






本篇文章仅用于分享,非官方教程,仅供参考。欢迎大佬指正。
一.绪论
在现代软件开发中,数据库是存储和管理数据的重要工具。无论是小型应用程序还是大型企业级应用程序,都需要使用数据库来存储和管理数据。在数据库中,表是一种非常重要的数据结构,用于存储和管理数据。但是,对于许多人来说,数据库建表的底层原理并不十分清楚。本文将以miniob为例,来具体查看数据库建表的底层代码,帮助您更好地理解数据库的工作方式。
二.源码分析
1.通过gdb调试工具,调试miniob,初步了解create_table()的流程
打开虚拟机,打开终端切换到“miniob/build_debug” 目录下执行命令启动miniob(oceanbase为了方便学习数据库内核,剥离出一个阉割的数据库内核)。
./bin/observer -f ../etc/observer.ini -P cli
另外打开一个终端执行命令启动gdb调试工具
gdb -p `pidof observer`
通过gdb在create_table()函数打上断点->b create_table()。然后就在miniob里面编写建表的sql语句并回车执行。因为只是用来学习,没有库或者表空间的概念(可能,我没找到对应的源码,执行建库语句也会报错)。
(gdb) break create_table
miniob > create table test4(i int ,b int,c int);
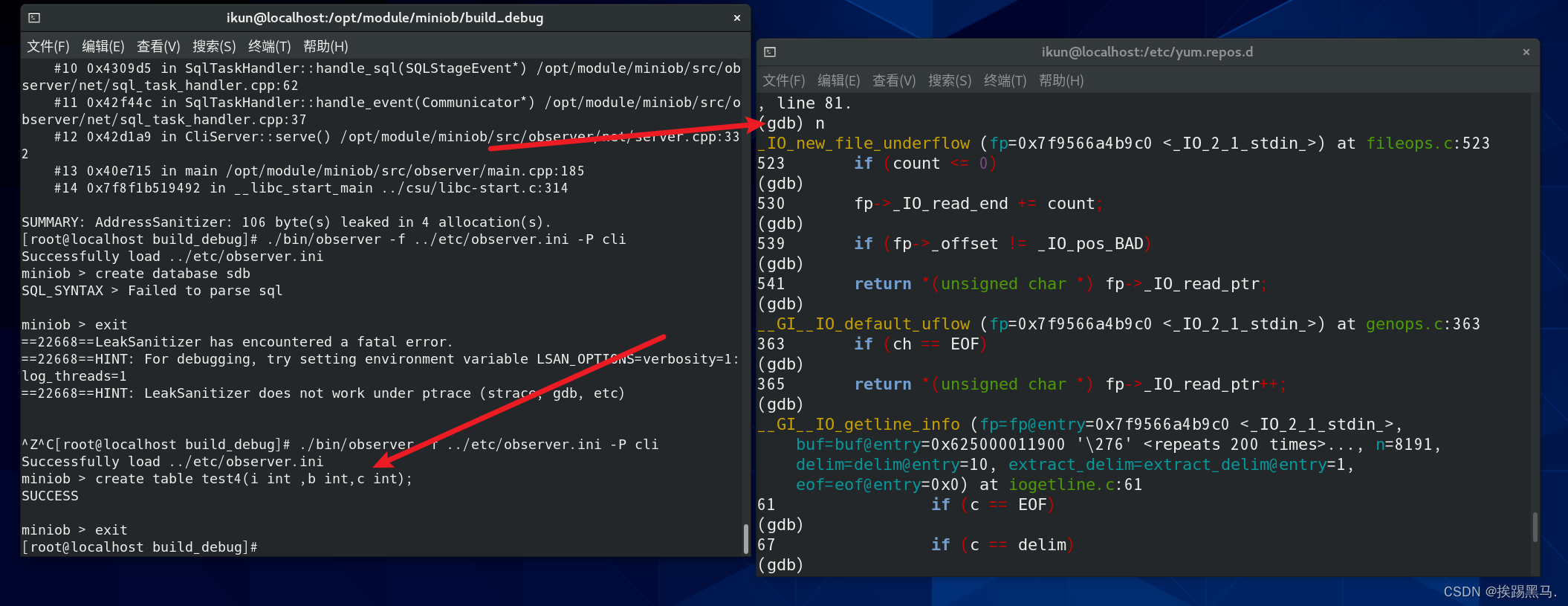
图片是后补的,正常执行是没有SUCCESS。
1.读取stdin输入流中数据,即在miniob运行窗口内输入的文字。
从图中左边gdb给出的调试信息可以看出,数据库先要读取文件中的数据,这里的函数都是关于stdin文件I/O相关的一些底层操作。
这里有一些关键点(再具体的原理,就是c语言的底层和汇编了):
-
IO_new_file_underflow: 当从文件中读取字符且缓冲区为空时,此函数被调用以从文件中填充缓冲区。它检查是否还有字符可以读取(count是否大于0),并更新文件指针的读取结束位置(_IO_read_end)。 -
