









最近在看到一文说Go 1.24有一项重大的性能改进,就是将默认的Map由原来的拉链式HashTable改为使用开放式的SwissTable,实现了性能的大幅提升。于是就查了一下SwissTable相关资料,它是由Google工程师在开源库absl中实现的一种Hash算法。
本文就与大家一起来研究一下它。
一、HashTable
HashTable是通过将Key进行Hash计算映射到HashTable中的某个位置,并将值存储到指定位置,以达到从键到值的映射的。
1. 链式
链式法就是当经过Hash函数映射到了相同的位置时,使用链表的方式将它们存储起来,如下图所示:
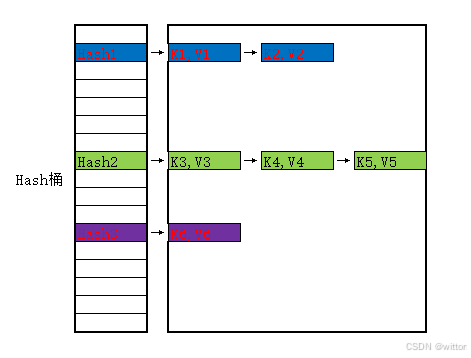
在查找的时候,先找到Hash桶的位置,再遍历链表,一个Key一个Key地查找。
链式法的添加与删除都比较高效,添加直接在链表头添加即可,删除就改几个指针。但是查询相对缓慢,需要遍历链表,一个个比较Key;由于存储比较分散,对缓存不友好。
2. 开放定址式
开放定址式是将所有数据存放在一块连续的内存中,这样集中存储,对缓存比较友好。这就需要在分配内存时一次性分配一定量的Hash桶用来存储,如果Hash桶不足以存放时,就需要重新分配Hash桶。
开放定址式与链式不一样,它是在发生冲突时,按一定规则(定址方式)在Hash桶上查到,而不是在另外的地方查找,如果找到了Hash桶的末尾,则从头开始查找,形成一个循环查找的过程,如下图所示:
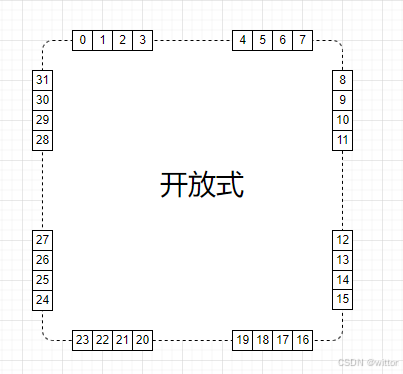
开放定址式的定址方式又有以下几种常见的做法:
- 线性探测法
线性探测法就是定位到索引i时,如果i位置已经有元素了,则依次查i+1,i+2,……,直到查到一个空位置,如果遇到数组末尾,则从头开始查找。 - 二次探测法
二次探测法就是定准到索引i时,如果i位置已经有元素了,则依次查i+12,i-12,i+22,i-22,…… - 随机法
随机法就是使用伪随机数来解决冲突。
开放定址法虽然解决了链式法对缓存不友好的问题,添加与删除也要快一些(直接定位到Hash桶添加、删除即可),但查找(定位)时如果有冲突,依旧需要依次比较Key。
二、SwissTable
SwissTable是传统开放定址式的HashTable,使用线性探测法的一种改进,有效减少了Key的比较。它的中心思想是在Hash桶上存储Key的Hash特征码,在使用线性探测法定位时,利用CPU的SIMD指令,一次性读取、比较一组特征码,找到特征码相同的索引,再在与Hash桶数量完全一致的数据槽区去比较Key值,这样就减少了Key的比较次数,同时利用Hash桶的索引直接在数据槽区取数据是非常高效的。
1. SwissTable的内存布局
SwissTable的整个内存布局为控制字节区 (包含有效控制字节区+结束标志+控制字节克隆区+内存对齐字节区)加Slots区,在进行内存分配的时候就把它们一起分配。如下图所示:

可以看看absl代码的内存布局:


其中的control就是控制字节的指针,slot_array为Hash桶的槽位数组,即数据的实际存储区。
1.1 控制字节
控制字节也被称为元信息,它有以下几种状态:
空,用0x80表示,二进制为0b10000000已删除元素,用0xFE表示,二进制为0b11111110结束标志,用0xFF表示,二进制为0b11111111有效元素,最高位始终为0,低7位为Hash值的低7位
控制字节的有效元素值是如何来的?
