









一、简介
minio提供高性能、兼容S3的对象存储,适合存储非结构化数据,如视频、图片、日志文件、备份数据等,文中主要介绍minio中几个关键流程。
二、名词解释
- 擦除集(Erasure Set):是指一组纠删码集合,最大为32个驱动器,纠删码作为一种数据冗余技术相比于多副本以较低的数据冗余度提供足够的数据可靠性。擦除集中包含数据块与校验块,并且随机均匀的分布在各个节点上
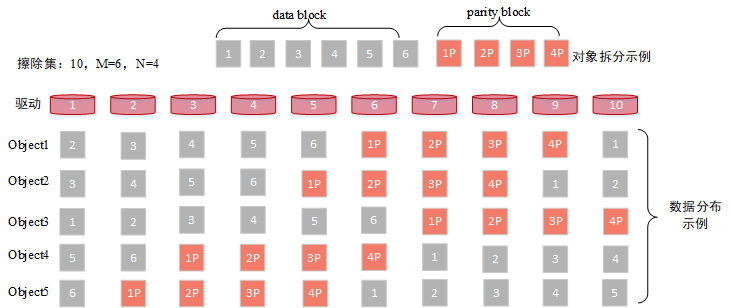
如图所示,假定擦除集中包含10个驱动(磁盘),则会组成一个6+4的纠删码集合,用户上传一个6M大小的对象,则会对其先拆分成6个1M大小的数据块,然后根据纠删码计算得到4个1M大小的校验块,一共10M数据,随机的分布在磁盘中
- 服务器池(Server Pool): 由一组MinIO节点组成一个存储池,池子中的所有节点以相同的命令启动,如图所示,pool池子由3个节点和6个驱动,共18个驱动器组成9+9的擦除集;池子中可能会包含多个擦除集
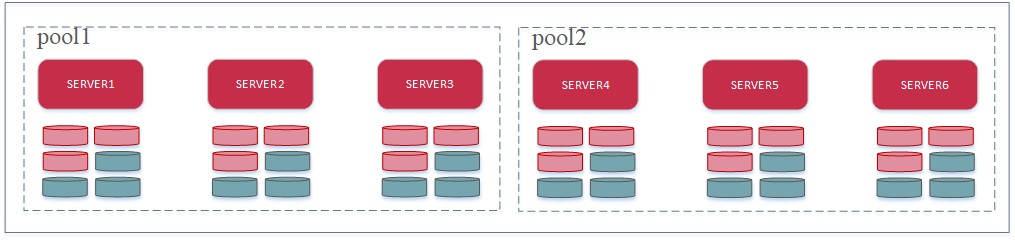
- 簇(cluster):由多个服务器池组成簇,如图所示,该簇中有两个池子。
三、核心流程
文中主要介绍上传、下载、删除、巡检等核心流程
3.1 数据上传
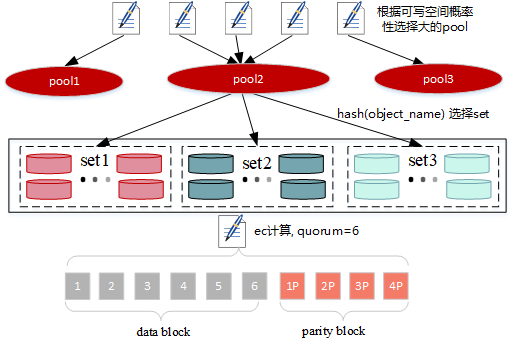
数据上传主要分以下几个流程(如图所示):
- 选择服务器池
- 选择擦除集
- ec计算
- 数据写入
3.1.1 选择pool
源码在
cmd/erasure-server-pool.go中的PutObject方法
- pool只有一个,直接返回
- pool有多个,这里分两步:
- 第一步会去查询之前是否存在此数据(bucket+object),如果存在,则返回对应的pool,如果不存在则进入下一步;
- 第二步根据object 哈希计算落在每个pool的set单元,然后根据每个pool对应set的可用容量进行选择,会高概率选择上可用容量大的pool
3.1.2 选择set
源码在
cmd/erasure-sets.go中的PutObject`方法
其实在选择pool的时候已经计算过一次对应object会落在那个set中,这里会有两种哈希算法:
- crcHash,计算对象名对应的crc值 % set大小
- sipHash,计算对象名、deploymentID哈希得到 % set大小,当前版本默认为该算法
3.1.3 上传
源码在
cmd/erasure-object.go中的PutObject方法
3.1.3.1 确定数据块、校验块个数及写入Quorum

- 根据用户配置的
x-amz-storage-class值确定校验块个数parityDrives- RRS,集群初始化时如果有设置
MINIO_STORAGE_CLASS_RRS则返回对应的校验块数,否则为2 - 其他情况,如果设置了
MINIO_STORAGE_CLASS_STANDARD则返回对应的校验块数,否则返回默认值 -
Erasure Set Size Default Parity (EC:N) 5 or fewer EC:2 6-7 EC:3 8 or more EC:4
- RRS,集群初始化时如果有设置
parityDrives+=统计set中掉线或者不存在的磁盘数,如果parityDrives大于set磁盘数的一半,则设置校验块个数为set的磁盘半数,也就是说校验块的个数是不定的dataDrives:=set中drives个数-partyDrives- writeQuorum := dataDrives,如果数据块与校验块的个数相等,则writeQuorum++
3.1.3.2 数据写入
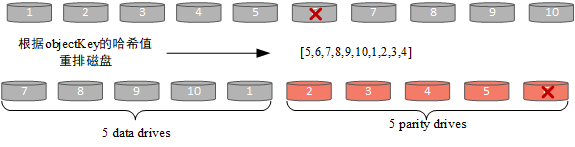
- 重排set中磁盘,根据对象的key进行crc32哈希得到分布关系