__GI__IO_default_uflow: 当需要单个字符但缓冲区为空时,此函数被调用。它首先调用IO_new_file_underflow(或类似的底层函数)来确保缓冲区有数据,然后返回下一个字符并更新读取指针(_IO_read_ptr)。 -
__GI__IO_getline_info: 这个函数尝试从文件指针(fp)指向的文件中读取一行,直到遇到指定的分隔符(在这里是换行符\n,ASCII码为10)或达到最大长度(在这里是8191字节)。
从调试输出来看,程序似乎正在正常地从stdin读取数据,并且正在处理读取到的每个字符。当读取到分隔符(在这里是换行符)或达到缓冲区末尾时,它将停止读取并返回已读取的字符数。
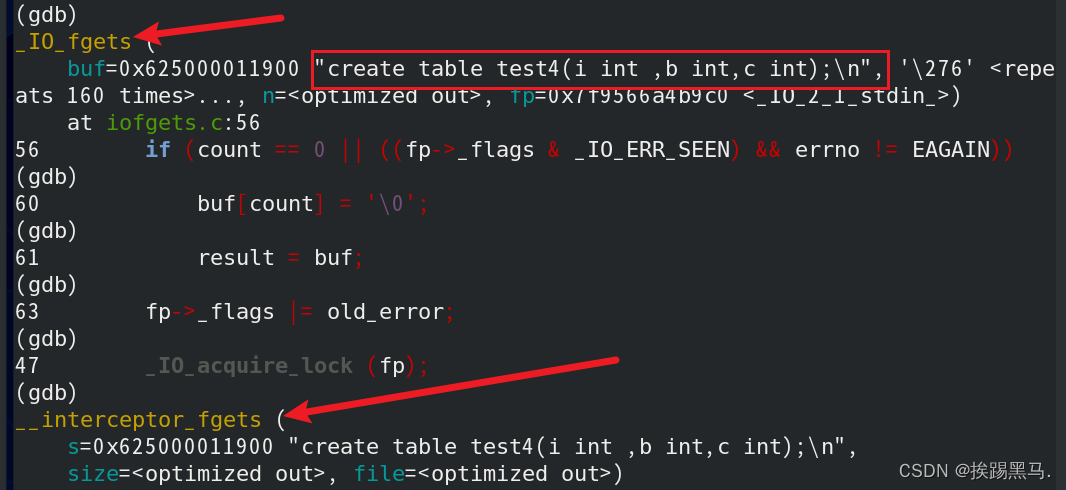
以上函数均为c语言的库函数。
2.简单的判断命令格式(是否为空,是否为退出)后将命令行读到的信息存入到会话(和客户段交互)事件对象中
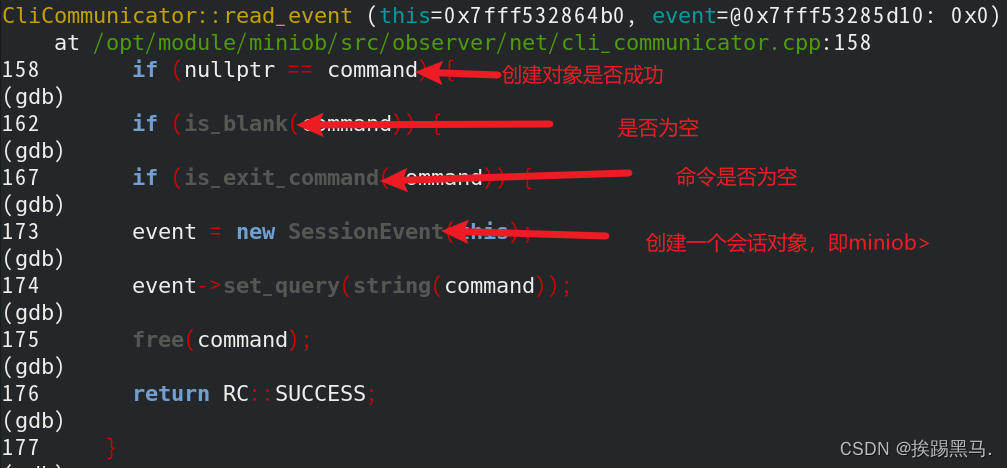
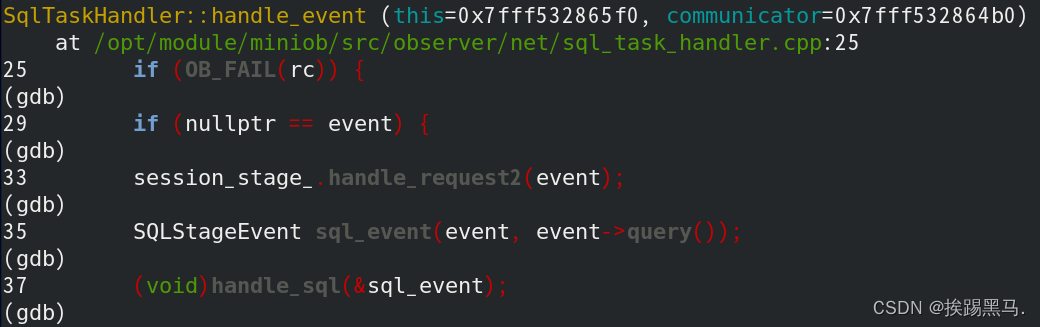
