







如果在我们的价值观里,某些缺陷对被测对象来说是特别危险的、或者特别容易出现的,我们就可以采用基于缺陷的充分准则,来指导测试选择,保障测试集能够检出这些缺陷。
最典型的基于缺陷的充分准则就是“边界缺陷检出准则”。所谓“边界”,指的是分割测试中子空间的边界。那什么样的缺陷算是边界缺陷呢?比方说,被测程序期望里要求的是:“当a小于3的时候,怎么怎么处理”。可是程序实现的时候,这个决策被写成了a<2,或者a<4,这就是边界缺陷。更准确地说,这是“一维线性边界偏移缺陷”。
那如果我们希望排除这种缺陷,应该怎么做测试选择?
① 如果a<3被写成了a<2,那我们只需要选择a=2这个用例,就能发现实际结果和预期结果不一样;
② 如果a<3被写成了a<4,那我们只需要选择a=3这个用例,就能发现实际结果和预期结果不一样。
考虑另一种情况。假设期望的决策是a≤3:
① 如果程序里误写成了a≤2,那我们只需要选择a=3这个用例,就能发现实际结果和预期结果不一样;
② 如果程序里误写成了a≤3,那我们只需要选择a=4这个用例,就能发现实际结果和预期结果不一样。
其它的情况也类似,总结如下表:
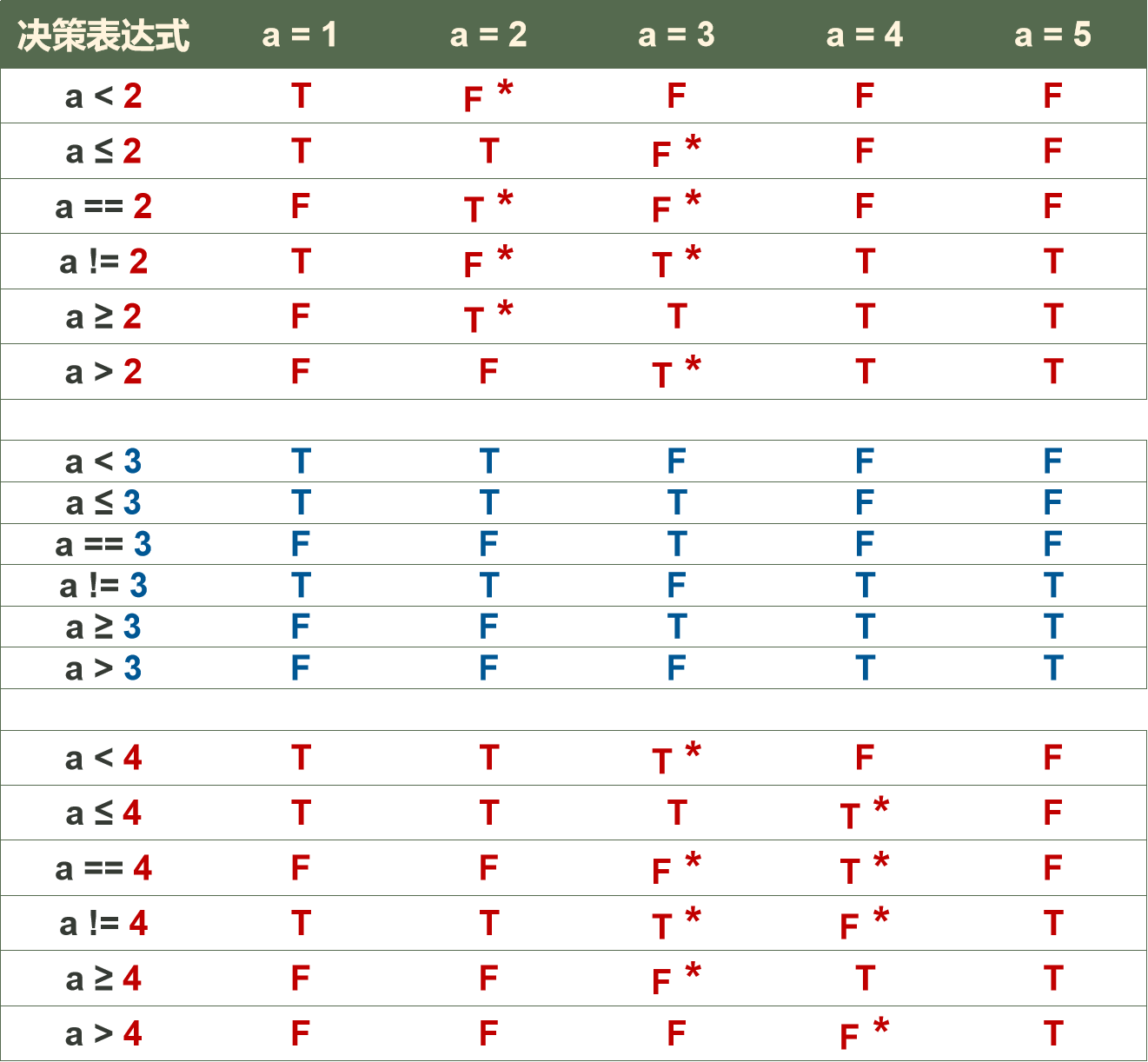
