






一、项目背景
随着线上教育平台的发展,如何为每位用户智能推荐感兴趣的课程,成为平台提升用户活跃度和学习转化率的关键手段。本文使用某教育平台用户行为数据,基于协同过滤算法构建推荐系统,结合 Hive 思想分层处理数据,最终输出推荐结果。
二、数据介绍
本文基础数据是课程学习信息表:
study_information.csv【课程学习信息表】
| 字段名 | 含义 |
|---|---|
| user_id | 用户唯一标识,外键关联 users.csv |
| course_id | 课程 ID |
| course_join_time | 加入课程的时间 |
| learn_process | 课程学习进度 |
| price | 课程价格 |
三、数据分层存储
第一层 ODS层原始数据存储
创建数据库-上传数据到HDFS上-创建数据表-向数据表中装载数据。
-- 创建ods_prject数据库
CREATE DATABASE IF NOT EXISTS ods_project;
USE ods_project;
-- 创建【课程学习信息表】
CREATE TABLE IF NOT EXISTS ods_study_information (
user_id STRING,
course_id STRING,
course_join_time TIMESTAMP,
learn_process STRING,
price INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ('skip.header.line.count'='1');
-- 向【用户信息表】中装载数据
LOAD DATA INPATH '/data/ods/study_information.csv' INTO TABLE ods_study_information;
-- 检查数据是否存在
SELECT * FROM ods_study_information limit 10;
第二层 DWD层对ODS层做一定清洗工作
清洗study_information表:
- 将learn_process的进度提取,作为课程评分标准。
CREATE TABLE IF NOT EXISTS dwd_study_information (
user_id STRING,
course_id STRING,
course_join_time TIMESTAMP,
learn_process DOUBLE,
price INT
);
INSERT OVERWRITE TABLE dwd_study_information
SELECT
user_id,
course_id,
course_join_time,
CAST(
REGEXP_EXTRACT(learn_process, '([0-9]+)', 1) AS DOUBLE
)/100 AS learn_process, -- 提取百分数字符并转为数字
price
FROM ods_study_information
WHERE user_id IS NOT NULL;
第三层 DWS汇总所需数据
CREATE TABLE IF NOT EXISTS dws_user_course_progress AS
SELECT
user_id,
course_id,
learn_process
FROM dwd_study_information
WHERE user_id IS NOT NULL AND course_id IS NOT NULL;
四、协同过滤推荐
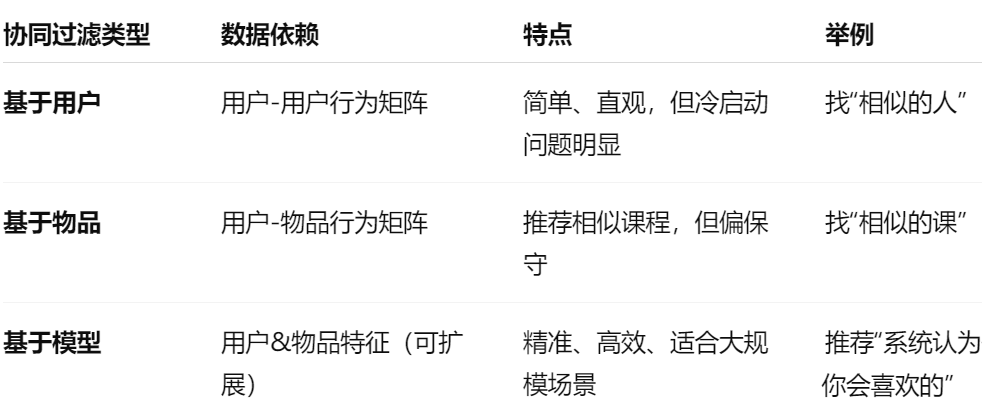
本例中使用基于物品的协同过滤,采用余弦相似度计算。具体解释:如果很多用户同时学习了课程A和课程B,且他们在A和B的学习行为(如学习进度)相似,那么A和B就被认为是相似课程,此后对未学习B,但学习A的用户,会优先推荐A。
相较于用户协同过滤,物品协同过滤不会因为用户快速增长导致计算代价巨大,而且物品的相似关系更加稳定,本例更加适用。
相似度计算
| 方法 | 说明 |
|---|---|
| 欧氏/曼哈顿距离 | 主要用于“数值型特征” |
| 余弦相似度 | 适用于高维稀疏向量(如课程学习进度、评分矩阵),忽略绝对值差异 |
| 皮尔逊相关系数 | 衡量两个变量的线性相关程度,考虑值的均值中心化,对偏移不敏感。适合评分数据为连续值时使用,比如 1~5 的用户评分。 |
| Jaccard 相似度 | 比较两个集合的交集与并集比,适用于二值型数据(如是否点过赞、是否收藏、是否注册过课程) |
本例将推荐系统可用的三个计算方式都进行说明。
余弦相似度