1.session_stage_.handle_request2(event);//将指定会话设置到线程变量里,设置当前正在处理的请求。原理为设置指针。
2.我们重点看一下(void)handle_sql(&sql_event);//这里为sql解析,词法分析,语法分析。内容很多本章省略,以后单个分析。
RC SessionStage::handle_sql(SQLStageEvent *sql_event)
{//query->查询 cache->缓存 stage->阶段
RC rc = query_cache_stage_.handle_request(sql_event);//空实现
if (OB_FAIL(rc)) {
LOG_TRACE("failed to do query cache. rc=%s", strrc(rc));
return rc;
}rc = parse_stage_.handle_request(sql_event);//parse->解析
if (OB_FAIL(rc)) {
LOG_TRACE("failed to do parse. rc=%s", strrc(rc));
return rc;
}rc = resolve_stage_.handle_request(sql_event);//resolve->解决
if (OB_FAIL(rc)) {
LOG_TRACE("failed to do resolve. rc=%s", strrc(rc));
return rc;
}rc = optimize_stage_.handle_request(sql_event);//optimzie->优化
if (rc != RC::UNIMPLENMENT && rc != RC::SUCCESS) {
LOG_TRACE("failed to do optimize. rc=%s", strrc(rc));
return rc;
}rc = execute_stage_.handle_request(sql_event);//execute->执行
if (OB_FAIL(rc)) {
LOG_TRACE("failed to do execute. rc=%s", strrc(rc));
return rc;