能检出缺陷的用例上都标了*号。可见,只要我们选a = 2、a = 3、a = 4这三个用例,就可以确保检出这一类缺陷。
到这里,我们就能够归纳出“一维线性边界偏移缺陷检出准则”了:

这个准则要求,测试集中至少包含刚刚小于边界值、刚刚大于边界值、等于边界值这三个用例。这也就是我们经常使用的“边界值测试法”。
接下来我们讨论稍复杂一点的二维边界。如果决策表达式涉及两个数值变量,比如a + 2b ≤ 10,这时子空间的边界就是二维线性边界。要想确保测试集能检出二维线性边界偏移缺陷,我们可以遵循这样的准则:

这个准则的要求有点多~我们用一个例子解释一下。假设我们根据被测对象期望,把测试输入空间分割成D1和D2两个子空间:
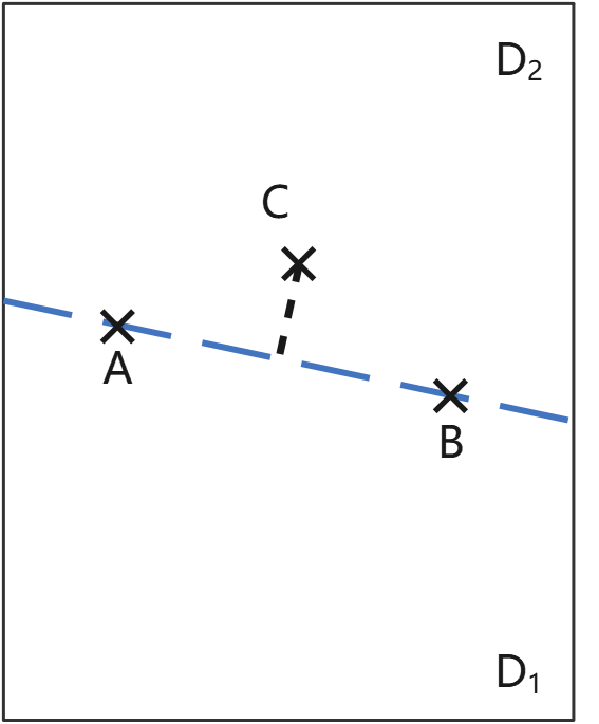
中间这条蓝色虚线就是期望的边界,假定这个边界是属于D1的。A和B就是两个“边界上点”。所谓“近边界点”,指的是与边界非常接近的一个点。近到什么程度呢?近到中间容不下其它的点。假定C就是这样一个近边界点,它属于D2,而且它在边界上的垂直投影位置,在A、B两点之间。所以,选择A、B、C这3个点,就可以满足准则的要求。
问题来了:为什么选这样3个点,就可以确保检出所有的二维线性边界偏移缺陷呢?我们来想一想,在这个例子里,边界可能发生什么样的偏移?
