






一、数据来源
字段说明
- effect_tb.csv: 广告点击情况数据集(ABtest使用此文件即可)
- 原项目答案未清洗交叉用户,最终结果有误,所以参考思路,重新计算
二、项目实操
具体代码运行可查看我的GitHub
常规开头
# 导入常用库
import pandas as pd # 数据处理主力军
import numpy as np # 数学计算 + 缺失值处理
import matplotlib.pyplot as plt # 可视化
import seaborn as sns # 更美观的可视化
# 设置图表风格
sns.set(style="whitegrid") # 让图表背景更清爽
plt.rcParams['font.size'] = 12 # 设置默认字体大小
plt.rcParams['figure.figsize'] = (10, 6) # 设置图表默认大小
# 设置 Pandas 显示参数
pd.set_option('display.max_columns', 100) # 最多显示 100 列(避免列被省略)
pd.set_option('display.max_rows', 100) # 最多显示 100 行(避免行被省略)
pd.set_option('display.max_colwidth', 200) # 每列最多显示 200 个字符(防止文本被截断)
pd.set_option('display.float_format', '{:.2f}'.format) # 浮点数显示为 2 位小数
# 设置支持中文的字体(如微软雅黑、SimHei等)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
数据读取
df_click = pd.read_csv('effect_tb.csv')
df_click.head()
effect_tb是广告点击情况数据集,列没有说明,此处按项目答案理解:
- 第一列:日志天数,此处无用
- 第二列:user_id,支护宝用户id
第三列:is_click,是否点击广告,0=未点击、1=点击
第四列:dmp_id,营销策略编号,假设1为对照组,2为营销策略一,3为营销策略二
df_click.drop(columns='1',inplace=True)
df_click.columns = ['user_id','is_click','dmp_id']
df_click.head()
df_click.shape
df_click.describe()
数据清洗
# 数据类型检查
df_click.dtypes
# 缺失值检查
df_click.isnull().sum()
# 异常值检查:记录数>5且点击率=1的用户
df_random_click = df_click.groupby('user_id')['is_click'].agg(['mean','count']).reset_index()
df_random_click.columns = ['user_id','click_rate','total_count']
full_click = df_random_click[(df_random_click['click_rate'] == 1) & (df_random_click['total_count'] > 5)]
full_click
# 用户交叉检查
cross_user = df_click.groupby('user_id')['dmp_id'].nunique().reset_index()
cross_user.columns = ['user_id', 'group_count']
cross_user_id = cross_user[cross_user['group_count'] > 1]['user_id']
df_clean = df_click[~df_click['user_id'].isin(cross_user_id)]
df_clean.head()
样本容量检验
如果样本太小:
就算差异真实存在,也可能检验不出来(第二类错误↑)
P 值不显著,可能是“数据太少,不足以说明问题”
如果样本太大:
小小的无意义差异也会变成显著(P值小),浪费资源
易做出过度优化或上线错误决策
本次营销目标:以对照组点击率为基准,营销组广告点击率上升1%
# 对照组点击率
df_ctr_std = df_clean[df_clean['dmp_id'] == 1]['is_click'].mean()
print(f'对照组点击率是:{df_ctr_std *100:.2f}%')
# 实验组点击率2.34%,计算样本容量
from statsmodels.stats.power import NormalIndPower
from statsmodels.stats.proportion import proportion_effectsize
p1 = 0.0134 # 对照组点击率
p2 = 0.0234 # 实验组点击率(提升1%)
alpha = 0.05
power = 0.8
effect_size = proportion_effectsize(p1, p2)
analysis = NormalIndPower()
sample_size = analysis.solve_power(effect_size=effect_size, alpha=alpha, power=power)
print(f"每组所需样本量为:{round(sample_size)}")
并不能直接推出这个公式,但是只要知道即可:
- p2-p1差异越小,样本要越多才能发现它
- p 值越小(α 越严格),需要更多样本
- 检验功效越高(power越大),检出率高,也需要更多样本
print('对照组样本量:', df_clean[df_clean['dmp_id'] == 1].shape[0])
print('营销一组样本量:', df_clean[df_clean['dmp_id'] == 2].shape[0])
print('营销二组样本量:', df_clean[df_clean['dmp_id'] == 3].shape[0])
# 均满足条件
Z检验
# 观察每组点击率
print('对照组点击率:', df_clean[df_clean['dmp_id'] == 1]['is_click'].mean())
print('营销一组点击率:', df_clean[df_clean['dmp_id'] == 2]['is_click'].mean())
print('营销二组点击率:', df_clean[df_clean['dmp_id'] == 3]['is_click'].mean())
策略二满足点击率提升的最小要求,虽然一般情况策略一也最好验证,但是为了快捷计算,验证策略二既可
✨z检验使用情况:大样本前提(n>30),指标二项分布,独立双样本
零假设H0:策略无效
备择假设H1:策略有效
from statsmodels.stats.proportion import proportions_ztest
# 点击数
df_std_click = df_clean[df_clean['dmp_id'] == 1]['is_click'].sum()
df_test2_click = df_clean[df_clean['dmp_id'] == 3]['is_click'].sum()
clicks = [df_std_click, df_test2_click]
# 输入总样本数
df_std_total = df_clean[df_clean['dmp_id'] == 1].shape[0]
df_test2_total = df_clean[df_clean['dmp_id'] == 3].shape[0]
totals = [df_std_total, df_test2_total]
# 进行双尾 z 检验
z_stat, p_value = proportions_ztest(count=clicks, nobs=totals)
print(f"Z 统计量: {z_stat:.2f}")
print(f"P 值: {p_value:.4f}")
最终结论
P 值 ≪ 0.05,策略无效可能性太小,且提升幅度超过 100%,足以考虑上线营销策略二
三、ABtest简述
设计实验步骤