根据Key,计算出一个64位的Hash值,它的高57位为H1,低7位为H2,H1的值来定位有效控制字节区的索引,索引位置存放的即是H2的值,也被称为该Key的特征值。
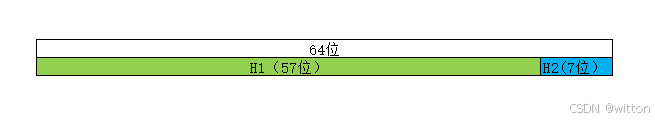
控制字节的非有效元素为什么最高位为1?
在absl的实现中,将控制字节定义有一个有符号数,类型为int8_t:
enum class ctrl_t : int8_t {
kEmpty = -128, // 0b10000000
kDeleted = -2, // 0b11111110
kSentinel = -1, // 0b11111111
};
这样在判断是否为有效元素时,只需要判断是否大于等于0即可;同时,在查找可用槽位时,只需要与结束标志作比较即可,比结束标志小的标志槽位都是可用的(已使用的槽位,控制字节都比结束标志大),非常高效!
1.2 有效控制字节区
为了方便讲解,我把结束标志前面的控制字节区域称为有效控制字节区。有效控制字节区大小始终为2N-1,这样的设计非常巧妙,便于提升性能,因为2N-1的二进制表示中每位都为1,在计算Slot索引的时候,可以直接按位与即可直接定位,而且不会越界。相比之下,如果使用其它数,则为了在计算索引时不越界,需要进行模运算,是非常耗时的。
1.3 控制字节克隆区
为什么要有控制字节克隆区?
前面有介绍开放定址方式存取时查地址是一个循环的过程,如果查到尾部了,则需要从头开始查,由于SwissTable是按组查找,一次性读取一组的数组,如果组是从最后一个有效控制字节开始的,则需要循环读取前面的数据,所以需要把前面的有效控制字节复制到后面方便直接读取。
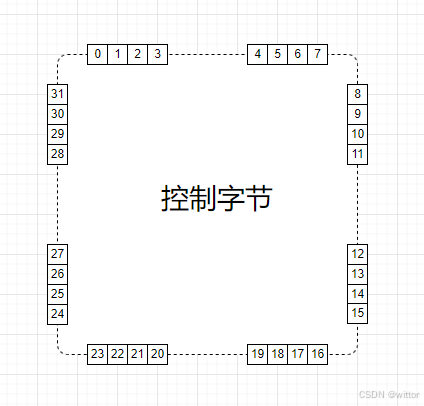
控制字节克隆区为15个字节,克隆控制字节的头部有效字节,比如3个控制字节,就克隆3个,后面的填充为空(0x80),如果超过15个字节,则只克隆15个字节。
控制字节克隆区为15个字节的设计也是经过精心设计的,它是根据SIMD(单指令多数据)指令(x86就是SSE2中的指令)中的数据大小(16字节)来设计的,结束标志加上15个字节刚好是16个字节。在查找时,则是按16字节为一组(Group)进行查找。
1.4 Slots区
Slots区紧跟前面的控制字节区,Slot的个数与有效控制字节区的大小完全一致,定位时可以直接使用索引进行关联。每个Slot的大小为要存储的元素的大小,比如int32_t为4个字节,则一个Slot的大小为4字节,如果是Map,则为Key与Value的大小和。
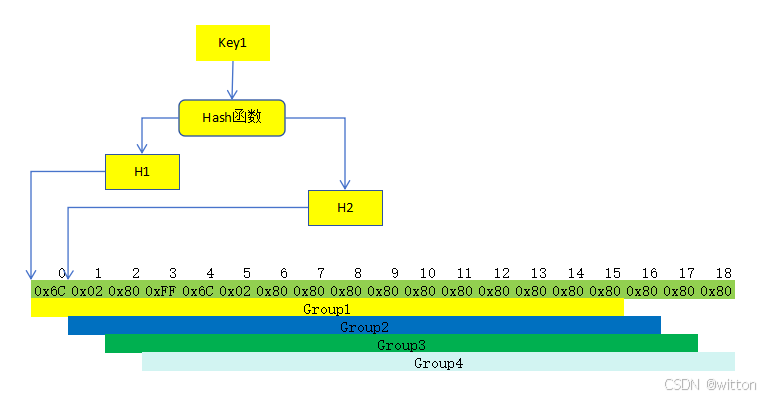
2. SwissTable的查找
根据前面的介绍,H1决定索引,在查找时根据索引位置,一次取16个字节作为一组进行匹配,看这16个字节中有哪些是与特征值H2相同的,再在这些H2相同的索引所对应的Slot中去查找Key,如果Key相同,则找到了,如果没有找到,则取下一组控制字节进行特征值比较,如此循环,直到找到或者找完所有控制字节。如下图所示,如果Group1没找到则继续按Group2查找:
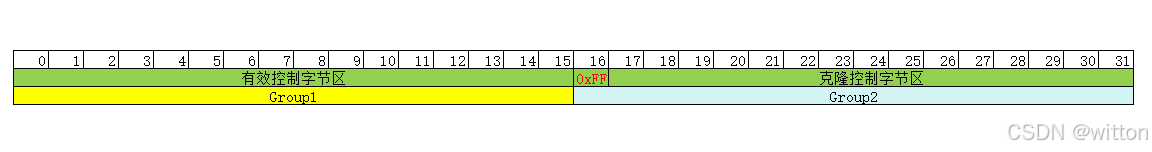
2.1 通过H1计算索引
前面有说到有效控制字节区的大小cap始终为2的N次方减1,是方便通过位运算直接定位索引,减少计算,即H1&cap,它的取值范围为[0, cap]
这里举例来说明:
假如有效控制字节区的大小cap为3,则H1决定的索引取值范围为[0,3]。如果当前Key计算的H1值为0x43,0x43&3值为3,直接定位在结束标志上,结束标志后面还有15个字节,存储的是有效控制字节的头部克隆,这16个字节刚好是一个SIMD指令数据大小,则可以按下图所示的Group4进行查找,相当于是从头查找了。
同样地,如果H1&3为0,则按Group1进行查找,H1&3为1,则按Group2查找,以此类推,如下图所示:
2.2 匹配控制字节
在按组查找的过程中,使用SIMD指令一次比较16个字节,比较的结果也是一个16字节的值,再使用SIMD指令将之压缩成32位的值,其实有效位就是16位,直接转成16位的整数,如下图所示:
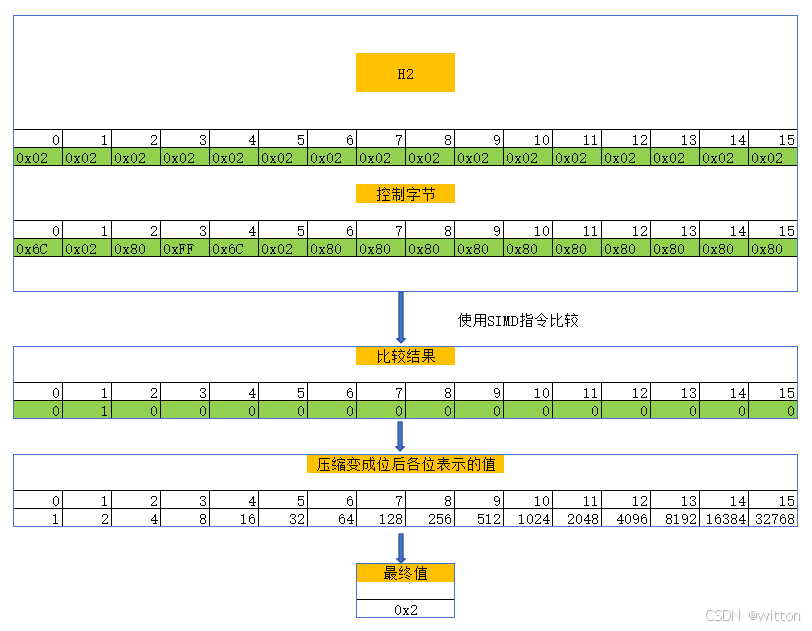
如果有多个相等的值,则最终值是按压缩后各位表示的值相加。
压缩后各位表示的值是一个特殊的值,它是2的索引次方,即N号位置为2n,而2n的二进制正好是尾部有n个0,这为通过值来计算索引提供了一个简便的方法,即计算尾部0的个数。