- 根据对象大小确定ec计算的buffer大小,最大为1M,即一个blockSize大小
- ec构建数据块与校验块,即上面提到的buffer大小
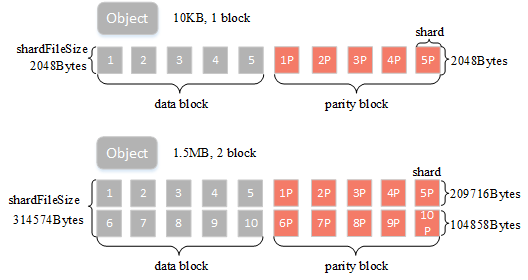
BlockSize:表示纠删码计算的数据块大小,可以简单理解有1M的用户数据则会根据纠删码规则计算得到数据块+校验块ShardSize:纠删码块的实际shard大小,比如blockSize=1M,数据块个数dataBlocks为5,那么单个shard大小为209716字节(blockSize/dataBlocks向上取整),是指ec的每个数据小块大小ShardFileSize:最终纠删码数据shard大小,比如blockSize=1M,数据块个数dataBlocks为5,用户上传一个5M的对象,那么这里会将其分五次进行纠删码计算,最终得到的单个shard的实际文件大小为5*shardSize
- 写入数据到对应节点,根据shardFileSize的大小会有不同的策略
- 小文件:以上图为例,假定对象大小为10KB,blockSize=1M,data block与parity block个数均为5,则shardFileSize=2048Bytes,满足小文件的条件,小文件的数据会存在元数据中,后面会详细介绍:
- 桶为开启多版本且shardFileSize小于128K;
- 或者shardFileSize大小小于16K。
- 大文件:如图所示,假定object大小为1.5MB,blockSize=1M,data block与parity block个数均为5,磁盘中对应文件则会分成两个block,每满1M数据会进行一次ec计算并写入数据,最后一个block大小为0.5MB,shardFileSize为209716+104858=314574(详细计算方法见附录
shardFileSize计算)。 - 数据在写入时会有数据bit位保护机制,可以有效检查出磁盘静默或者比特位衰减等问题,保证读取到的数据一定是正确的,比特位保护有两种策略:
- streaming-bitrot,这种模式每个block会计算一个哈希值并写入到对应的数据文件中;
- whole-bitrot,这种模式下是针对driver中的一个文件进行计算的,比如上面3小结中的图所示,针对block1+block6计算一个哈希值并将其写入到元数据中。可以看到第二种方式的保护粒度要粗一些,当前默认采用了第一种策略。

- 对于小于128K的文件走普通IO;大文件则是采用directIO,这里根据文件大小确定写入buffer,64M以上的数据,buffer为4M;其他大文件为2M,如果是4K对齐的数据,则会走drectIO,否则普通io(数据均会调用fdatasync落盘,
cmd/xl-storage.go中的CreteFile方法)
- 小文件:以上图为例,假定对象大小为10KB,blockSize=1M,data block与parity block个数均为5,则shardFileSize=2048Bytes,满足小文件的条件,小文件的数据会存在元数据中,后面会详细介绍:
3.1.3.3 元数据写入
元数据主要包含以下内容(详细定义见附录对象元数据信息)
- Volume:桶名
- Name:文件名
- VersionID:版本号
- Erasure:对象的ec信息,包括ec算法,数据块个数,校验块个数,block大小、数据分布状态、以及校验值(whole-bitrot方式的校验值存在这里)
- DataDir:对象存储目录,UUID
- Data:用于存储小对象数据
- Parts:分片信息,包含分片号,etag,大小以及实际大小信息,根据分片号排序
- Metadata:用户定义的元数据,如果是小文件则会添加一条
x-minio-internal-inline-data: true元数据 - Size:数据存储大小,会大于等于真实数据大小
