







论文原文:http://staff.ustc.edu.cn/~cheneh/paper_pdf/2013/HaoWang.pdf
这是2013年中科大和华为诺亚方舟实验室的论文,主要是一种基于检索式的问答模型,并且本文对实验数据获取和处理做了详细的介绍。
语料来源:
语料的数据来自于新浪微博,将新浪微博中的信息及其评论看作是一个单轮对话。大概的收集过程如下图:
首先选择10个NLP领域比较活跃的用户,然后依次作为种子用户,进行爬取,直到获得3200与NLP和ML相关的用户,然后抓取每个用户的微博和下面的评论,时间跨度为2个月。这样定向爬取的好处是选择的用户和所发表的微博涉及的领域比较窄,而不至于天马行空什么都有。
数据处理:
新浪微博及其评论限制在140个汉字
- 将少于10个汉字或者5个字符的评论信息(responses)和微博信息(post)删除掉
- 对每个post取前100条评论
- 剔除潜在广告信息
模型:
模型一共分为两步,第一步是选择出评论候选列表(post,response)对,第二步是在候选列表中进行排序。模型会通过三个baseline各选择10条评论,构成一个<=30的评论候选列表,对候选列表标注极少量的数据,应用于排序模型中,最终输出。整体步骤如下:

三个baseline模型:
- Post-Response Semantic Matching 根据微博和评论之间的语义匹配程度选择出10个候选评论。
- Post-Response Similarity 根据微博和评论之间的相似度选择出10个候选评论。
- Post-Post Similarity 根据微博和微博之间的相似度选择出10个候选评论,即用相似微博的评论作为候选评论。
标注:
标注工作是将评论分为两类,即suitable和unsuitable,即正样和负样。判断一个评论是否是suitable一共有三个准则:
- semantic relevance,这个准则是判断微博和评论是否语义相关;
- logic consistency,这个准则是判断微博和评论是否在逻辑上是一致的;
- speech act alignment,这个准则是判断微博和评论在act方面是否是对齐的。
文中4W多的post数据标注了400多条post,每条post数据再对baseline提取出来的<=30个response进行标注。文中提到训练模型时可以随机抽取负样本,但是用3个beasline抽取出来的数据做标注可能效果更好一些,因为这些负样本在某个beasline中的排名是比较靠前的
排序
接下来就是通过标注数据进行排序,排序学习的目标是让正例的score比负例的score更大。文中根据匹配模型构造一系列的匹配特征,最终的匹配得分是各个特征之间的组合,如公式。
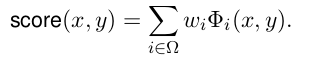
文中没有对特征做详细的介绍,只是举例列举了2种特征:
是一下两个方面的综合:
- 输入query post和待选response的语义匹配得分
- query post和待选response的原始post的相似度
是post和response中的最大公共字符串
基于检索的bot解决方案是一种常见的方案,这种方案的重点在于知识库的质量,也就是那个database,一个query对应多个reply。但稍微复杂的问题,知识库的应变能力差的缺点就暴露出来了,比如query中有named entity,并且这个entity在知识库中没有出现过,这时reply就会出现牛头不对马嘴的情况,解决单轮对话都存在很大的缺陷,那么解决多轮对话就会更困难。虽然说,可以通过做query和reply、query和query之间语义层面相似度的计算,比如用一些成熟的deep learning技术来做。但根本上并没有解决这种方法的弊端,倒是非常垂直的闭域bot可以考虑用这个方案加上一些策略来解决,比如企业客服bot,因为知识库规模小,根据企业的资料和一些过往的用户对话数据可以建设一个质量不错的知识库,从而得到质量不错的bot【1】。
参考:
【1】https://zhuanlan.zhihu.com/p/21546490















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