2.3 比较Key值
前面通过一组控制字节的比较,得到了一个匹配的16位值。通过这个值,可以得到其索引,即计算这个16位值的尾部有多少个0,再与之前线性探测到的索引进行计算,公式为:(探测到的索引+尾部0的个数)& 控制字节大小,得到槽slot的实际的索引。有了slot的索引,即可取Key进行比较了。
举个例子:
假设目前控制字节的大小为7,数据如下图所示:

在线性探测时,根据H1得到索引为2,即0x0d所在位置,根据H2得到特征值为0x14,在匹配时一次性读取的数据是从索引为2的位置开始后的16个字节,即0x0d,0x27,0x14,0x1a,……,然后与0x14 ,0x14,0x14,0x14,……进行比较,根据前面的压缩位表示的值相加,得到一个压缩后的最终值:4+1024=1028(如下图所示),十六进制为0x0404,这个值尾部有2个0,即索引为2,加上之前H1的索引2,则最终索引为4,即是Slot中的索引。

3. SwissTable的插入、扩展、替换
在插入之前,需要自行查找,如果找到了,则替换;如果没找到,且没有可使用的空间,则需要扩展SwissTable,有使用空间则写入找到的位置。
SwissTable的空间扩展一定是按2n-1的规则来扩展的。
absl的实现中在控制字节前面有一个GrowthInfo,用来记录,SwissTable还有多少空间。
三、SwissMap的C++实现
如果对C++模板不是很熟悉,为了学习SwissTable,直接去看absl的实现,可能会觉得云里雾里,有太多额外的东西干扰视线了,不便于快速掌握核心,笔者根据absl源码,实现了一个简单的SwissMap,并且写上了详细注释,方便快速掌握SwissTable的核心。经过简单测试,完全可用,附上源码:
swissmap.h:
#include <cassert>
#include <cstddef>
#include <cstdint>
#include <functional>
#include <bit>
#include <emmintrin.h>
#include <random>
template<typename K, typename V>
class CSwissMap {
static const int kWidth = 16;
enum class Ctrl : int8_t {
kEmpty = -128, // 0b10000000
kDeleted = -2, // 0b11111110
kSentinel = -1, // 0b11111111
};
struct Slot {
K k;
V v;
};
Ctrl* m_ctrl; // 控制字节数组
Slot* m_slot; // 槽数组
size_t m_cap = 0; // 控制字节容量
size_t m_num = 0; // 控制字节使用量
size_t m_growthInfo = 0; // 在rehash前,可以存储的数量,变量名遵循absl中的命名
size_t m_salt = 0; // hash 盐
public:
CSwissMap() {
// 使用random_device生成一个随机数种子,
// 再梅森旋转算法生成一个64位的随机数作为hash盐
std::random_device rd;
std::mt19937_64 gen(rd());
m_salt = gen();
init(0);
}
CSwissMap(const CSwissMap&) = delete;
CSwissMap(const CSwissMap&&) = delete;
CSwissMap& operator=(const CSwissMap&) = delete;
CSwissMap& operator=(const CSwissMap&&) = delete;
virtual ~CSwissMap() {
if (m_ctrl != nullptr) {
delete[] m_ctrl;
m_ctrl = nullptr;
}
m_cap = 0;
m_num = 0;
m_growthInfo = 0;
m_salt = 0;
}
V* operator[](K key) {
return find(key, false);
}
void insert(const K& key, const V& v) {