}return rc;
}
3.将真正的建表函数加入到执行计划中

4.执行并输出结果
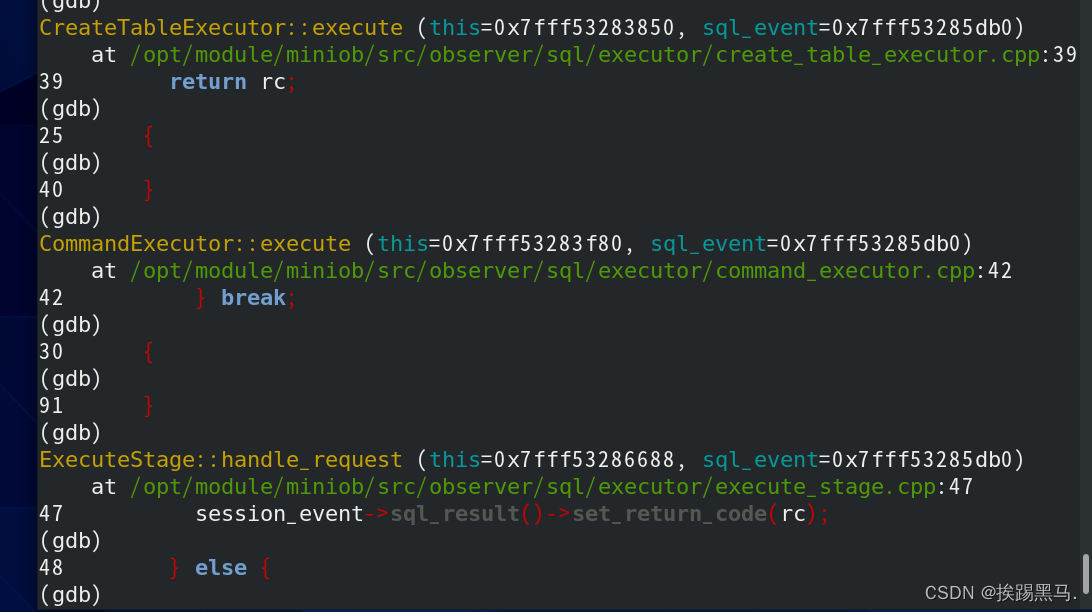
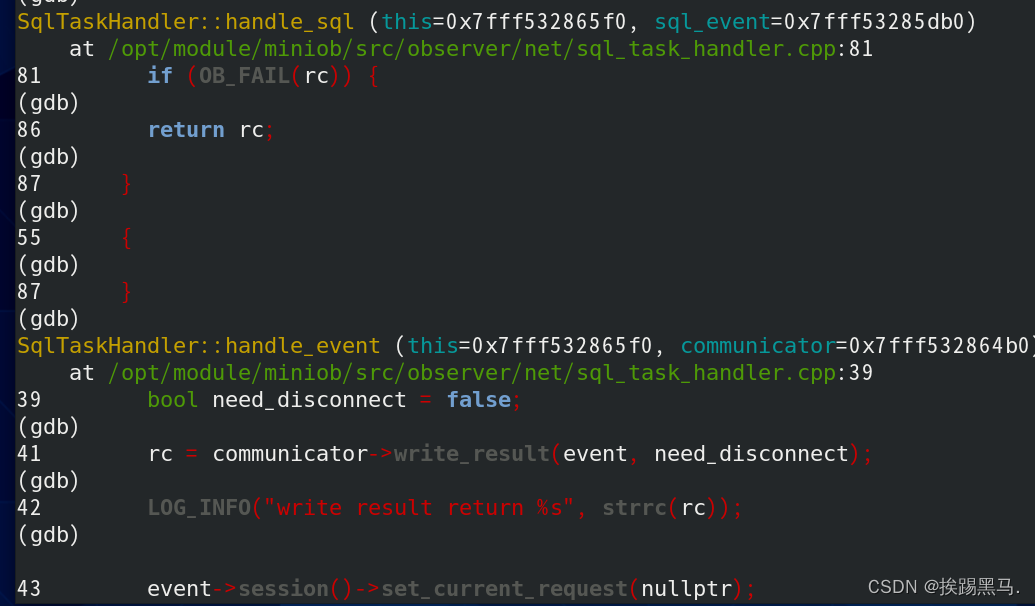
到这里建表的流程就全部结束了,我们简单回看一下程序都做了什么,通过读取标准输入流<stdin>获取到我们在miniob里输入sql语句,并做了简单的处理(判断合法性,加入线程),处理sql(告诉程序那些是操作符如:create,那些是参数如表名 test4),跳转到对应的具体操作(这里是create_table)将操作生成一个执行计划并加入到执行队列里,通过执行器执行完成建表操作,输出日志和SUCCESS并准备好重新接受输入(miniob>)。
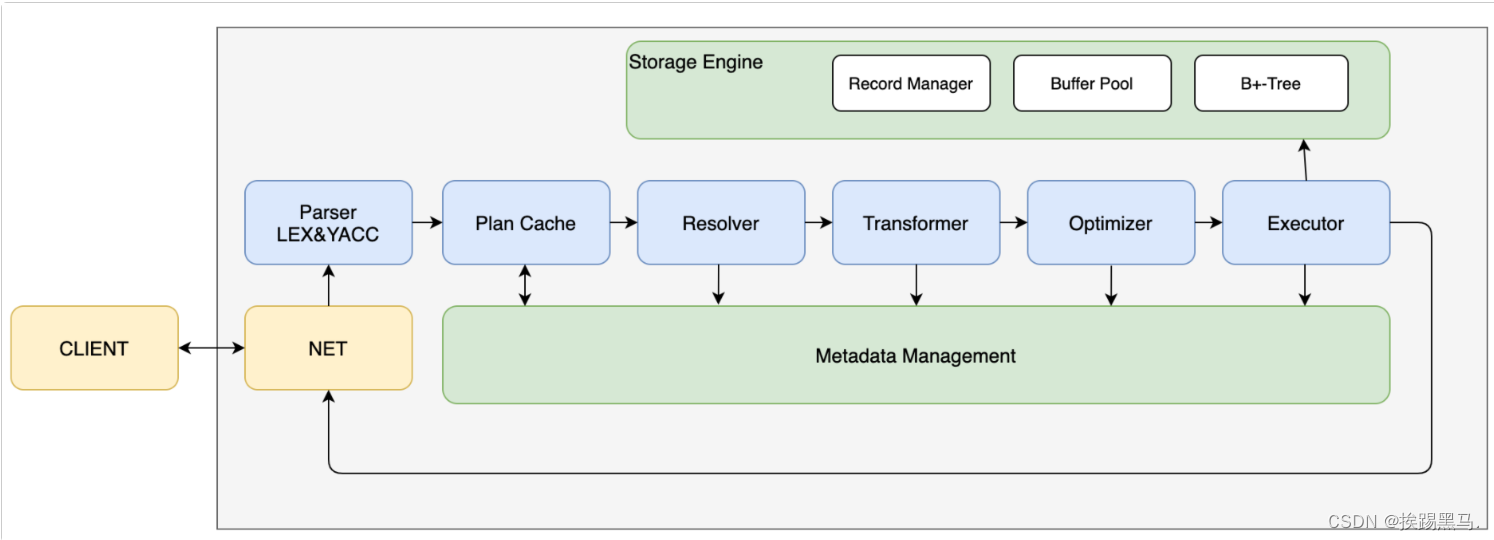
2.关于create_table()详细解析
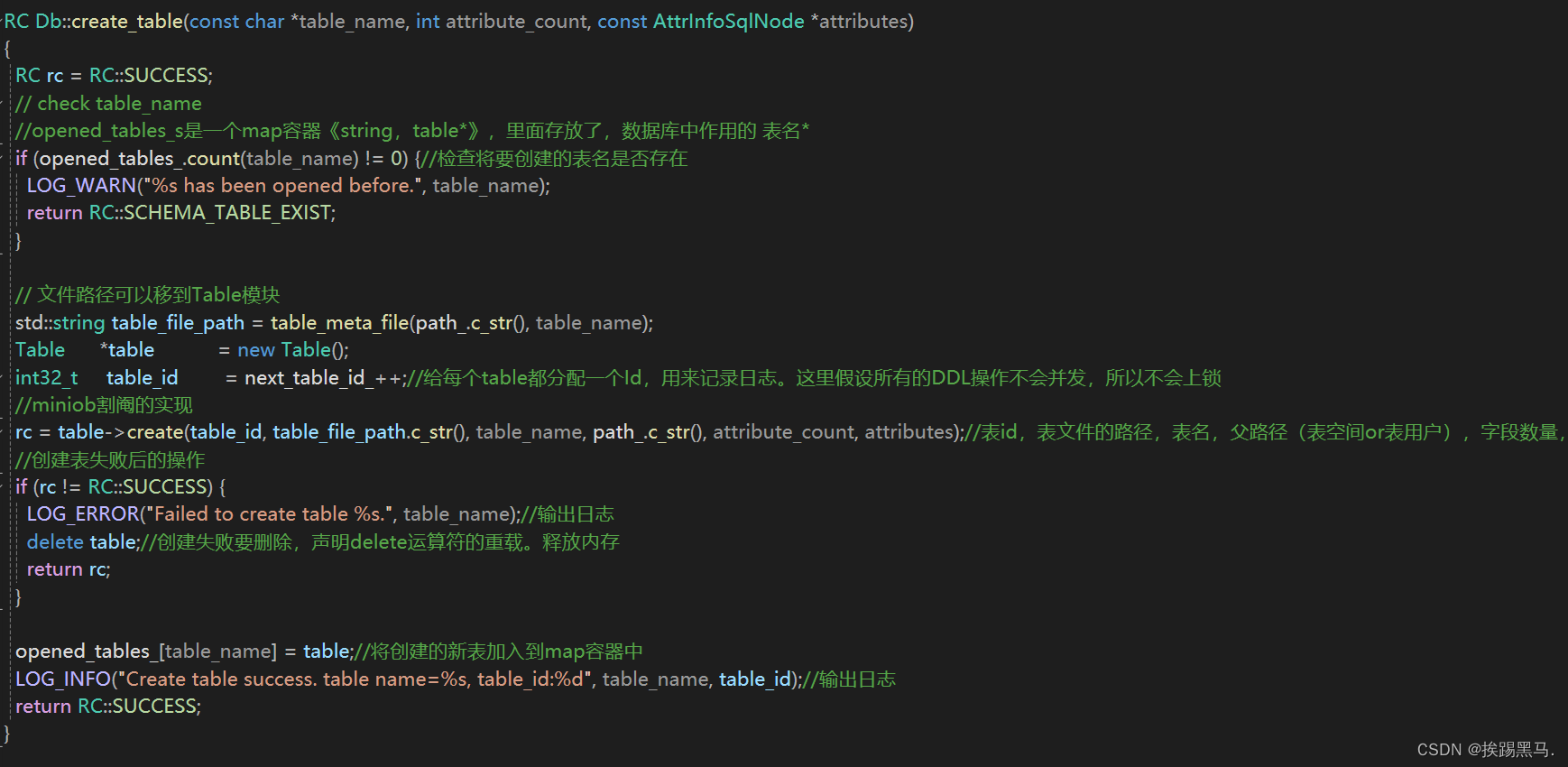
/opt/module/miniob/src/obsever/storage/db/db.cpp
