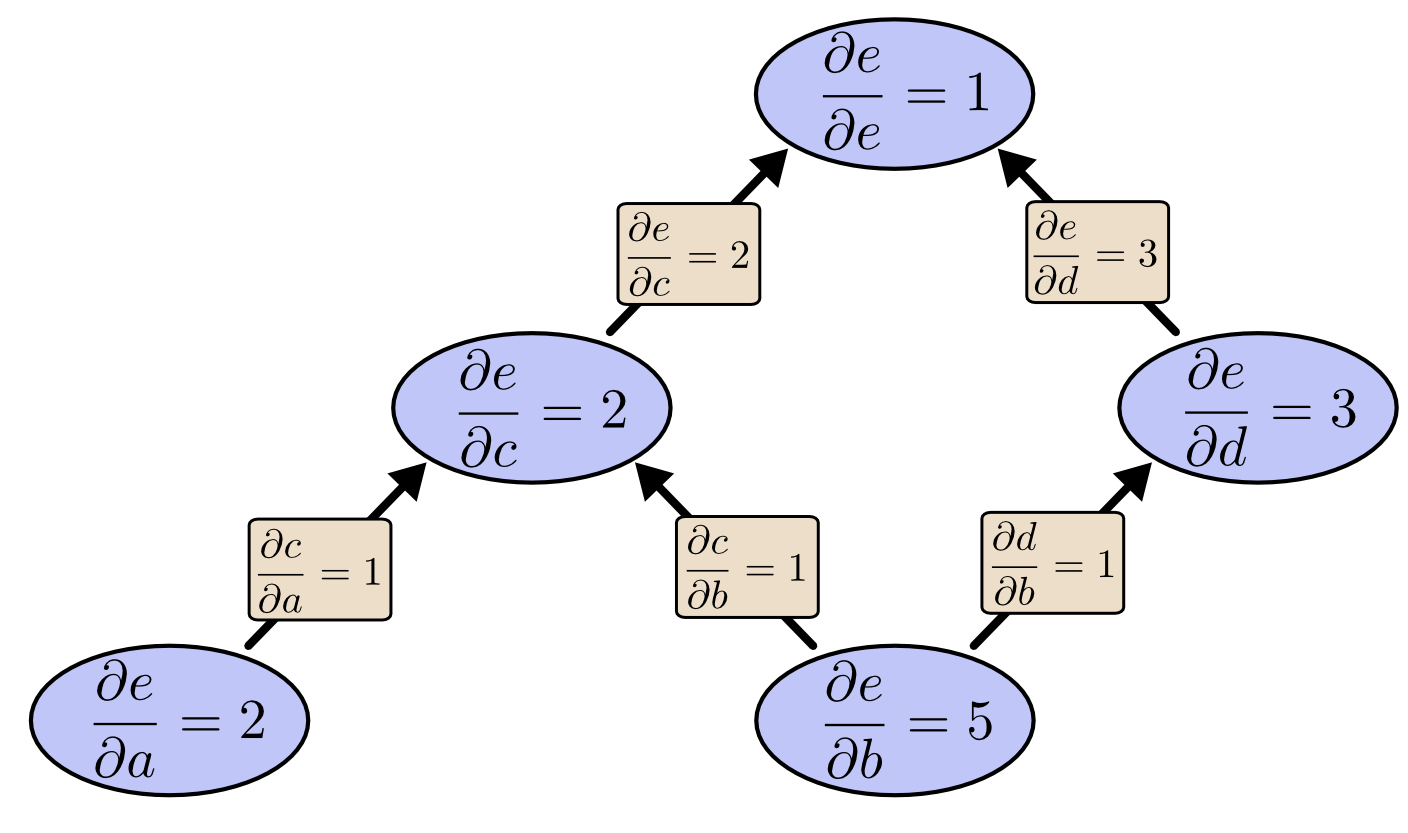
对比两张图,看到区别了么?
可以看出,反向微分算法保留了所有变量包括中间变量对结果
e
的影响。若
e
为误差函数,则对图进行一次计算,则可以得出所有结点对
e
的影响,也就是梯度值,下一步就可以利用这些梯度值来更新边的权重;而正向微分算法得到的结果是只保留了一个输入变量对误差
e
的影响,显然,想要获得多个变量对
e
的影响,我们就需要进行多次计算,所以正向微分算法在效率上明显不如反向微分,这也是我们选择反向微分算法的原因。
参考:
Calculus on Computational Graphs: Backpropagation
https://zhuanlan.zhihu.com/p/21407711?refer=intelligentunit
http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