V* x = find(key, true);
new(x) V(v);
}
bool erase(const K& key) {
uint64_t index = 0;
int8_t h2 = 0;
if (findIndex(key, index, h2)) {
// 设置删除标志
setCtrl(index, (int8_t)Ctrl::kDeleted);
// 销毁Slot
destorySlot(m_slot[index]);
// 已使用的控制字节数量减1
m_num--;
// 可存储槽数量加1
m_growthInfo++;
return true;
}
return false;
}
private:
constexpr size_t align(size_t x, size_t a) {
return (x + a - 1) & (~(a - 1));
}
void init(size_t n) {
// 控制字节总大小需要加上结束标志(1个字节)与克隆大小(15个字节)
size_t ctrlSize = sizeof(Ctrl) * (n + kWidth);
// 按16字节对齐
size_t alignCtrlSize = align(ctrlSize, 16);
// 槽大小
size_t slotSize = sizeof(Slot) * n;
// 总大小
size_t size = alignCtrlSize + align(slotSize, 16);
char* p = new char[size];
m_ctrl = (Ctrl*)p;
m_slot = (Slot*)(p + alignCtrlSize);
// 将所有控制字节设置为空
memset(m_ctrl, (int)Ctrl::kEmpty, ctrlSize);
// 设置控制字节结束标志
m_ctrl[n] = Ctrl::kSentinel;
m_cap = n;
// 根据控制字节容量以及使用情况设置增长信息
m_growthInfo = (n - n / 8) - m_num;
}
void rehash(size_t n) {
// 先保存之前的控制字节、槽以及容量信息
auto ctrl = m_ctrl;
auto slot = m_slot;
auto cap = m_cap;
// 使用新的容量分配内存
init(n);
// 重置已经使用的数量
m_num = 0;
// 将之前已经存在的数量,按新的内存重新分配
for (auto i = 0; i < cap; ++i) {
// 只处理有效控制字节
if (int(ctrl[i]) >= 0) {
Slot& s = slot[i];
V* x = find(s.k, true);
// 使用指定内存调用V的构造函数
new(x) V(s.v);
// 销毁原来的Slot
destorySlot(s);
}
}
// 释放原来的内存
delete[] ctrl;
}
void destorySlot(Slot& slot) {
// 由于Slot所在内存是与ctrl一起分配的,
// 所以不能单独释放内存,这里只能调用析构函数
// 调用Key的析构函数
slot.k.~K();
// 调用Value的析构函数
slot.v.~V();
}
bool IsValidCapacity(size_t n) {
return ((n + 1) & n) == 0 && n > 0;
}
// 下一次分配控制字节内存所需要的容量
// 控制字节的容量始终为2的N次方减1
size_t nextCap() {
assert(IsValidCapacity((m_cap * 2) + 1));
return (m_cap * 2) + 1;
}
// 获取槽的索引
uint64_t getSlotIndex(uint64_t index, uint16_t mask) {
// 根据H1计算的索引index加上匹配的mask索引
// 为了避免越界,需要限制在m_cap范围内
// 由于m_cap的二进制位全部是1,所以直接位与即可
assert(m_cap == 0 || IsValidCapacity(m_cap));
return (index + std::countr_zero(mask)) & m_cap;
}
// 根据key查找槽的索引
// 成功找到返回true,retIndex为该key所对应的槽索引
