







TDH中distinct与groupby的操作分析
相同数量级的计算,为什么groupby 会比distinct快
select count(1)
from
(
select cust_isn
from
database.table
group by
cust_isn
)
select count(distinct(cust_isn))
from
database.table;
distinct的操作花费24s , groupby的操作花费1s
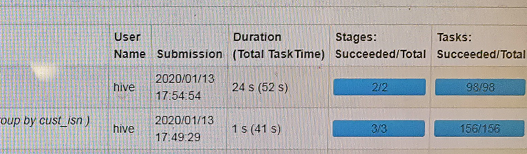
在这里插入图片描述
groupby的DAG图
两个shuffle阶段
最后一个节点花费 1s

dinstinct的DAG图
一个shuffle阶段
最后一阶段花费 24秒

原因总结:
虽然groupby比dinstinct多一个shuffle操作, 但是由于 groupby有一个预计计算的task, 导致 groupby要更快















 3651
3651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









