







背景
最近在写MapReduce程序时,一直在用IDE,发现编译器执行的程序,无论成功还是失败,在http://master:8088/上看不到记录,于是想不靠IDE手动编译运行一下程序,这一试出现了问题。
问题
如果编译运行不在任何包中的代码,也就是在代码最上方,不存在package xxxxxx(xxxxxxxx表示代码所述的包名)则按照正常的流程编译、运行一般没什么问题。
但如果代码在某个包中,则可能会提示如下错误:
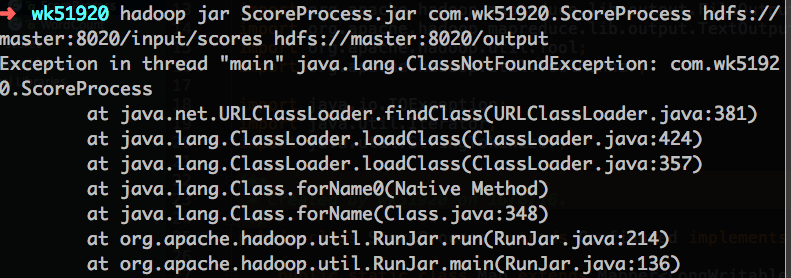
解决方法
1. 示例程序源代码:
package com.wk51920;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
/**
* Created by wk51920 on 16/6/16.
*/
public class ScoreProcess extends Configured implements Tool {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
StringTokenizer stringTokenizerArticle = new StringTokenizer(line, "\n");
while (stringTokenizerArticle.hasMoreTokens()) {
StringTokenizer stringTokenizerLine = new StringTokenizer(stringTokenizerArticle.nextToken());
String strName = stringTokenizerLine.nextToken();
String strScore = stringTokenizerLine.nextToken();
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