// 未找到返回false,retIndex为该key所对应的空槽索引
bool findIndex(const K& key, uint64_t& retIndex, int8_t& h2) {
std::hash<K> h;
// 计算key的hash值
uint64_t k = h(key);
// 给hash值加盐
k ^= m_salt;
h2 = H2(k);
// 一次性填充16字节的特征值h2
__m128i match = _mm_set1_epi8(static_cast<char>(h2));
uint64_t h1 = H1(k);
// 根据h1计算控制字节的索引
auto index = h1 & m_cap;
while (true) {
// 从index开始的位置,一次性读取16字节数据
__m128i ctrl = _mm_loadu_si128((const __m128i*)(&m_ctrl[index]));
// 与填充的特征值进行“相等”比较,即:match == ctrl
auto x = _mm_cmpeq_epi8(match, ctrl);
// 将比较的结果进行压缩
auto mask = static_cast<uint16_t>(_mm_movemask_epi8(x));
while (mask != 0) { // 压缩的结果不为0,则表示有匹配的特征值
// 计算槽相对m_ctrl的索引
auto slotIndex = getSlotIndex(index, mask);
assert((uint64_t)m_ctrl[slotIndex] == h2);
// 如果是指定的Key则返回
if (m_slot[slotIndex].k == key) {
retIndex = slotIndex;
return true;
}
// 由于处理时是计算的尾部有多少个0,
// 所以之前处理的是低位的第一个1,现在将其置为0
mask &= mask - 1;
}
// 压缩结果为0,则没有匹配的特征值,检查空槽
__m128i matchEmpty = _mm_set1_epi8(static_cast<char>(Ctrl::kEmpty));
x = _mm_cmpeq_epi8(matchEmpty, ctrl);
mask = static_cast<uint16_t>(_mm_movemask_epi8(x));
if (mask != 0) {
// 计算槽相对m_ctrl的索引
retIndex = getSlotIndex(index, mask);
return false;
}
// 当前group没有找到,定位到下一group,继续查找
index += kWidth;
// 索引不能越界
index &= m_cap;
}
}
V* find(const K& key, bool isAdd) {
refind:
uint64_t index = 0;
int8_t h2 = 0;
if (findIndex(key, index, h2)) {
// 如果成功找到,返回Value的地址
return &m_slot[index].v;
}
// 没有找到,需要添加
if (isAdd) {
// 一次性读取16个字节
__m128i ctrl = _mm_loadu_si128((const __m128i*)(&m_ctrl[index]));
// 填充16个字节的结束标志
__m128i specail = _mm_set1_epi8(static_cast<char>(Ctrl::kSentinel));
// 与specail进行“大于”比较,即:specail > ctrl,筛选出所有空及已删除的标志
// specail中填写的是-1,所以大于空(-128)以及删除标志(-2),
// 但不大于有效控制字节,因为有效控制字节是非负数
auto x = _mm_cmpgt_epi8(specail, ctrl);
uint16_t mask = static_cast<uint16_t>(_mm_movemask_epi8(x));
if (mask != 0) {
// 如果还可以存储,直接存储
if (m_growthInfo > 0) {
// 这里需要根据mask重新计算索引
index = getSlotIndex(index, mask);