| 步骤 | 说明 |
|---|---|
| 确定目标指标 | 比如提升支付转化率、提高点击率等 |
| 确定实验组和对照组 | 尽量随机,保持人群结构一致 |
| 设定变更方案 | 比如更换券种、调整文案、改按钮颜色 |
| 收集实验数据 | 收集各组的关键指标,如点击率、支付金额等 |
| 统计检验显著性 | 用 T 检验、卡方检验等方式判断差异是否可信 |
| 结论与上线决策 | 如果实验组效果更好且显著,就上线新策略 |
样本容量计算
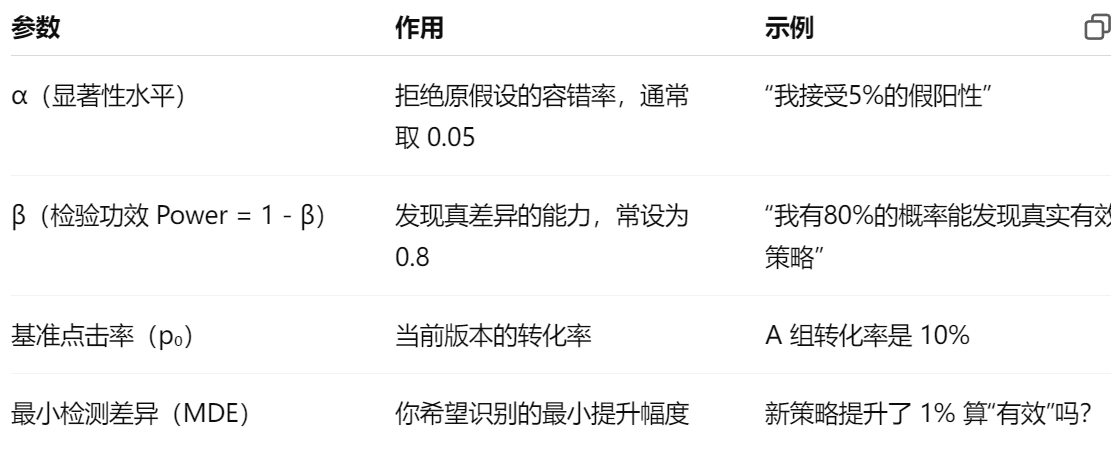
各参数含义:
- α(第一类错误):接受“策略明明无效却被误判为有效”的最大容忍概率,通常设为 0.05
- power(1-第二类错误):发现策略真正有效时,有能力识别出来的概率,通常设为 0.8,表示有 80% 的概率能识别出有效策略
各个检验运用
✅ 第一层:点击率(比例类指标)
如果你的指标是是否点击(0/1),或者转化率(如购买率),就是“二项分布”。
常用检验方法:
| 方法 | 说明 | 是否推荐 |
|---|---|---|
| ✅ z 检验 | 比较两个点击率的差异(大样本前提) | ✅ 标准做法 |
| ✅ 卡方检验(Chi-square) | 同样适用于分类变量,适合三组及以上 | ✅ 也可用 |
| ❌ t 检验 | 用于比较均值,不适合 0/1 数据 | ❌ 不推荐 |
✅ 第二层:连续值(比如订单金额、停留时间)
如果你的实验指标是数值型,比如:
- 用户下单金额
- 广告观看时长
就要换成下面的检验方式:
| 方法 | 说明 | 是否推荐 |
|---|---|---|
| ✅ t 检验(Student’s t-test) | 比较两个均值,适合小样本 | ✅ 常用 |
| ✅ Welch’s t 检验 | 方差不齐时更稳健 | ✅ 更严谨 |
| ❌ z 检验 | 不适合连续变量 | ❌ 不推荐 |
✅ 第三层:高级场景 / 多个指标
当你遇到以下复杂情况时,会使用更高级的方法:
| 场景 | 方法 | 用途 |
|---|---|---|
| 多个实验组 | Bonferroni 校正 / ANOVA / 多重检验 | 控制假阳性率 |
| 用户特征不均衡 | Logistic 回归 / 倾向评分 | 控制混杂变量 |
| 时序波动 | 分段检验 / 时间序列回归 | 控制时间干扰 |
| 多次转化行为 | 生存分析 / AUC / retention curve | 适合留存类分析 |
✅ 总结:
| 情况 | 推荐方法 |
|---|---|
| 两个组、点击率类指标 | ✅ z 检验 是首选 |
| 两个组、数值类指标 | ✅ t 检验 |
| 三个及以上组 | ✅ 卡方检验 / ANOVA |
| 有时间、用户画像等干扰因素 | 回归建模(Logistic / OLS) |
四、实验流程设计(简单例子)
1.业务背景
某电商平台首页,用户首次进入时会看到“猜你喜欢”推荐模块。为提升点击率,设计了三种文案风格用于 A/B/C 测试:
| 组别 | 文案风格 |
|---|---|
| A | 对照组,原始文案(例:为你推荐) |
| B | 个性化文案(例:Hi,xx!这是为你定制的好物) |
| C | 情绪型文案(例:错过这些后悔一整年!) |
2.指标设计
主要指标(核心):
- 点击率(CTR):点击人数 / 曝光人数
次要指标(辅助):
- 每人平均点击数
- 页面停留时间
3.假设设定
H₀:p_A = p_B(或 p_C)
H₁:p_A ≠ p_B(或 p_C)
使用 z 检验进行双尾检验,显著性水平 α = 0.05
4.样本量设计
α = 0.05
power = 0.8
对照组点击率 = 5%
期望提升 = 1%(提升到 6%)
计算得每组样本量约 2,500,总需样本约 7,500 人
5.分流策略
- 用户首次进入首页即随机分组(A/B/C)
- 分流逻辑保障每个用户只进入一个组
- 排除用户重复曝光、交叉文案情况
6.数据分析和检验
这种设计Z检验使用较多,用双尾z检验


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