- ModTime:数据更新时间
示例(源码xl-storage.go中的getFileInfo方法可以获取到元数据信息):
{
"volume":"lemon",
"name":"temp.2M",
"data_dir":"8366601f-8d64-40e8-90ac-121864c79a45",
"mod_time":"2021-08-12T01:46:45.320343158Z",
"size":2097152,
"metadata":{
"content-type":"application/octet-stream",
"etag":"b2d1236c286a3c0704224fe4105eca49"
},
"parts":[
{
"number":1,
"size":2097152,
"actualSize":2097152
}
],
"erasure":{
"algorithm":"reedsolomon",
"data":2,
"parity":2,
"blockSize":1048576,
"index":4,
"distribution":[
4,
1,
2,
3
],
"checksum":[
{
"PartNumber":1,
"Algorithm":3,
"Hash":""
}
]
},
...
}
3.1.4 数据在机器的组织结构
我们查看某个桶(目录)下的文件结构
.
├── GitKrakenSetup.exe #文件名
│ ├── 449e2259-fb0d-48db-97ed-0d71416c33a3 #datadir,存放数据,分片上传的话会有多个part
│ │ ├── part.1
│ │ ├── part.2
│ │ ├── part.3
│ │ ├── part.4
│ │ ├── part.5
│ │ ├── part.6
│ │ ├── part.7
│ │ └── part.8
│ └── xl.meta #存放对象的元数据信息
├── java_error_in_GOLAND_28748.log #可以看到这个文件没有datadir,因为其为小文件将数据存放到了xl.meta中
│ └── xl.meta
├── temp.1M
│ ├── bc58f35c-d62e-42e8-bd79-8e4a404f61d8
│ │ └── part.1
│ └── xl.meta
├── tmp.8M
│ ├── 1eca8474-2739-4316-9307-12fac3a3ccd9
│ │ └── part.1
│ └── xl.meta
└── worker.conf
└── xl.meta
3.1.5 思考
a. 对于不满足quorum写失败的数据如何清理?
minio在写入数据时会先将各个节点的数据写入到一个临时目录,如果写入不满足quorum则会将临时目录中的数据删除
b. 对于满足quorum写失败的节点数据如何恢复?
据的写入满足quorum机制且具备一定的数据可靠性,如果能够将写失败的数据通过某种手段恢复出来那么将极大提高数据的可靠性,所以针对上面问题可以从两个方面去思考:1. 如果发现写失败数据;2. 如何去恢复,这里如何去恢复比较简单,通过纠删码计算即可。所以这里主要介绍如何去发现缺失数据
- 在数据写入的时候发现:数据写入时我们能够知道哪些节点数据写入失败,这时如果发起数据修复则可快速的将写失败的数据恢复出来,但是可能会在设计上引入一定的复杂性;
- 在数据读取的时候发现:当正常的读请求过来,我们可以知道哪些节点的数据缺失,不过仅仅依赖读请求发现缺失数据在时间上有一定的滞后性,对于一些写多读少的场景数据缺失将很难被发现;
- 在数据巡检的时候发现:数据巡检可以更加全面的发现缺失数据,但是可能会占用较多的系统资源
minio在设计上是结合2跟3发现缺失数据并修复。
c. 数据写入时候会等待所有待写入节点返回(无论成功或失败),这里是否有优化点?