手算示意原理
构造一个用户-课程矩阵
| user_id | course_A | course_B | course_C |
|---|---|---|---|
| 1 | 0.9 | 0.1 | 0.0 |
| 2 | 1.0 | 0.3 | 0.4 |
| 3 | 0.0 | 0.2 | 0.5 |
课程AB的相似度
向量:
course_A = [0.9, 1.0, 0.0]
course_B = [0.1, 0.3, 0.2]
-
点积:0.9∗0.1+1.0∗0.3+0.0∗0.2=0.09+0.3+0=0.39
-
模长:
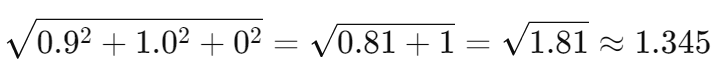
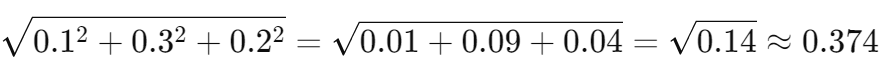
-
相似度:0.39/(1.345*0.374)=0.775
课程AC的相似度 同理得:0.464
课程BC的相似度 同理得:0.921
高中知识,弄这一块复习了很久。。。
各课程相似度
| course_A | course_B | course_C | |
|---|---|---|---|
| course_A | 1.000 | 0.775 | 0.464 |
| course_B | 0.775 | 1.000 | 0.921 |
| course_C | 0.464 | 0.921 | 1.000 |
结论
- 用户学习课程B后更推荐课程C而非课程A;
- 以用户1为例,其对C课程的推荐得分为(0.90.464+0.10.921)/(0.464+0.921)=0.368,所有课程会有可比较的推荐分。
PYTHON代码
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 读取已经清洗好的CSV(从 Hive 导出)
df = pd.read_csv('cleaned_study_information.csv')
# 1. 创建 用户-课程 学习进度矩阵
pivot = df.pivot_table(index='user_id', columns='course_id', values='learn_process_num').fillna(0)
# 2. 转置为 课程-用户 矩阵,计算课程间相似度(物品协同过滤)
course_user_matrix = pivot.T
similarity_matrix = pd.DataFrame(
cosine_similarity(course_user_matrix), # cosine_similarity:将每行当作一个向量计算余弦相似度
index=course_user_matrix.index,
columns=course_user_matrix.index
)
# 3. 模拟给用户 1 推荐新课程:先拿到用户 1 学过的课程
user_id = '1'
user_vector = pivot.loc[user_id]
# 用户未学习的课程
unlearned_courses = user_vector[user_vector == 0].index
# 推荐分 = 用户已学课程的进度 × 与未学课程的相似度
recommend_scores = {}
for course in unlearned_courses:
# 所有已学习课程与目标课程的相似度
sim_courses = similarity_matrix[course]
learned = user_vector[user_vector > 0]
# 推荐分 = ∑(进度 × 相似度) / ∑(相似度)
score = (learned * sim_courses[learned.index]).sum()
sim_sum = sim_courses[learned.index].sum()
recommend_scores[course] = score / sim_sum if sim_sum != 0 else 0
# 4. 输出推荐结果
recommend_df = pd.DataFrame.from_dict(recommend_scores, orient='index', columns=['recommend_score'])
recommend_df = recommend_df.sort_values(by='recommend_score', ascending=False)
print(recommend_df)
Jaccard相似度概述
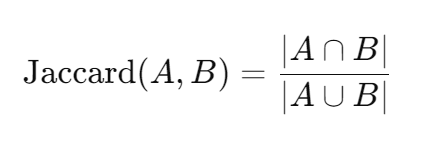
| user_id | course_A | course_B | course_C | course_D | course_E |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 1 |
| 2 | 1 | 0 | 1 | 0 | 1 |
| 3 | 0 | 1 | 0 | 1 | 0 |
| 4 | 1 | 0 | 1 | 0 | 1 |
| 5 | 0 | 1 | 0 | 0 | 1 |
用户二推荐B还是D,相似度计算如下:
B\A:1/5=0.2
B\C:0/5=0
B\E:2/5=0.4
B的推荐分:(0.21+01+0.4*1)/(0.2+0.4)=1
D\A:0/4=0
D\C:0/3=0
D\E:0/5=0
D的推荐分:0
此处数据太少,所以才会出现0和1的极端值。
皮尔逊相似度概述

| user_id | course_A | course_B | course_C |
|---|---|---|---|
| 1 | 0.9 | 0.1 | 0.0 |
| 2 | 1.0 | 0.3 | 0.4 |
| 3 | 0.0 | 0.2 | 0.5 |
因为皮尔逊是衡量线性相关,所以只有课程AB在同一用户下都有有效观测值才有意义,这就意味着用户3不参与皮尔逊相似度计算。
course_A: [0.9, 1.0]
course_B: [0.1, 0.3]
Ā = (0.9 + 1.0) / 2 = 0.95
B̄ = (0.1 + 0.3) / 2 = 0.2
Pearson(A, B)=[(0.9−0.95)(0.1−0.2)+(1.0−0.95)(0.3−0.2)]/0.0707*0.1414=1.0
五、写在最后
目前推荐系统常用的是矩阵分解而非协同过滤,之所以完成这个项目是因为刚接触数据分析就是这个,因为想有输出所以查找资料发现了矩阵分解,但协同过滤写了过半,不能放弃,就有了这篇文章。
协同过滤的主要缺点:协同过滤无法将两个物品相似这一信息推广到其他物品的相似性计算上。这就导致了一个比较严重的问题:推荐结果的头部效应较明显,可扩展性很差;即热门的物品具有很强的头部效应,容易跟大批物品产生相似性;而尾部的物品由于特征向量稀疏, 很少与其他物品产生相似性,导致很少被推荐。
协同过滤优点是可解释性很高而且适合入门,我将在进入数分行业后深入矩阵分解算法,这里只做简单提及。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