context.write(name, new IntWritable(scoreInt));
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();
count++;
}
int average = (int) sum / count;
context.write(key, new IntWritable(average));
}
}
@Override
public int run(String[] strings) throws Exception {
Job job = new Job(getConf());
job.setJarByClass(ScoreProcess.class);
job.setJobName("ScoreProcess");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(strings[0]));
FileOutputFormat.setOutputPath(job, new Path(strings[1]));
boolean success = job.waitForCompletion(true);
return success ? 0 : 1;
}
public static void main(String[] args) throws Exception{
int ret = ToolRunner.run(new ScoreProcess(), args);
System.exit(ret);
}
} 2. 从控制台进入到源代码所在的目录。

其中,/Users/txli/hadoopIdea/src/com/wk51920是我的源代码所在的目录,下面的三个文件只有ScoreProcess.java是我们这次编译的目标文件,其余两个文件跟此次编译没有任何关系。
3. 在当前目录下输入javac -d . ScoreProcess.java,会在当前目录下自动生成com/wk51920/目录,并将编译好的三个class文件放在自动生成的文件夹下。
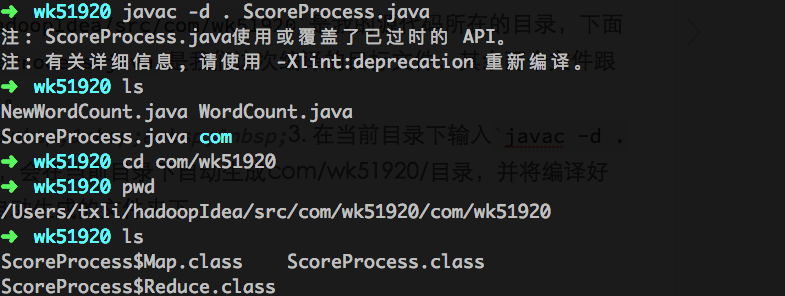
4. 如果此时在此目录下(编译好的三个class文件所在的文件夹下)直接执行jar -cvf ScoreProcess.jar ./*,则依然会提示ClassNotFoundException异常。
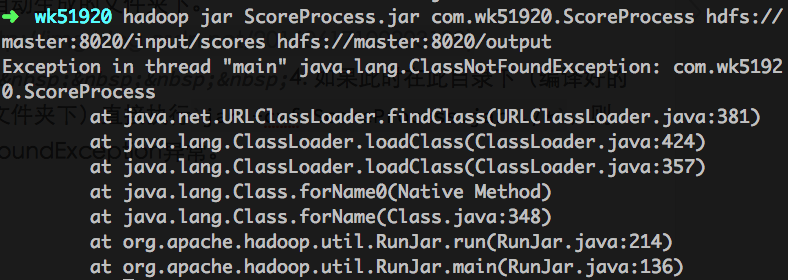
5. 此时应该cd至/Users/txli/hadoopIdea/src/com/wk51920,也就是源代码所在的目录。并在此处执行
jar -cvf com/wk51920/ScoreProcess.jar com/wk51920/*.class 6. 执行cd com/wk51920进入到打包好的文件夹中(就是三个编译好的class文件所在的文件夹)。

7. 在此目录下执行:
# 注意下面这是一行连着的命令,不要当成两条命令来输入
# 其中,hdfs://master:8020/input/scores是此程序需要的输入文件在HDFS上的地址,hdfs://master:8020/output是程序的输出地址。
# 至于如何将文件放入HDFS系统,这个不是此次说明的内容
hadoop jar ScoreProcess.jar com.wk51920.ScoreProcess hdfs://master:8020/input/scores hdfs://master:8020/output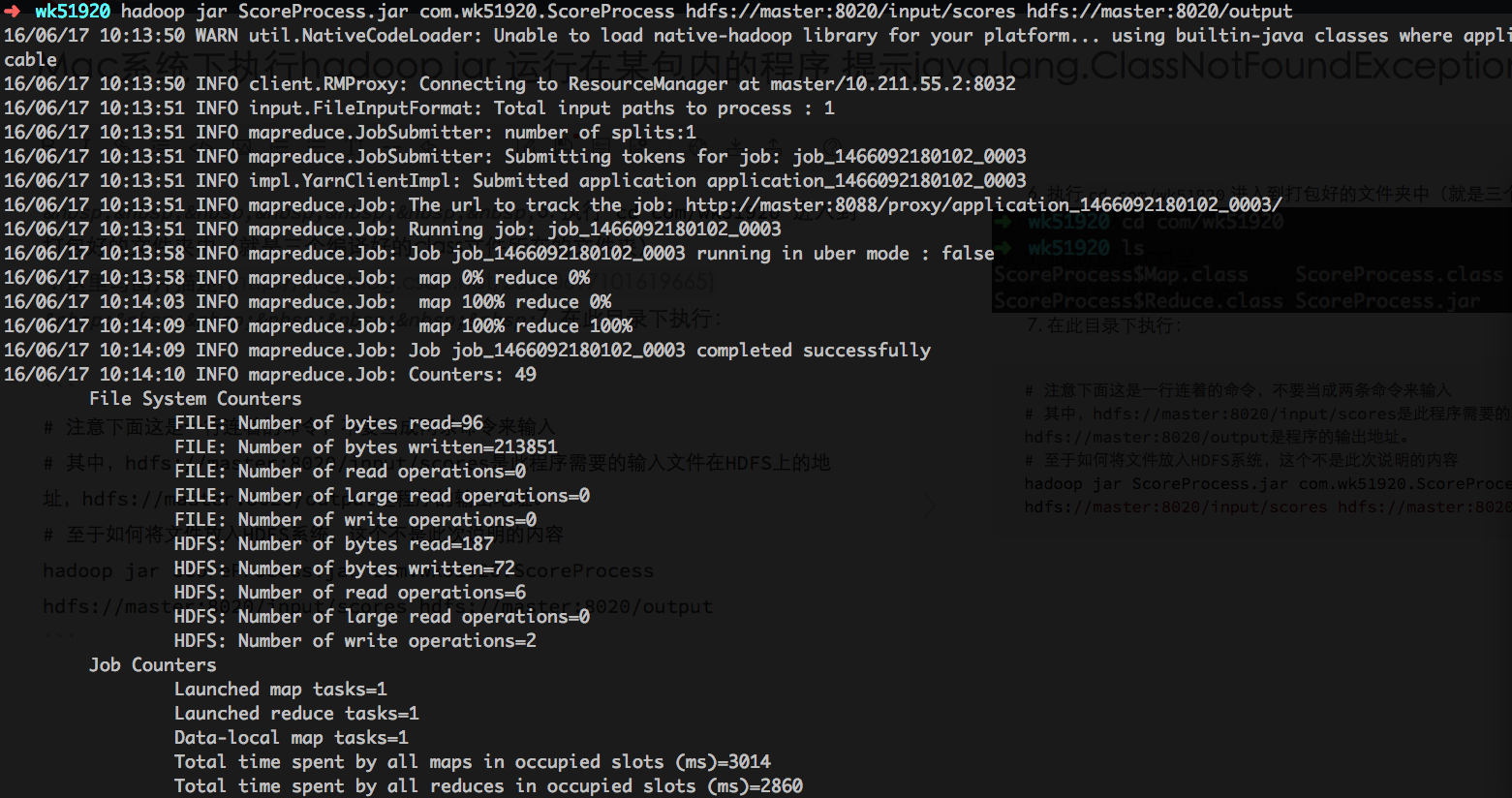
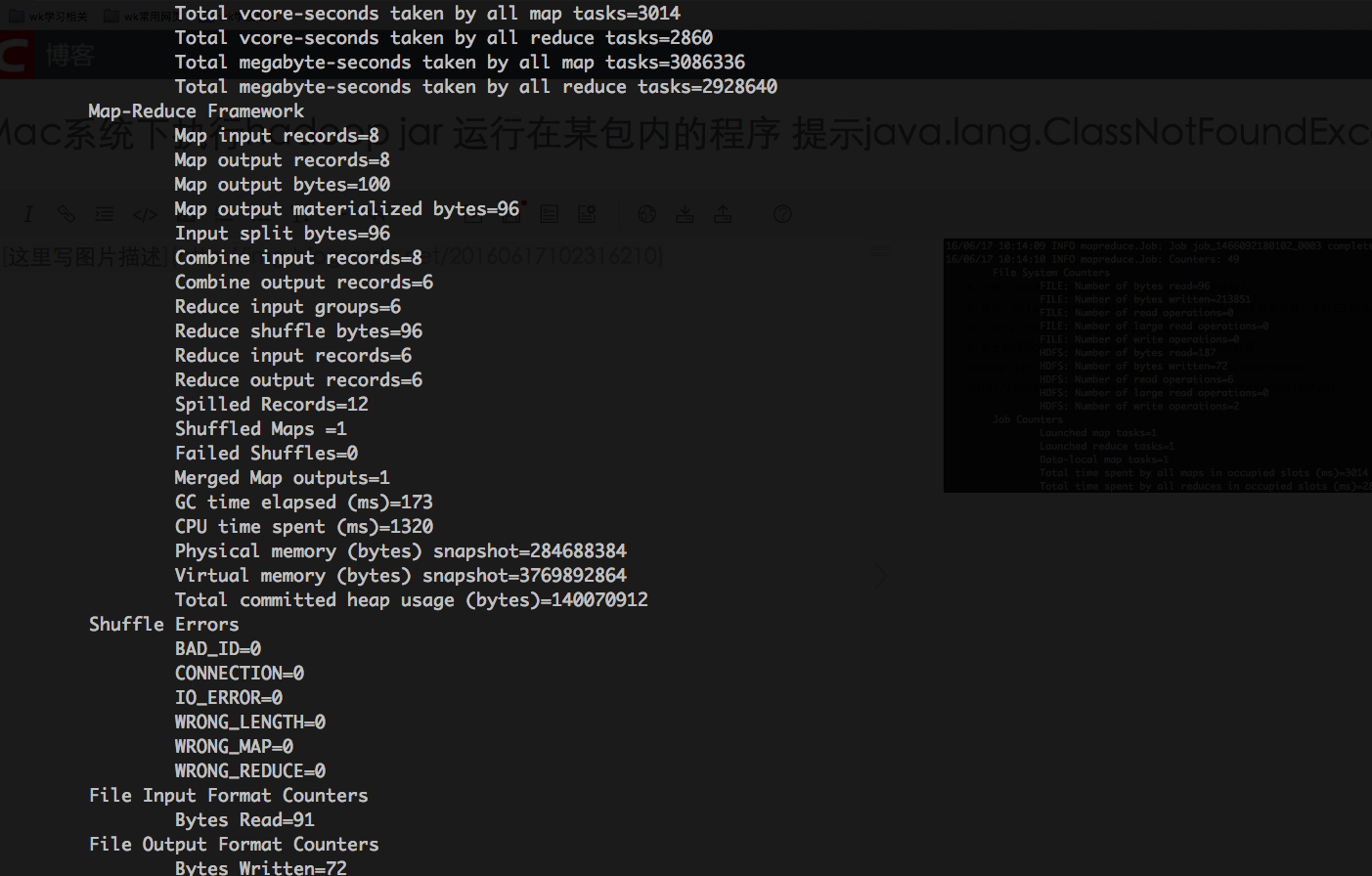
至此运行成功!















 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