实际数据在写入时,如果需要等待所有节点返回响应,可能会存在长尾效应,导致写入时延不稳定,如果写入时满足quorum即向用户返回成功,由后台再等待其他节点响应在一定程度上能提升写入速度,不过也会在设计上增加复杂性。
3.2 数据下载
3.2.1 选择pool
源码在
cmd/erasure-server-pool.go中的GetObjectNInfo方法
- 单pool直接请求对应pool
- 多个pool
- 向所有pool发起对象查询请求,并对结果根据文件修改时间降序排列,如果时间相同则pool索引小的在前
- 遍历结果,获取正常对象所在的pool信息(对应pool获取对象信息没有失败)
3.2.2 选择set
源码在
cmd/erasure-sets.go中的GetObjectNInfo方法
与上传对象类似,对对象名进行哈希得到具体存储的set
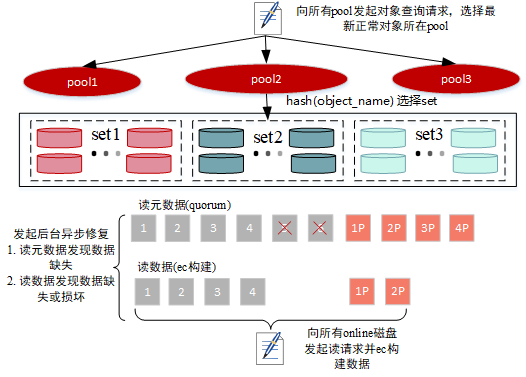
3.2.3 读元信息
源码在
cmd/erasure-object.go中的GetObjectNInfo方法
- 向所有节点发起元数据读取请求,如果失败节点超过一半,则返回读失败
- 根据元数据信息确定对象读取readQuorum(datablocks大小,即数据块个数)
- 根据第一步返回的错误信息判断元数据是否满足quorum机制,如果不满足则会判断是否为垃圾数据,针对垃圾数据执行数据删除操作
- 如果满足quorum,则会校验第一步读到的元数据信息正确性,如果满足quorum机制,则读取元信息成功
- 如果第一步返回的信息中有磁盘掉线信息,则不会发起数据修复流程,直接返回元数据信息
- 判断对象是否有缺失的block,如果有则后台异步发起修复(文件缺失修复)
3.2.4 读数据
- 根据数据分布对disk进行排序
- 读取数据并进行ec重建
- 如果读取到期望数据大小但读取过程中发现有数据缺失或损坏,则会后台异步发起修复,不影响数据的正常读取
- 文件缺失:修复类型为
HealNormalScan - 数据损坏:修复类型为
HealDeepScan
- 文件缺失:修复类型为
3.2.5 思考
a. 数据读取每次都会向所有online节点发起读请求,是否可以只发部分节点呢?考虑是什么?
正常来说只要能读到数据块个数的数据,即可将全部数据给计算出来,也可以提升数据的读取速度,不过这里向所有节点发起读请求可能考虑的是另外一个层面的事情,通过数据读取及时的发现缺失数据并修复,如果仅仅依赖巡检也有一定滞后性。
b. 数据修复的触发流程依赖读请求具有一定的局限性,对于一些冷数据可能一直得不到修复,是否还有其他流程修复数据?
