







语句/分支/路径覆盖这些控制流覆盖准则,背后的价值观是“被测程序的价值和风险集中在控制逻辑上”。还有另外一些程序,它们的价值和风险集中在数据计算上,这时候一个基本的想法是:如果程序变量的某个计算结果,没有在任何测试用例的执行过程中产生过效果,我们很难相信这个程序是正确的。从这种想法出发,可以定义数据流覆盖准则。
在程序的数据流结构里,主要的元素有三种:
① 定义节点,指的是流程图里某个变量被赋值的节点,比如:
![]()
② 使用节点,指的是里某个变量的值被引用的节点,比如:

③ 定义使用路径,指的是从一个定义节点到一个使用节点的路径,并且要求这条路径的起点和终点之间,没有其它的定义节点。
举个例子。被测程序代码如下:
public void dataFlowTestDemo(int x, int y, int pow){if (y >= 10) {pow = y;} else {pow = -y;}int z = 1;if (pow > 0) {z = z * x;pow--;if (x >= 0) {x--;}x = x * pow;} else if (y < 0) {z++;} else {z--;}}
在程序流程图中,用绿色背景代表pow变量的定义节点,黄色背景代表pow变量的使用节点:
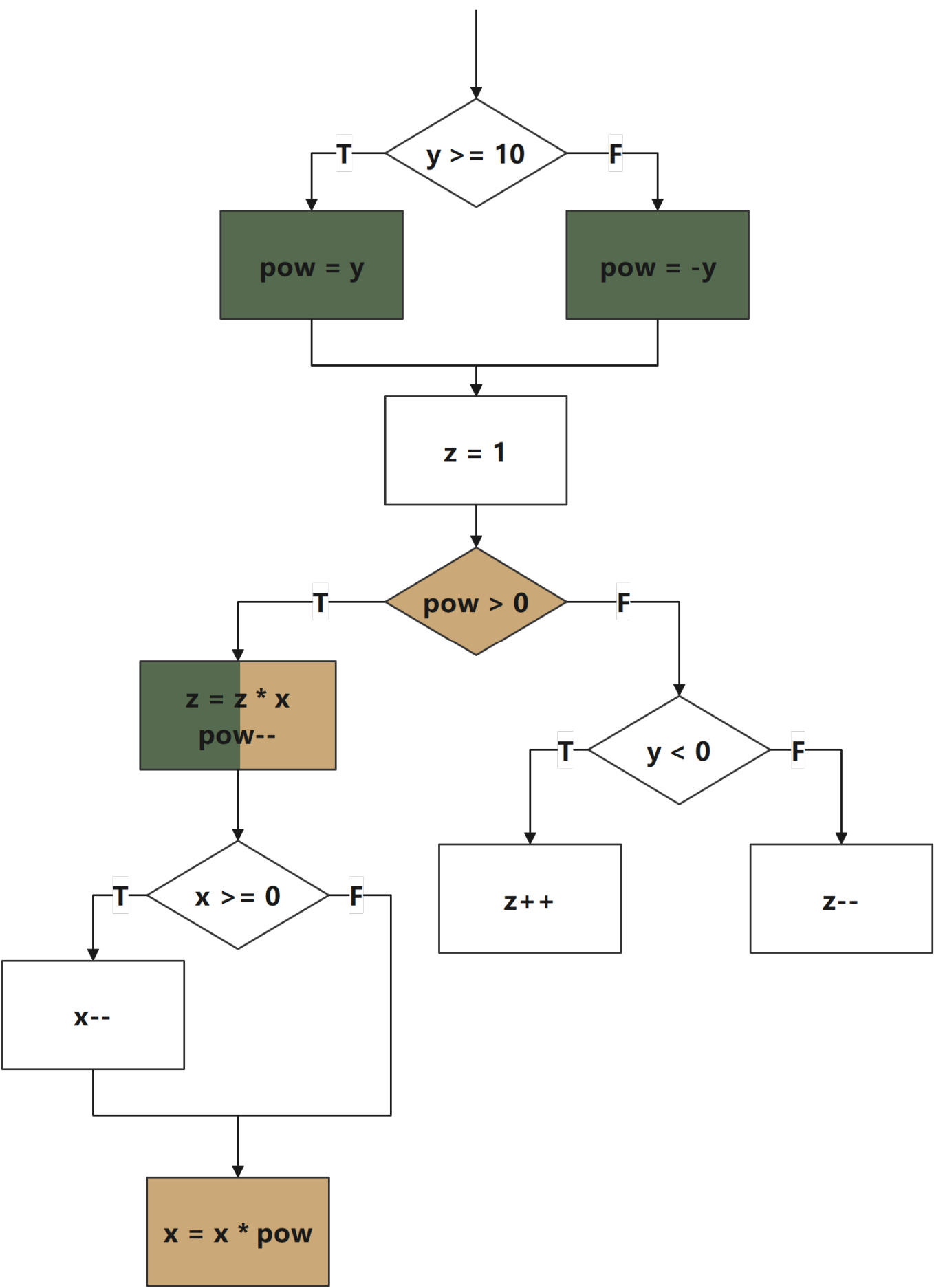
从节点“pow = y”到节点“pow > 0”是一条定义使用路径;从节点“pow = y”到节点“z = z*x pow--”也是一条定义使用路径;但是从节点“pow = y”到节点“x = x*pow”就不是一条定义使用路径,因为起点和终点之间有“pow--”这个定义节点。
既然数据流结构的主要元素是定义节点、使用节点、定义使用路径,数据流覆盖准则主要就包括这样3种:全定义覆盖准则、全使用覆盖准则、全定义使用路径覆盖准则。

当然,在实际测试执行的时候,程序里的变量必须要“先定义再使用”。所以“全使用覆盖准则”不只要求覆盖所有使用节点,而且针对每一个使用节点,都要覆盖它跟所有定义节点的至少一条定义使用路径。可以说,全使用覆盖准则,实际上要求覆盖的是所有定义使用对。
这三种准则中,要求最高的是“全定义使用路径覆盖准则”,因为一个使用节点和一个定义节点之间,可能有不止一条定义使用路径,这个准则要求覆盖所有这些路径。















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