assert(m_ctrl[index] == Ctrl::kEmpty || m_ctrl[index] == Ctrl::kDeleted);
// 在控制字节中设置特征值h2
setCtrl(index, h2);
// 在设置对应槽的Key
new(&m_slot[index].k) K(key);
// 增加控制字节使用数
m_num++;
// 减少可存储数
m_growthInfo--;
return &m_slot[index].v;
}
}
// 不能再存储了,需要rehash重新分配空间了
rehash(nextCap());
// 重新分配了空间,需要重新查找
goto refind;
}
// 只查找,没找到
return nullptr;
}
void setCtrl(uint64_t index, int8_t h) {
m_ctrl[index] = (Ctrl)h;
if (index < kWidth - 1) {
// 如果index小于克隆字节大小,则需要同时设置克隆区的控制字节
m_ctrl[index + m_cap + 1] = (Ctrl)h;
}
}
uint64_t H1(uint64_t hash) {
// 取hash值的高57位,并加盐,
// 盐是根据当前控制字节的首地址右移12位,12位刚好是一个内存页大小
return (hash >> 7) ^ ((uintptr_t)(m_ctrl) >> 12);
}
int8_t H2(uint64_t hash) {
// 取hash值的低7位
return (int8_t)(hash & 0x7F);
}
};
测试代码:
main.cc:
#include <assert.h>
#include <string>
#include <windows.h>
#include "swissmap.h"
int main(int argc, char* argv[]) {
auto t1 = timeGetTime();
char buf[32];
CSwissMap<int, std::string> m;
int num = 1000'0000;
for (int i = 1; i <= num; ++i){
sprintf(buf, "str%d", i);
m.insert(i, buf);
}
for (int i = 1; i <= num; ++i){
m.erase(i);
}
auto t2 = timeGetTime();
printf("swissMap %d次,耗时:%lu\n", num, t2 - t1);
return 0;
}
CMakeLists.txt:
cmake_minimum_required(VERSION 3.25.0)
project(swissmap VERSION 0.1.0 LANGUAGES C CXX)
set(CMAKE_CXX_STANDARD 20)
if(MSVC)
add_compile_options(/source-charset:utf-8)
endif()
add_executable(${PROJECT_NAME} main.cc)
if(CMAKE_HOST_WIN32)
target_link_libraries(${PROJECT_NAME} PRIVATE winmm.lib)
endif()
include(CTest)
enable_testing()
set(CPACK_PROJECT_NAME ${PROJECT_NAME})
set(CPACK_PROJECT_VERSION ${PROJECT_VERSION})
include(CPack)
笔者将之与absl中的flat_hash_map进行测试对比,这是Debug版本的对比:
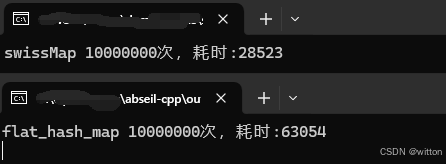
这是Release版本的对比:
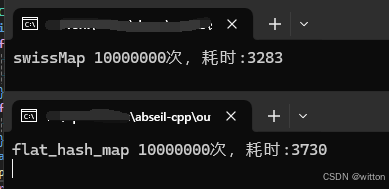
针对本测试用例,笔者的实现在Debug版本下性能是absl的2倍多,在Release版本下也要快一些。
以上代码在Windows下使用VS2022以及MinGW的Clang 19.1、GCC 14.2编译测试通过!
如果对你有帮助,欢迎点赞收藏!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