除了根据读请求发现缺失数据,还有后台巡检流程能够修复缺失数据。
3.3 数据删除
删除相对来说要简单一些,这里主要介绍DeleteObject方法
3.3.1 普通删除
源码在
cmd/erasure-server-pool.go中的DeleteObject方法
前缀删除:会向所有pool发送删除请求 非前缀删除:主要流程如下
- 选择pool,向对应pool发起删除请求
- 单pool直接返回
- 向所有pool发起查询请求并根据更新时间降序排列,遍历结果得到pool
- 如果最新对象存在但是已经标删,也会返回该pool
- 如果对象不存在,则直接返回
- 其他错误,直接返回
- 正常返回对应pool
- 选择set,向对应set发起删除请求
- 删除,确定writeQuorum,大小为set中disk数/2+1,并向所有节点发送删除请求
- 删除元数据中对应版本
- 如果存在数据目录(小文件数据存在xl.meta文件中,大文件则存在数据目录),则将数据移动至临时桶
minioMetaTmpDeletedBucket中异步清理 - 将元数据文件移动至临时桶
minioMetaTmpDeletedBucket中,异步清理 - 删除对象目录

如图所示,文件
temp.1M为大文件,数据存储在磁盘中的数据结构为左边所示,在删除时候会进行以下关键几步:(小文件的删除少了第二步,因为数据存储在xl.meta中,所以在执行第三步的同时也把数据移动到了回收站)
- 删除元数据文件xl.meta中的对应版本,针对单版本删除这里Versions切片元素删除后为空
- 将数据目录及下的数据文件移动到回收站
- 将元数据文件移动到回收站
- 删除对象目录
- 异步清除回收站内容
3.3.2 思考
a. 删除数据如果不满足quorum机制,已经删除的数据是否会被修复回来?
这里其实分很多场景,删除数据失败,可能是删除元数据失败也可能是删除数据失败,这里简单介绍几种场景
- 元数据删除部分失败导致不满足quorum,如果其他没有删除的元数据能够正常读取,那么数据在巡检过程中可能会被修复回来,但是这不影响,因为返回给用户是删除失败,可以等待用户下次删除
- 元数据均删除成功,但是数据未删除成功而不满足quorum,这个时候巡检不会对其进行修复
b. 删除的数据会暂时保存在回收站,那么是否有办法将回收站中的数据恢复出来?
目前没有看到相关数据恢复代码,不过只要数据存在可以通过一定的手段将数据恢复出来
c. 删除满足quorum机制,对于删除失败的节点怎么处理?
删除失败节点上的数据其实为垃圾数据,这里会通过数据巡检流程去删除,巡检过程中如果发现存在数据不满足quorum,则会去执行数据清理操作
3.4 磁盘修复
3.4.1 发现坏盘
源码在
cmd/erasure-sets.go中的connectDisks方法中
- 定期巡检各个磁盘,检查磁盘是包含磁盘格式化文件format.json)
{
"version":"1",
"format":"xl",
"id":"8acad898-054b-4414-92b1-b01a49d61407",
"xl":{
"version":"3",
"this":"8585ed86-180f-4fd4-a95e-83d5ef2943ec",
"sets":[
[
"8585ed86-180f-4fd4-a95e-83d5ef2943ec",
"dba71e26-9bb0-49a4-9c4a-d4c1fb8dca6d",
"49fb2e14-3c71-4d59-99dd-f26029928f4a",
"5f755d25-bce7-40e7-b1cc-a360c7b8e4c7"
]
],
"distributionAlgo":"SIPMOD+PARITY"
}
}
- 如果不包含则会去检查当前磁盘是否还有用户数据,如果有则会报错非预期磁盘;如果没有其他数据则说明是块新盘返回特定错误
errUnformattedDisk - 对于本地盘且出现
errUnformattedDisk错误的磁盘加入到待修复磁盘队列中
3.4.2 修盘
源码在
cmd/background-newdisks-heal-ops.go的monitorLocalDisksAndHeal方法
定期检查是否存在待修磁盘,如果存在则会进行以下操作
HealFormat,检查集群中所有磁盘是否缺失format.json文件,如果缺失则会将其修补回来HealBucket,修复桶元数据HealObject,修复桶中的文件
下面是磁盘修复示例日志
Found drives to heal 1, proceeding to heal content...
