









如果你觉得这篇博客对你有所帮助, 请在左边点个赞吧: )
下面我们先提出几个问题:
已知有n个长度不等的母串, 以及一个长度为m的模式串, 求该模式串是否为其中一个母串的前缀.
这个问题应该如何解呢? 按照最常规的暴力方法, 使用线性搜索, 从头到尾挨个查找, 时间复杂度将会达到O(n*m), 如果n或m很大, 或者需要查找的模式串很多, 那么时间复杂度将会非常的大.
再看另一问题:
已知一个长度为n的字符串S, 求该字符串有多少个不同的子串.
朴素的做法是, 枚举出所有的子串, 再去重, 时间复杂度将高达O(n^2).
作为一个非常看重性能的程序设计者,用这么多时间解决这种小问题显然是无法容忍的. 所幸, 我们的前辈们已经给我们提供了很好的解决方案.那就是我们这篇博客的主角:
字典树
定义: 字典树, 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。
应用: 典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
优点: 利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
三个性质: 根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。 (百度百科)
如何建立字典树呢?
比如我们有a, to, tea, ted, ten, i, in, inn 等字符串, 我们建立的字典树是这样的:
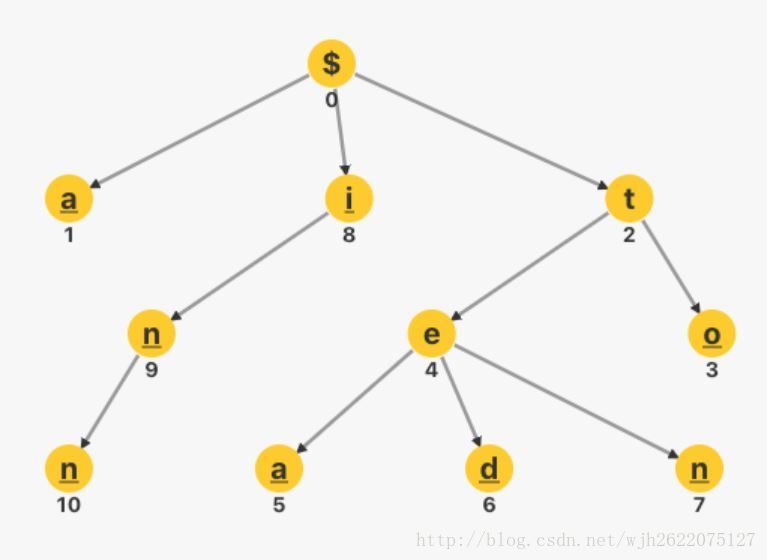
每个结点对应一个字母, 结点的值就是它的编号(第几个结点), 根节点没有值, 单词从根节点往下遍历.
需要说明的是, 字典树遍历是否存在孩子结点的方式不是从a->b依次遍历, 而是直接判断.时间复杂度是O(1). 怎么说呢?
这跟它的策略有关: 用空间换取时间.
现在不理解没有关系, 看了接下来的字典树构造代码后, 相信很容易就可以明白了.
这是一个结点类:
class Node {
public:
Node() {
fill(son,son+26,0); //初始化(可能的)孩子结点
is = 0;
}
int son[26]; //26个元素分别代表26个字母, 数量视具体情况而定.
bool is; //标记次结点是否为一字符串终点
} node[666666];接下来是插入操作:
int tot = 0; //结点序号
void insert(string str)
{
int p = 0;
for( int i=0; str[i]; ++i ) {
if(node[p].son[str[i] - 'a'] == 0) {
node[p].son[str[i] - 'a'] = ++tot;
}
p = node[p].son[str[i] - 'a']; //迭代
}
node[p].is = 1; //字符串末尾字母标记
}然后是查询操作:
bool search(string str)
{
int p = 0;
for( int i=0; str[i]; ++i ) {
if(node[p].son[str[i] - 'a'] == 0) {
return false; //没有找到, 也不存在这样的前缀
}
p = node[p].son[str[i] - 'a'];
}
if( node[p].is == 1 ) return true; //找到了这个字符串
else return false; //没有这个字符串, 但它是其他某字符串的前缀
}以上三段代码就是字典树最基本的三个操作:
- 建立结点, 即建立了一个空的字典树
- 向字典树中插入字符串
- 在字典树字典树中查找字符串
需要注意的是:
- 字典树还有一些其他功能, 如查询前缀等, 只需稍加变动就可实现. 具体如何使用字典树, 视情况而定.
- 字典树可以储存如上由单词组成的字符串, 但不限于此, but必须已知
- 字典树策略是空间换时间, 因此时间不是问题, 应该留心空间复杂度
百度百科上一些应用:
串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
“串”排序
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为当时公共祖先问题。
题目背景
XS中学化学竞赛组教练是一个酷爱炉石的人。
他会一边搓炉石一边点名以至于有一天他连续点到了某个同学两次,然后正好被路过的校长发现了然后就是一顿欧拉欧拉欧拉(详情请见已结束比赛CON900)。
题目描述这之后校长任命你为特派探员,每天记录他的点名。校长会提供化学竞赛学生的人数和名单,而你需要告诉校长他有没有点错名。(为什么不直接不让他玩炉石。)
输入输出格式 输入格式:第一行一个整数 n,表示班上人数。接下来 n 行,每行一个字符串表示其名字(互不相同,且只含小写字母,长度不超过 50)。第 n+2
行一个整数 m,表示教练报的名字。接下来 m 行,每行一个字符串表示教练报的名字(只含小写字母,且长度不超过 50)。输出格式:
对于每个教练报的名字,输出一行。如果该名字正确且是第一次出现,输出“OK”,如果该名字错误,输出“WRONG”,如果该名字正确但不是第一次出现,输出“REPEAT”。(均不加引号)
输入输出样例 输入样例#1: 复制
5 a b c ad acd 3 a a e
输出样例#1: 复制
OK REPEAT WRONG
说明
对于 40%的数据,n≤1000,m≤2000;
对于 70%的数据,n≤10000,m≤20000;
对于 100%的数据, n≤10000,m≤100000。
T1总是送分的。
代码:
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int tot = 0;
class Node {
public:
Node() {
fill(son,son+26,0);
cnt = 0;
is = 0;
}
int cnt;
int son[26];
bool is;
}node[500000];
void insert(string str)
{
int p = 0;
for( int i=0; str[i]; ++i ) {
if(node[p].son[str[i] - 'a'] == 0) {
node[p].son[str[i] - 'a'] = ++tot;
}
p = node[p].son[str[i] - 'a'];
}
node[p].is = 1;
}
int search(string str)
{
int p = 0;
for( int i=0; str[i]; ++i ) {
if(node[p].son[str[i] - 'a'] == 0) {
return -1; //Wrong
}
p = node[p].son[str[i] - 'a'];
}
if( !node[p].is ) return -1; //WRONG
if( node[p].cnt == 0 ) {
node[p].cnt++;
return 0; //OK
}
return 1; //REPEAT
}
int main( )
{
int n, m, judge;
cin >> n;
string tmp;
for( int i=0; i<n; ++i ) {
cin >> tmp;
insert(tmp);
}
cin >> m;
for( int j=0; j<m; ++j ) {
cin >> tmp;
judge = search(tmp);
if( judge == -1 ) cout << "WRONG\n";
else if( judge == 0 ) cout << "OK\n";
else cout << "REPEAT\n";
}
return 0;
}欢迎在评论区讨论问题, 或指出博主错误: )















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