create_table()
/opt/module/miniob/src/obsever/storage/table/table.cpp
table.create()
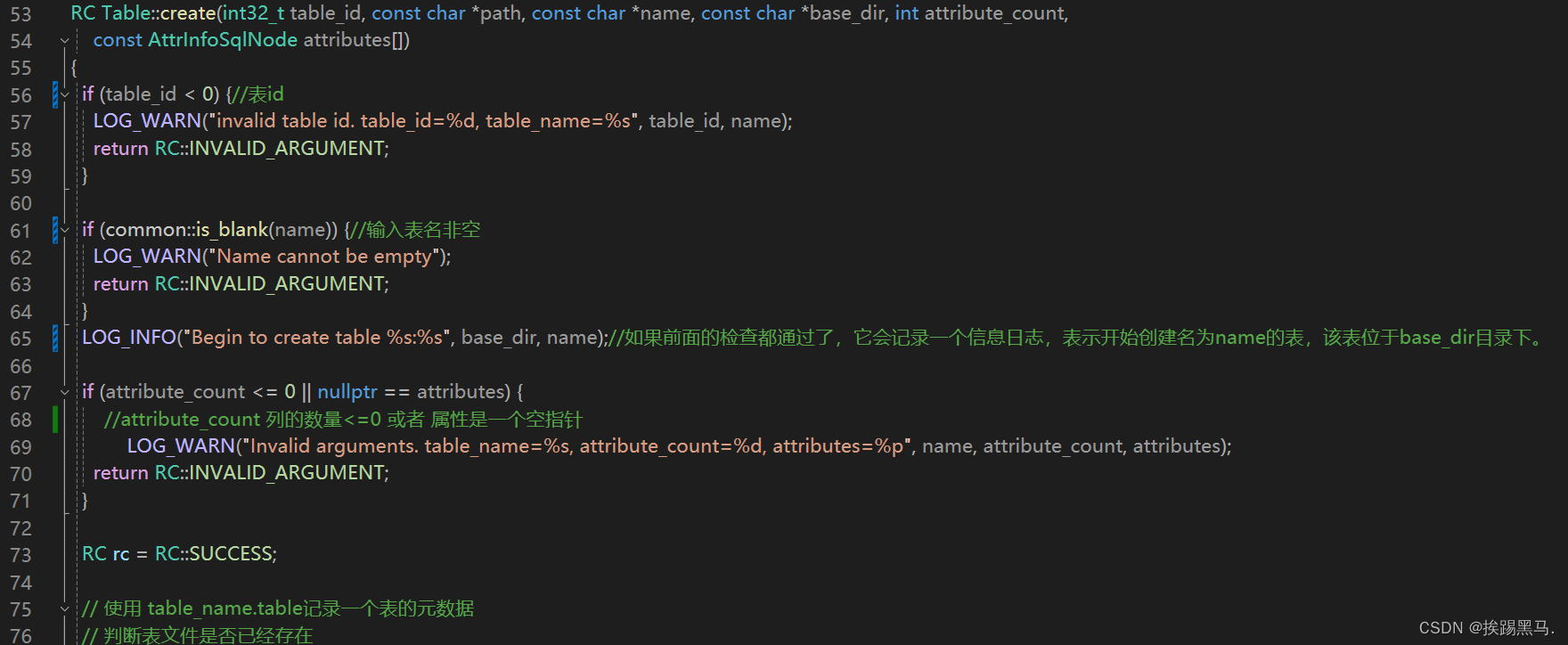
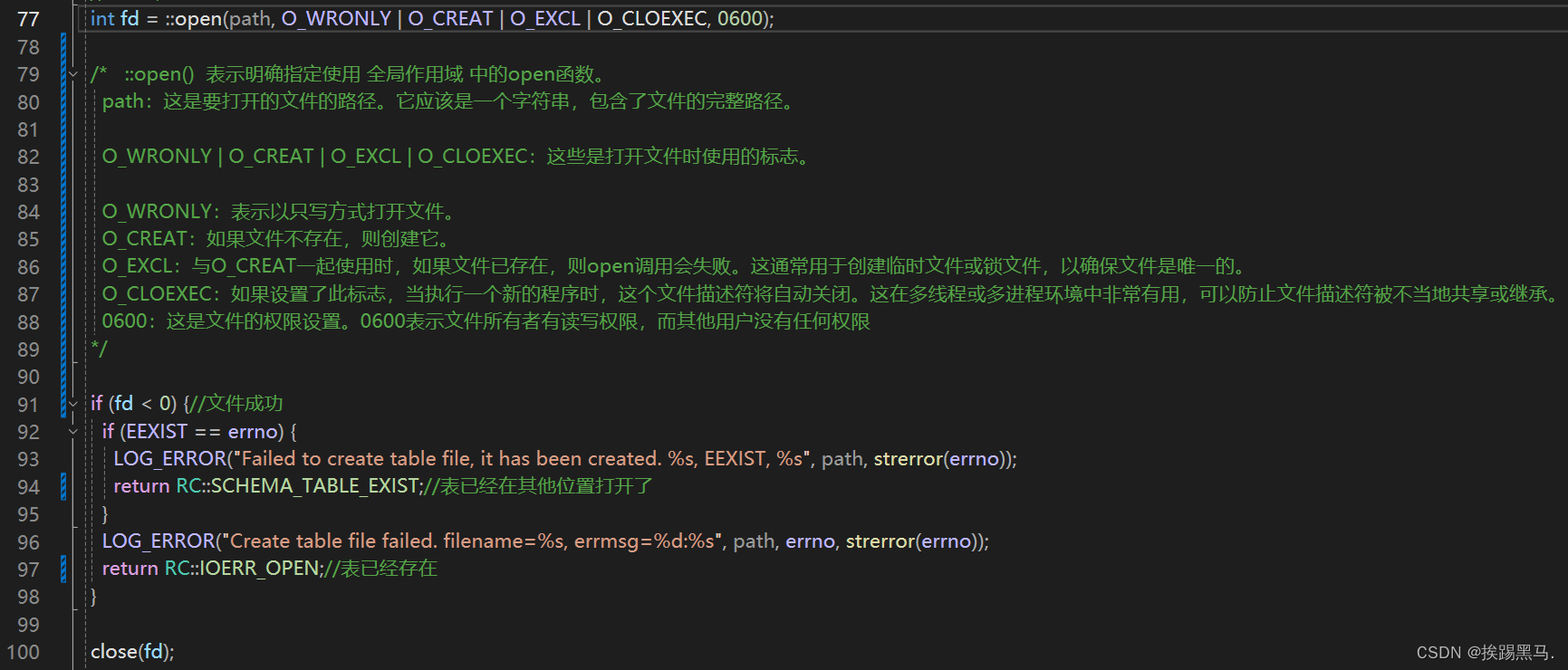
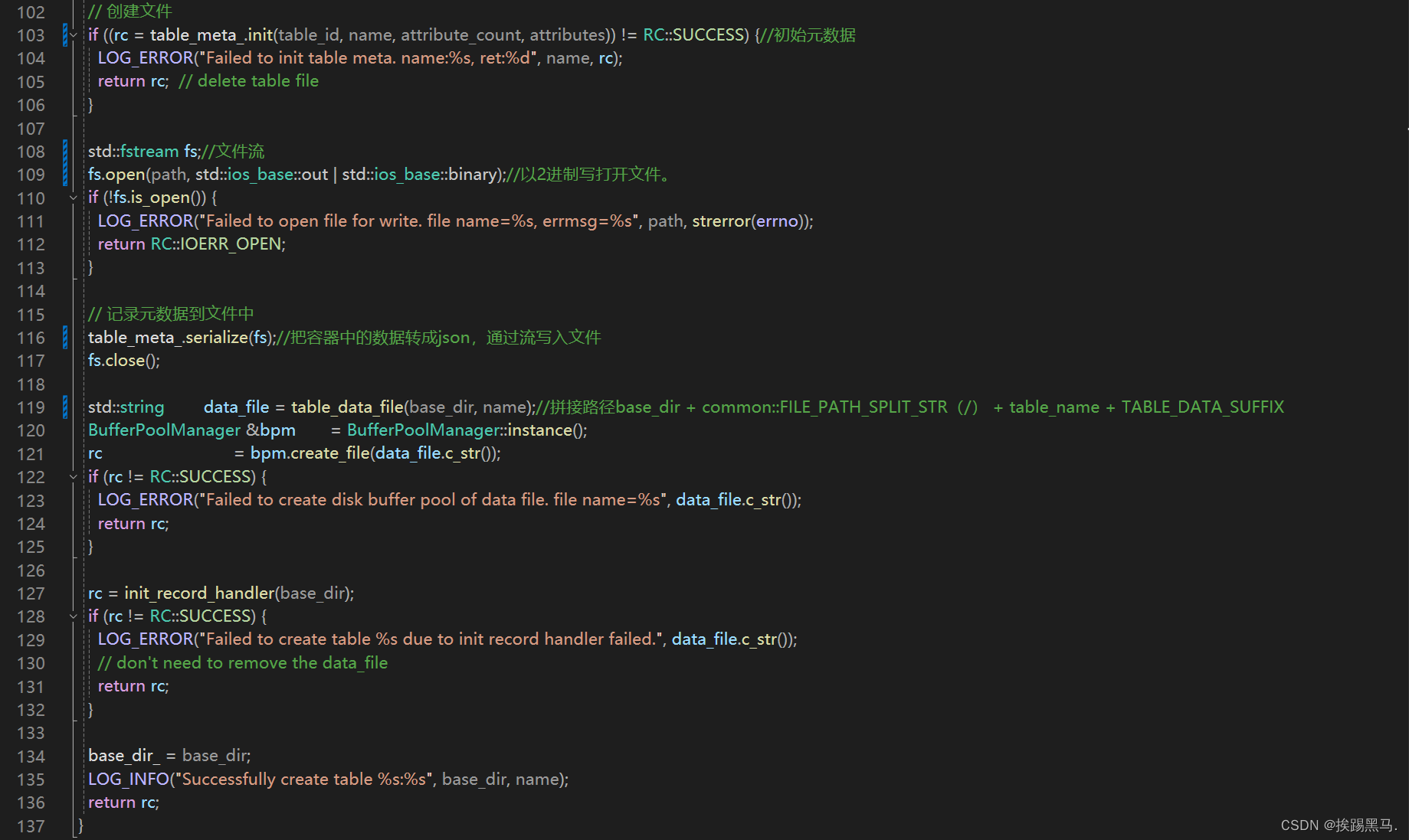
/opt/module/miniob/src/obsever/storage/table/table_meta.cpp
table_meta.init()->用于初始化表的元数据:表名,字段名,字段的数据类型,约束。
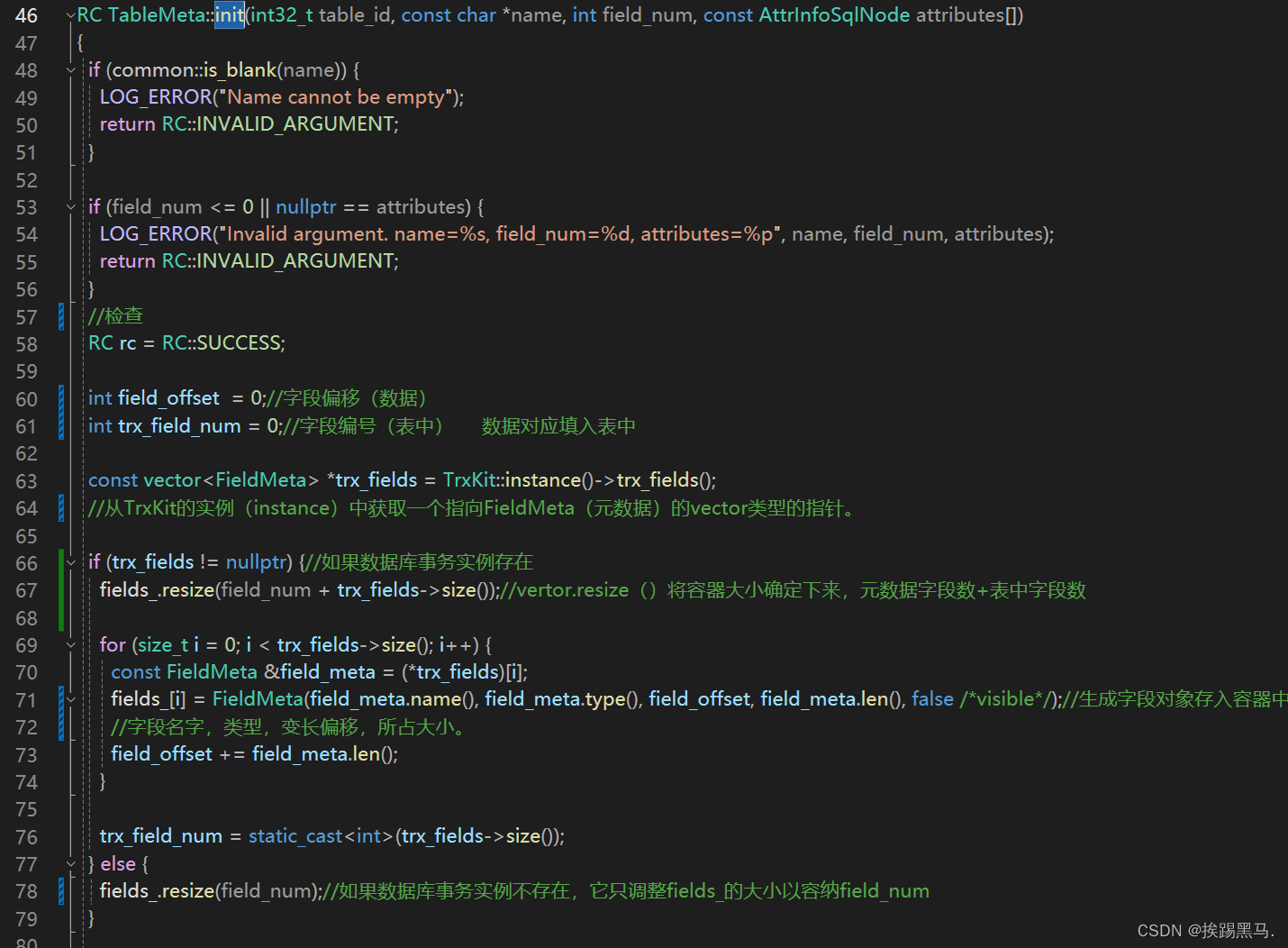
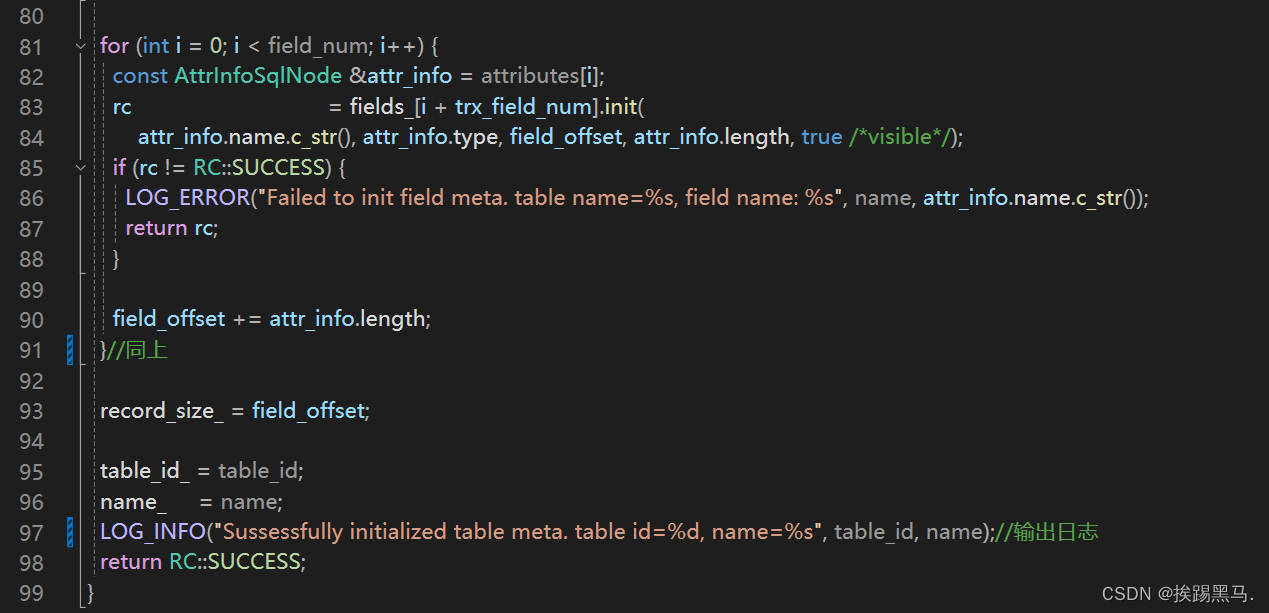
/opt/module/miniob/src/obsever/storage/table/table_meta.cpp