一共有6种可能的情况(下列各图中,红色实线代表程序里实际的边界,如果它跟蓝色虚线不重合,就说明存在边界偏移缺陷):
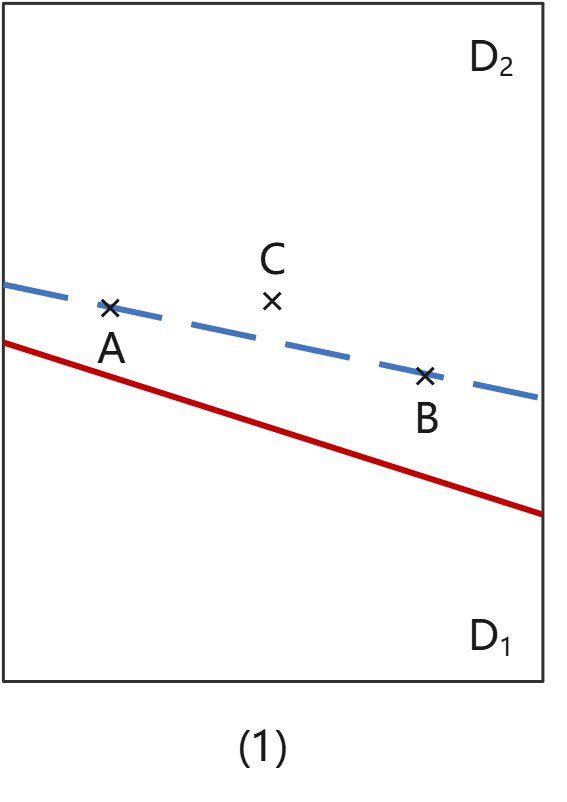
情况(1):A、B两个点本来应该是属于D1的,但是当这种边界偏移发生的时候,A、B会误入D2,实际测试结果就会跟预期结果不一致,我们就能够检出缺陷;
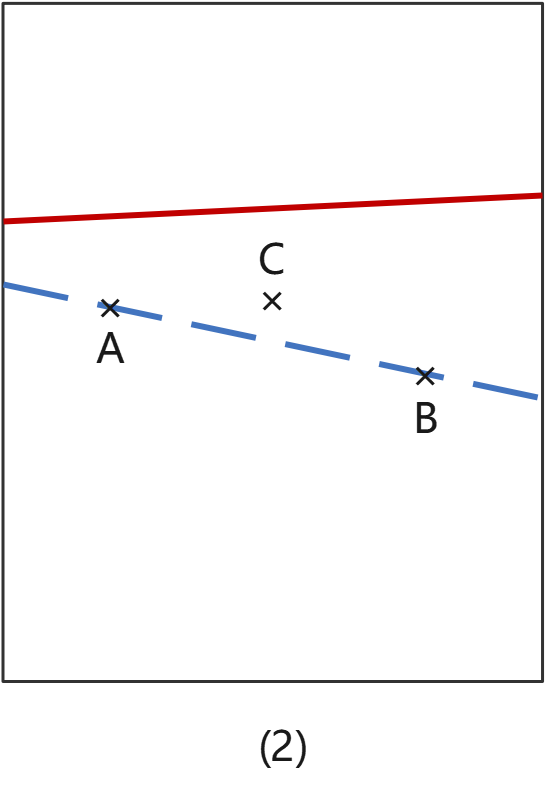
情况(2):C这个点本来应该是属于D2的,但是当这种边界偏移发生的时候,C会误入D1,它的测试结果就会跟预期不一致;