Healing disk '/data/minio/data1' on 1st pool
Healing disk '/data/minio/data1' on 1st pool complete
Summary:
{
"ID": "8585ed86-180f-4fd4-a95e-83d5ef2943ec",
"PoolIndex": 0,
"SetIndex": 0,
"DiskIndex": 0,
"Path": "/data/minio/data1",
"Endpoint": "/data/minio/data1",
"Started": "2021-10-15T10:07:27.12996706+08:00",
"LastUpdate": "2021-10-15T02:07:40.784965249Z",
"ObjectsTotalCount": 11,
"ObjectsTotalSize": 561956829,
"ItemsHealed": 20,
"ItemsFailed": 0,
"BytesDone": 561966273,
"BytesFailed": 0,
"QueuedBuckets": [],
"HealedBuckets": [
".minio.sys/config",
".minio.sys/buckets",
"lemon"
]
}
3.5 数据巡检
源码在
cmd/data-scanner.go的runDataScanner方法
数据巡检主要做以下事情:
- 发现缺失的数据,并尝试将其修复,无法修复的数据(垃圾数据)则会进行清理
- 统计计量信息,如文件数、存储量、桶个数等
巡检时候会在每块磁盘上对所有bucket中的数据进行巡检,这里主要介绍下巡检是如何发现待修复数据并执行修复?
- 扫描对象信息时:如果发现数据缺失或数据损坏则会快速或深度修复(深度扫描会校验数据文件是否完整,而快速扫描则是检查数据是否缺失,巡检时是否发起深度巡检是在服务启动配置中设置的),不是每一次的巡检都会发起修复,通常是每巡检一定轮数会发起一次,这里的修复是立即执行的;
- 跟上一次巡检结果对比:比如上次巡检发现有文件A,这次巡检却没有找到文件A,满足一定条件则会发起修复操作,这里的巡检是先投递修补消息,异步修复。
每次巡检都会将巡检的结果缓存在本地,下次巡检与之对比
3.6 垃圾数据清理
前面提到数据删除之后会先将其移动到回收站,然后交由后台协程定时扫描清理,接下来主要介绍清理过程
源码在
erasure-sets.go的cleanupDeletedObjects
这里的清理策略其实很简单,定时的去清理回收站的所有文件,也就是说对于已经放入回收站的数据来说没有单独的时间保护窗口,均是定期被清理。
四、附录
4.1 ec数据分布模式计算
// hashOrder - hashes input key to return consistent
// hashed integer slice. Returned integer order is salted
// with an input key. This results in consistent order.
// NOTE: collisions are fine, we are not looking for uniqueness
// in the slices returned.
func hashOrder(key string, cardinality int) []int {
if cardinality <= 0 {
// Returns an empty int slice for cardinality < 0.
return nil
}
nums := make([]int, cardinality)
keyCrc := crc32.Checksum([]byte(key), crc32.IEEETable)
start := int(keyCrc % uint32(cardinality))
for i := 1; i <= cardinality; i++ {
nums[i-1] = 1 + ((start + i) % cardinality)
}
return nums
}
4.2 shardFileSize计算
// ceilFrac takes a numerator and denominator representing a fraction
// and returns its ceiling. If denominator is 0, it returns 0 instead
// of crashing.
func ceilFrac(numerator, denominator int64) (ceil int64) {
if denominator == 0 {
// do nothing on invalid input
return
}
// Make denominator positive
if denominator < 0 {
numerator = -numerator
denominator = -denominator
}
ceil = numerator / denominator
if numerator > 0 && numerator%denominator != 0 {
ceil++
}
return
}
// ShardSize - returns actual shared size from erasure blockSize.
func (e *Erasure) ShardSize() int64 {
return ceilFrac(e.blockSize, int64(e.dataBlocks))
}
// ShardFileSize - returns final erasure size from original size.
func (e *Erasure) ShardFileSize(totalLength int64) int64 {
if totalLength == 0 {
return 0
}
if totalLength == -1 {
return -1
}
numShards := totalLength / e.blockSize
lastBlockSize := totalLength % e.blockSize
lastShardSize := ceilFrac(lastBlockSize, int64(e.dataBlocks))
return numShards*e.ShardSize() + lastShardSize
}
4.3 对象元数据信息
type FileInfo struct {
// Name of the volume.
Volume string
// Name of the file.
Name string
// Version of the file.
VersionID string
// Indicates if the version is the latest
IsLatest bool
// Deleted is set when this FileInfo represents
// a deleted marker for a versioned bucket.
