







下面我们来看一种更加精妙的基于缺陷的充分准则——布尔逻辑缺陷检出准则。我们知道,在软件和电路领域,普遍采用布尔逻辑,来描述被测对象期望。比方说,一个电路有4个输入信号a、b、c、d,有一个输出信号f:
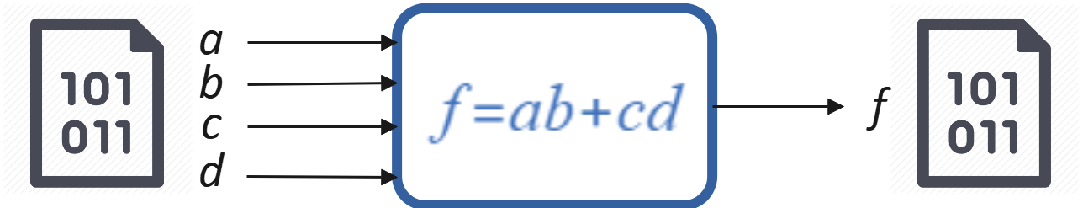
这些输入和输出信号都是布尔变量,只有0/1两种取值,输入布尔变量也叫“条件”。输入输出之间期望的关系是“f=(a∧b)∨(c∧d)”,可以简写为“f=ab+cd”。这就是一个布尔逻辑表达式,而且这还是一个析取范式,这里的ab和cd也叫蕴含项。根据范式存在定理,所有布尔逻辑表达式都存在着与之等值的析取范式。所以为了简化问题,后面我们只讨论析取范式。
要实现一个布尔逻辑表达式,在电路里用的是门电路:
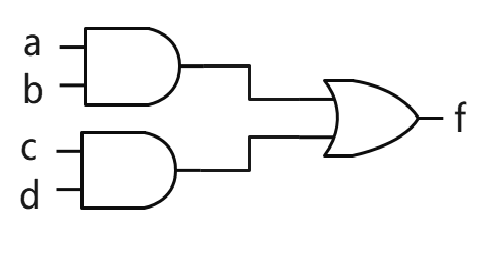
在软件里用的是代码:
![]()
那么,怎么才能保证实现这种布尔逻辑的时候不出问题呢?我们就需要依靠布尔逻辑缺陷检出准则。
首先我们来看看,布尔逻辑里容易出现的缺陷是什么样的。有人已经帮我们做了非常全面的总结,总共有这样9种可能的缺陷:

这9类缺陷之间,存在着一种很有趣的关系,也就是所谓的“支配”关系。比方说,条件引用缺陷(LRF)就支配条件否定缺陷(LNF)。什么意思?如果一个用例能检出条件引用缺陷,就必然能检出条件否定缺陷。
为什么会这样?我们来做一个简单的证明。前面说过了,条件引用缺陷就是一个条件被写成了别的条件,比如条件b被写成d了,f就变成了f’。条件否定缺陷就是一个条件被写成了它的反,比如条件b被写成b反了,f就变成了f”:

那么,什么样的用例能检出这个LRF缺陷呢?这个用例必须要让f≠f’,也就是要让ab+cd≠ad+cd,这样我们才能发现问题。
这意味着两件事:① cd必须是0; ② a必须是1。于是就会有:
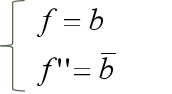
所以,这个用例一定能让f”≠f,这样就能检出上面这个LNF缺陷。
也就是说,只要一个用例能检出上述LRF缺陷,就必然能检出对应的LNF缺陷。所以LRF缺陷支配LNF缺陷。
类似的,我们还可以证明其它缺陷类型之间的支配关系,最终得到这样的一个结构:

这里箭头的起点表示支配者,终点表示被支配者。
本来,我们想要让一个测试集能检出这么多种缺陷,似乎难度还挺大的。但是根据这样的缺陷结构,我们就知道了,如果一个测试集能保证检出条件插入缺陷(LIF)和条件遗漏缺陷(LOF),那么这个测试集就可以检出全部九类典型缺陷。是不是感觉一下子容易了很多?
下面我们就围绕LIF和LOF这两类缺陷,来建立充分准则。作为铺垫,我们需要先定义几个概念:
① 真值点,指的是让整个析取范式值为1的测试输入点;
② 唯一真值点,指的是一种特殊的真值点,它可以让某个蕴含项值为1,同时让所有其它蕴含项值为0。比如对f=ab+cd来说,1100, 1101, 1110这3个测试输入点,都可以让蕴含项ab为1,让其它蕴含项为0。所以这3个点都是唯一真值点。类似的,0011, 0111, 1011也是唯一真值点,它们可以让cd为1,让其它蕴含项为0;
③ 假值点,指的是让整个析取范式值为0的测试输入点;
④ 近似假值点,指的是一种特殊的假值点,它可以让所有蕴含项值为0,但是如果将某个蕴含项中的某个条件取反的话,就可以让这个蕴含项值为1。比如对蕴含项ab中的条件a来说,近似假值点有3个:0100, 0101, 0110;对条件b来说,近似假值点也有3个:1000, 1001, 1010。同样,针对蕴含项cd中的条件,也可以找到对应的近似假值点。
为了确保检出LIF缺陷,我们可以定义“多项唯一真值点准则”:

也就是要求:对于每个蕴含项,测试集中都要包含这个蕴含项的多个唯一真值点,使得不在这个蕴含项中的条件的取值包括1和0。比如对f=ab+cd,满足该准则的测试集是{1101, 1110, 0111, 1011}:
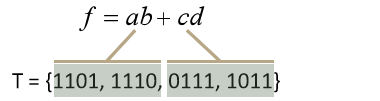
1101和1110是蕴含项ab的唯一真值点,而且这两个点上,c和d的取值都包括了1和0;0111和1011是蕴含项cd的唯一真值点,而且这两个点上,a和b的取值都包括了1和0。
为什么这样的测试集就能保证检出LIF缺陷呢?我们用一个例子来解释一下。假设蕴含项ab中错误地插入了一个条件,这个条件可能是a、b、c、d,或者它们的反,我们姑且记作l。这时候,f就被误写成了f'=abl+cd。
① 如果l是a或b,那么这个条件是冗余的,决策逻辑并不会受到影响;
② 如果l是a反或b反,那么测试集中的用例1101和1110的实际决策结果都是0,但是它们都是真值点,预期结果都应该是1,这样就能检出缺陷了;
③ 如果l是c或d反,那么用例1101的实际决策结果是0,跟预期不符,可以检出缺陷;
④ 如果l是c反或d,那么用例1110的实际决策结果是0,仍然可以检出缺陷。
可以看出,无论错误插入的条件是什么,满足多项唯一真值点准则的测试集,都能检出这个LIF缺陷。
另一方面,为了确保检出LOF缺陷,我们可以定义“近似假值点配对覆盖准则”:

也就是要求:对于每个蕴含项,测试集都要包含这个蕴含项的一个唯一真值点;同时,对于这个蕴含项中的每个条件,测试集都要包含一个近似假值点,这个近似假值点和前面唯一真值点的区别,只在于这个条件的取值。比如对f=ab+cd,满足该准则的测试集是{1100, 0100, 1000, 0011, 0001, 0010}:
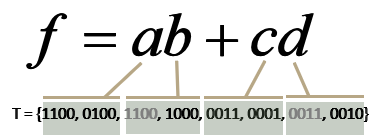
1100是蕴含项ab的唯一真值点,0100是条件a的近似假值点,它们俩的区别,只在于a的取值;1000是条件b的近似假值点,它跟唯一真值点1100的区别,只在于条件b的取值。关于c和d的覆盖情况跟ab类似。
为什么这样的测试集就能保证检出条件遗漏缺陷呢?假设是条件a被遗漏了,决策表达式就变成了f'=b+cd,0100是个近似假值点,它的预期结果应该是0,可实际结果却是1。其它条件被遗漏的情况也类似。因为准则要求每个条件都要有一个跟真值点配对的近似假值点,所以只要这个条件被遗漏了,对应假值点的实际结果就会变成1,我们就能检出缺陷。
不知道大家发现没有,近似假值点配对覆盖准则非常类似于我们前面讨论过的“修改的条件/决策覆盖准则”。针对每个条件,假值点和真值点的配对,完全可以满足“修改的条件/决策覆盖准则”的要求,也就是体现出“每个条件对决策结果的独立影响”。由此可见,从不同价值观出发的不同准则,有可能在具体要求上殊途同归。
如果一个测试集同时满足“多项唯一真值点准则”和“近似假值点配对覆盖准则”,这个测试集就能保证检出所有LIF和LOF缺陷,再根据缺陷之间的支配关系,它就能保证检出布尔逻辑中的全部九类典型缺陷。这就是“布尔逻辑缺陷检出准则”。

可以看到,这个准则的设计思路,就不像边界缺陷检出准则那样,仅仅着眼于缺陷本身的特征,而是更进一步,从缺陷之间的关系出发,力求检出更多的缺陷。通过这种基于缺陷结构的准则设计,我们可以很优雅地锁定全部敌人,然后扣下扳机。















 2475
2475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









