







最近做人脸识别遇到了这样一个问题,需要遍历orl_faces文件夹下的所有照片,并将其路径名写入到一个文本文件中。
上网看了好多的博客,发现代码不是不好使就是收费。特开此贴,防止自己忘记也能帮助网友。
一共两种方法;
法一:doc命令确实生成了这样的文件,具体方很多,就三个命令即可。看图。
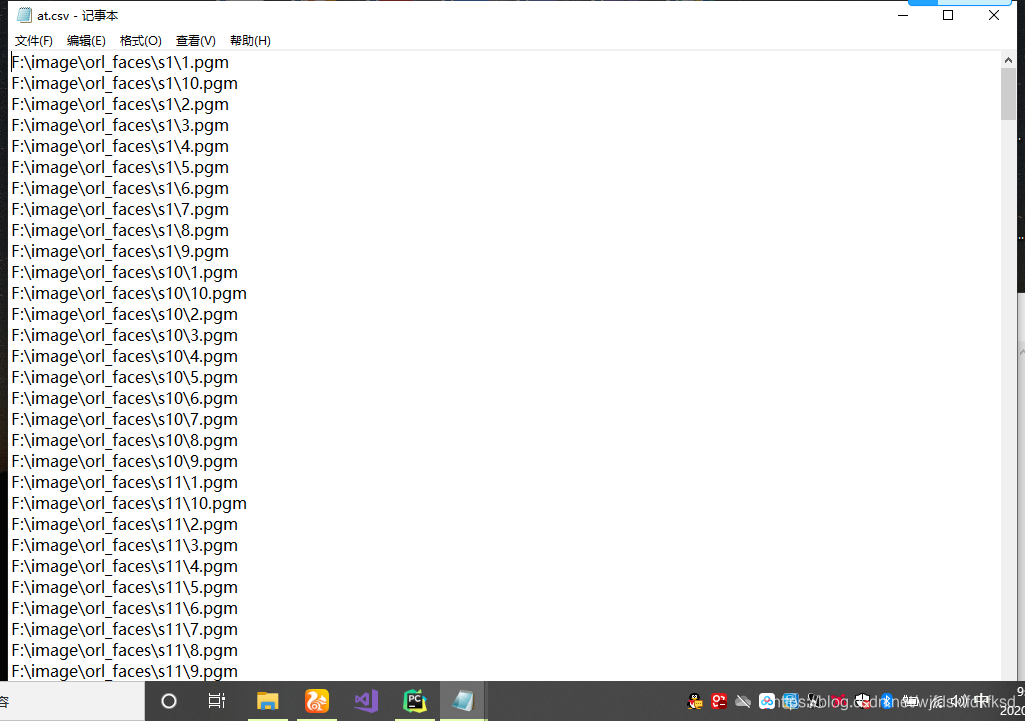
法二:由于python强大的数据处理功能,使用python完成此功能。

现在附上代码,希望对大家有帮助。
import os
filelist = os.listdir('F:/image/orl_faces') #将该路径下的orl_faces文件中的所有文件夹的名称形成一个列表1
txt=open('F:/image/filename.txt','w') #打开filename.txt文件,若该文件不存在则在对应路径下创建该文件
for i in filelist: #遍历列表1
f1=os.listdir('F:/image/orl_faces/'+i) #将orl_faces文件下的例如s1文件中的所有图片的名称生成一个列表2
for j in f1: #遍历列表2
txt.write('F:/image/orl_faces/'+i+'/'+j+';'+i.replace('s','')+'\n') #将列表2中的文件名称写入到txt文件中
txt.close();PS:需要将路径名改成你的路径名,并且文件夹里面不能有其他格式的文件。















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