Deleted bool
// TransitionStatus is set to Pending/Complete for transitioned
// entries based on state of transition
TransitionStatus string
// TransitionedObjName is the object name on the remote tier corresponding
// to object (version) on the source tier.
TransitionedObjName string
// TransitionTier is the storage class label assigned to remote tier.
TransitionTier string
// TransitionVersionID stores a version ID of the object associate
// with the remote tier.
TransitionVersionID string
// ExpireRestored indicates that the restored object is to be expired.
ExpireRestored bool
// DataDir of the file
DataDir string
// Indicates if this object is still in V1 format.
XLV1 bool
// Date and time when the file was last modified, if Deleted
// is 'true' this value represents when while was deleted.
ModTime time.Time
// Total file size.
Size int64
// File mode bits.
Mode uint32
// File metadata
Metadata map[string]string
// All the parts per object.
Parts []ObjectPartInfo
// Erasure info for all objects.
Erasure ErasureInfo
// DeleteMarkerReplicationStatus is set when this FileInfo represents
// replication on a DeleteMarker
MarkDeleted bool // mark this version as deleted
DeleteMarkerReplicationStatus string
VersionPurgeStatus VersionPurgeStatusType
Data []byte // optionally carries object data
NumVersions int
SuccessorModTime time.Time
}
4.4 磁盘格式化元数据
// formatErasureV3 struct is same as formatErasureV2 struct except that formatErasureV3.Erasure.Version is "3" indicating
// the simplified multipart backend which is a flat hierarchy now.
// In .minio.sys/multipart we have:
// sha256(bucket/object)/uploadID/[xl.meta, part.1, part.2 ....]
type formatErasureV3 struct {
formatMetaV1
Erasure struct {
Version string `json:"version"` // Version of 'xl' format.
This string `json:"this"` // This field carries assigned disk uuid.
// Sets field carries the input disk order generated the first
// time when fresh disks were supplied, it is a two dimensional
// array second dimension represents list of disks used per set.
Sets [][]string `json:"sets"`
// Distribution algorithm represents the hashing algorithm
// to pick the right set index for an object.
DistributionAlgo string `json:"distributionAlgo"`
} `json:"xl"`
}
20盘2个set示例
{
"version":"1",
"format":"xl",
"id":"921e205e-15bc-480e-899d-8f220a0d908a",
"xl":{
"version":"3",
"this":"d3b71e3d-f71c-4140-a982-81071be76687",
"sets":[
[
"d3b71e3d-f71c-4140-a982-81071be76687",
"6e80d70a-7ce3-4446-a078-4ea97272deb4",
"fdfe30e1-97ba-48ad-8db9-b36f1adb40df",
"68e99791-8f3e-4b68-8e61-57b39ce8e105",
"8211a0d6-2be4-47a9-a08c-5bd42821fd47",
"b2bb82a4-cf92-406a-9a4b-235b4608009b",
"6bd02b7d-e40f-4d6d-ae28-cae9555a8148",
"da7fe426-232d-4510-bb28-1b4c6fff1695",
"1aa3fca1-20e5-48ac-8ac2-b49399300a42",
"b9088ba0-bf4c-45a7-87f7-3d10266577ab"
],
[
"500a6ae7-a46e-4ad9-a409-d6265d0d7d54",
"01b55e5f-3e15-4a0c-8a18-1ee9e1864753",
"7ce04256-c860-411f-92ea-bd5c5335d358",
"f334e1bd-498e-4d44-9ff7-2f7c41c40c7b",
"81c39b83-7215-49e1-86c5-e1af3d0283a4",
"e9d832fa-73e4-4963-90c3-8d11048a3dfc",
"e5c291ce-cc14-484a-b707-61088f91fd8c",
"6af2ed10-67ef-4c9f-b3fb-4a0bce6732b5",
"63fa146c-71bd-4466-a130-23c8d2b50cab",
"b80ca0e5-3e04-4b90-a1b6-6e83669c046d"
]
],
"distributionAlgo":"SIPMOD+PARITY"
}
}














 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