tablemeta.serialize()->将元数据转成json格式。
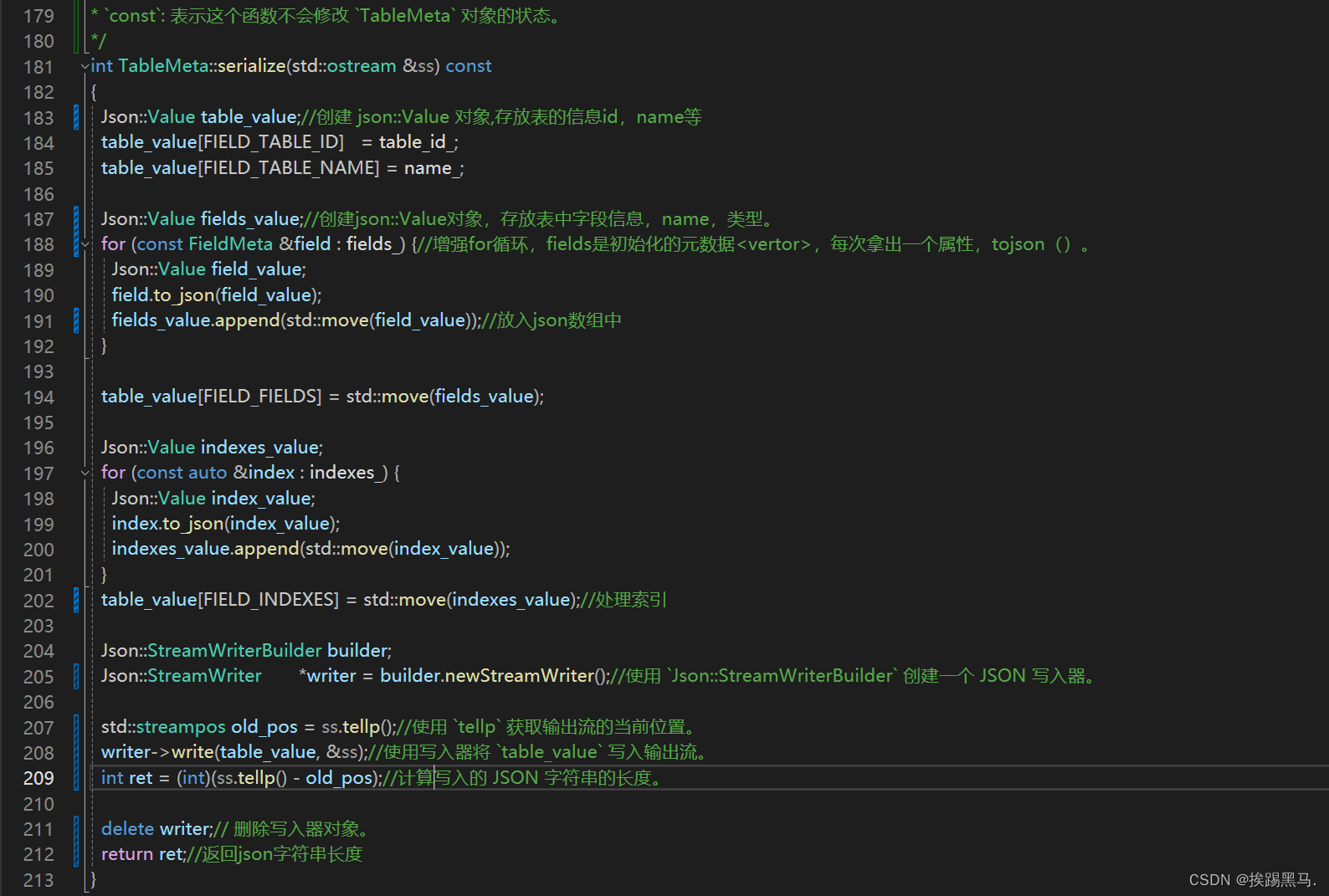
/opt/module/miniob/src/obsever/storage/buffer/disk_buffer_pool.cpp
bpm.create_file()->写入文件操作
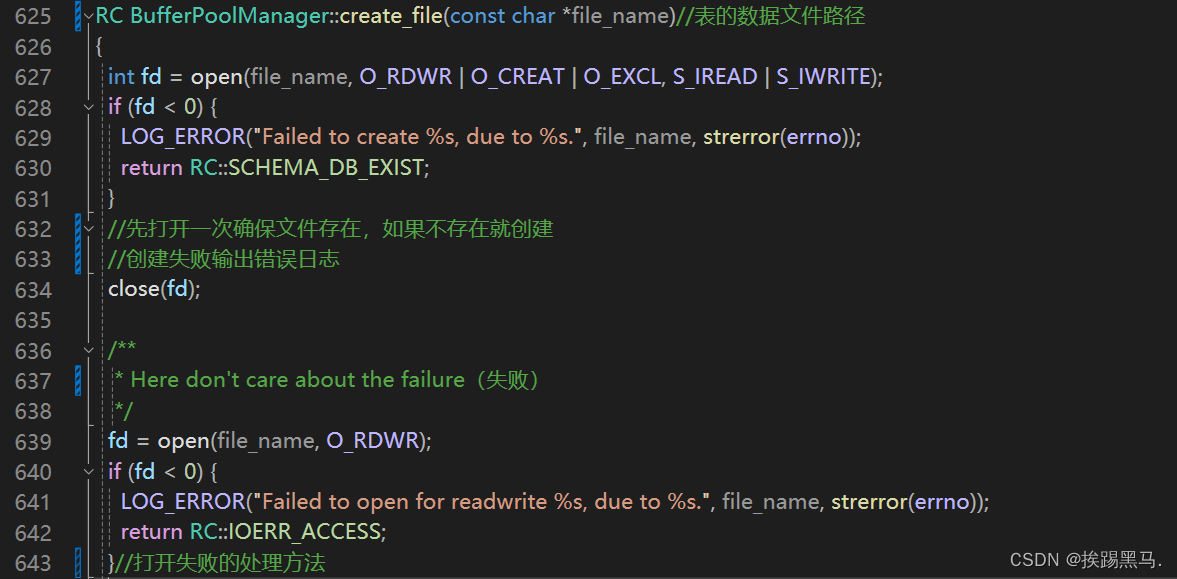
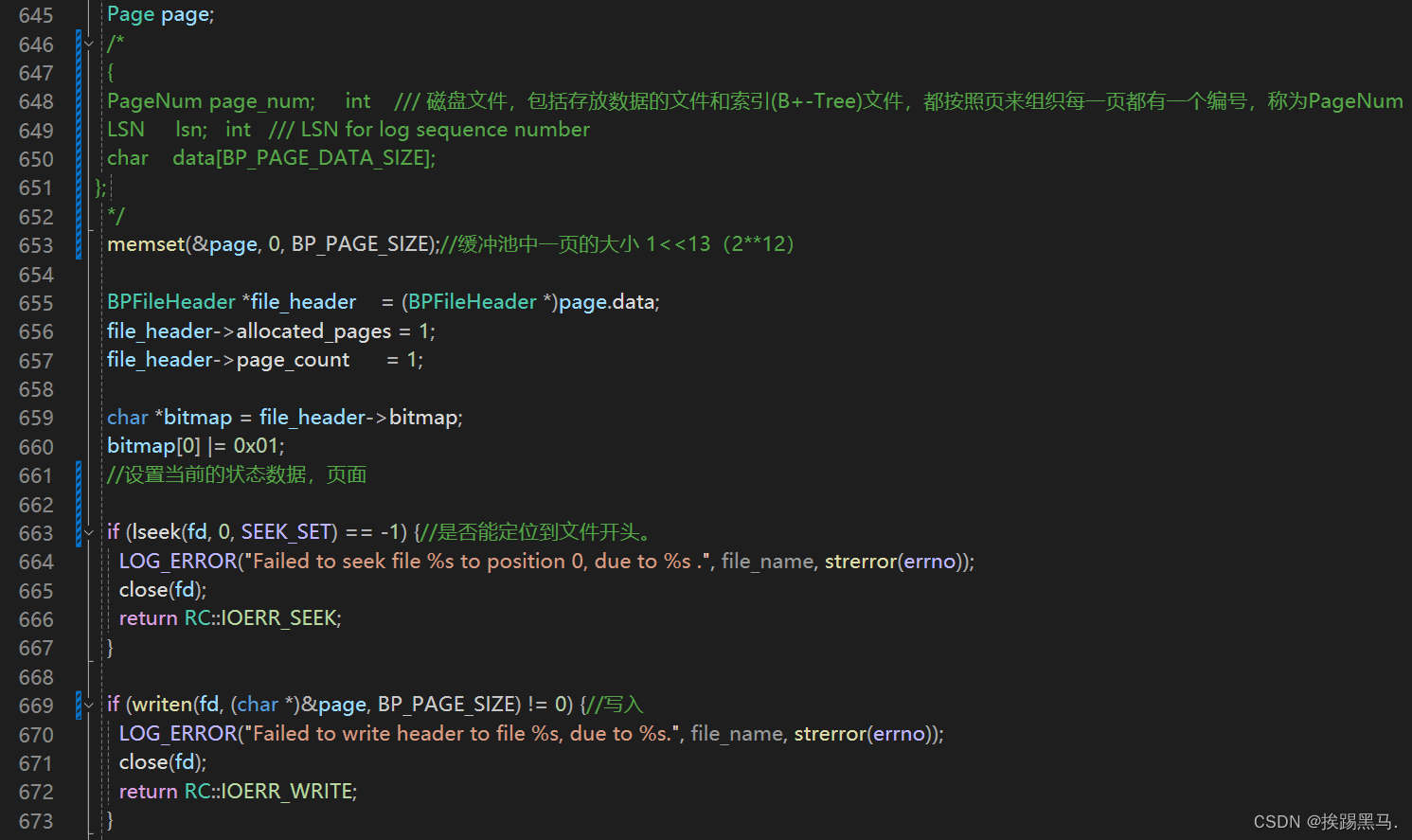
用对象来表示函数调用关系就是,Db->table->table_meta->buffer。
三.总结
在数据库内核解析sql语句成功后:调用Db::create_table()
调用table::create()
通过table_meta对象解析元数据
创建元数据信息文件
创建表文件
读到内存中

















 4181
4181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