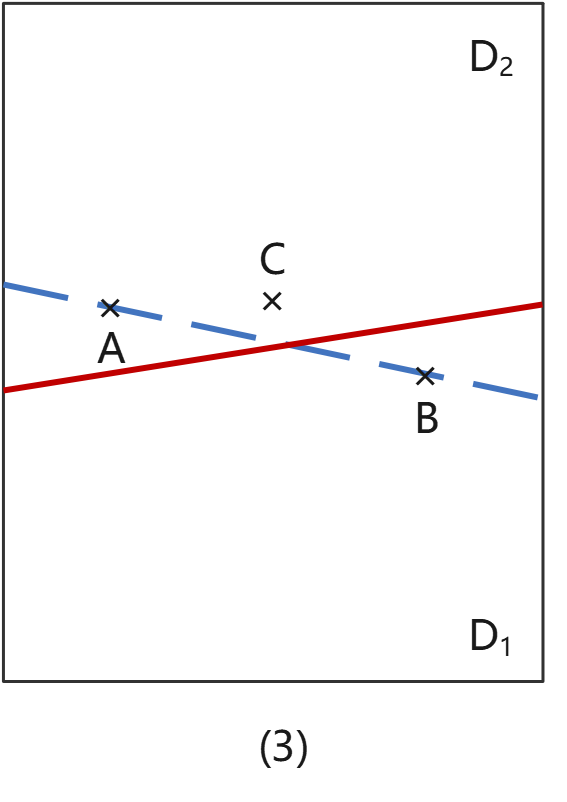
情况(3):A这个点会误入D2;
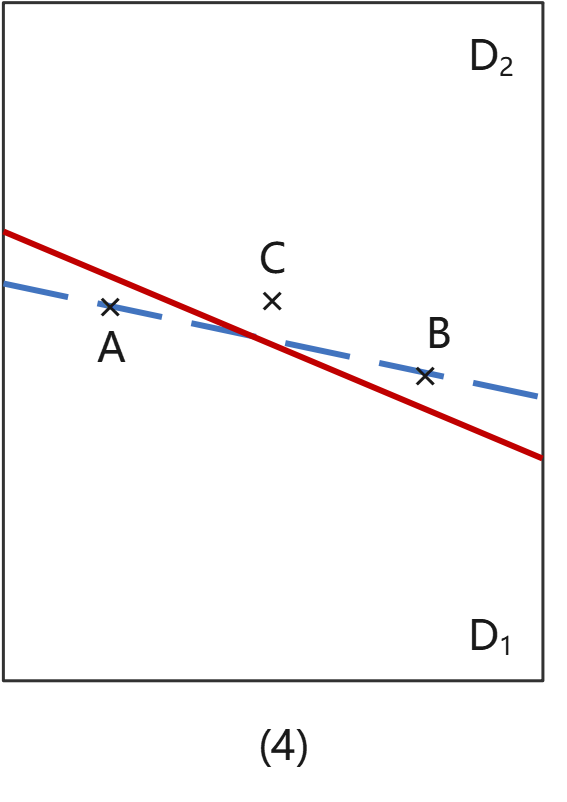
情况(4):B这个点误入D2;
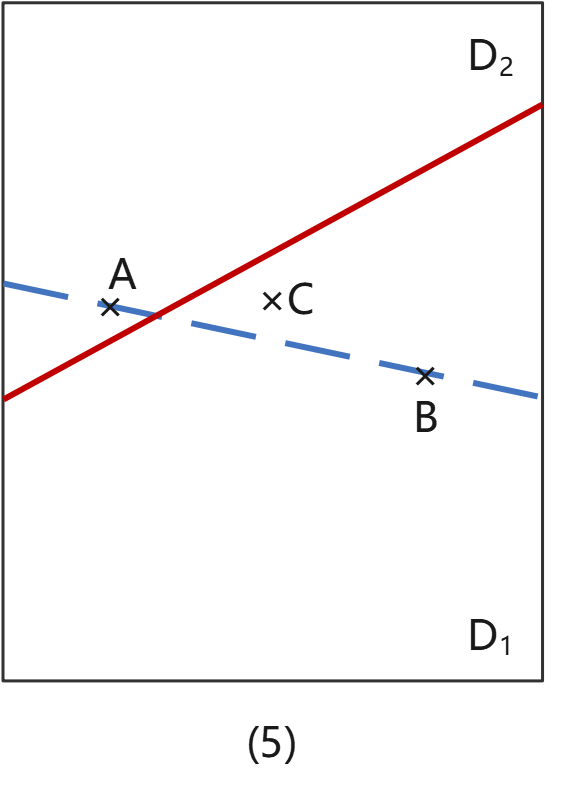
情况(5):A误入D2,C误入D1;
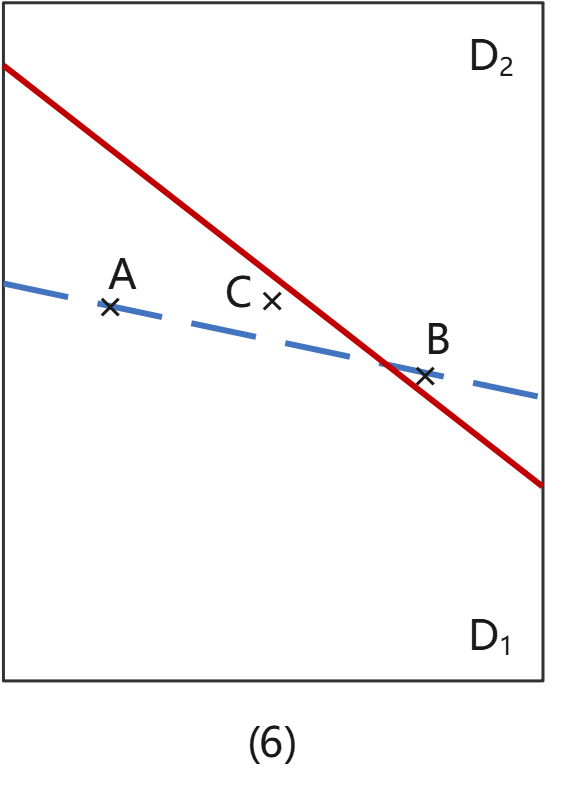
情况(6):B误入D2,C误入D1。
可见,只要我们选择了A、B、C这三个点,无论程序里发生哪种偏移,我们都能发现问题。
有的同学可能会问了,是不是落了一种情况啊?
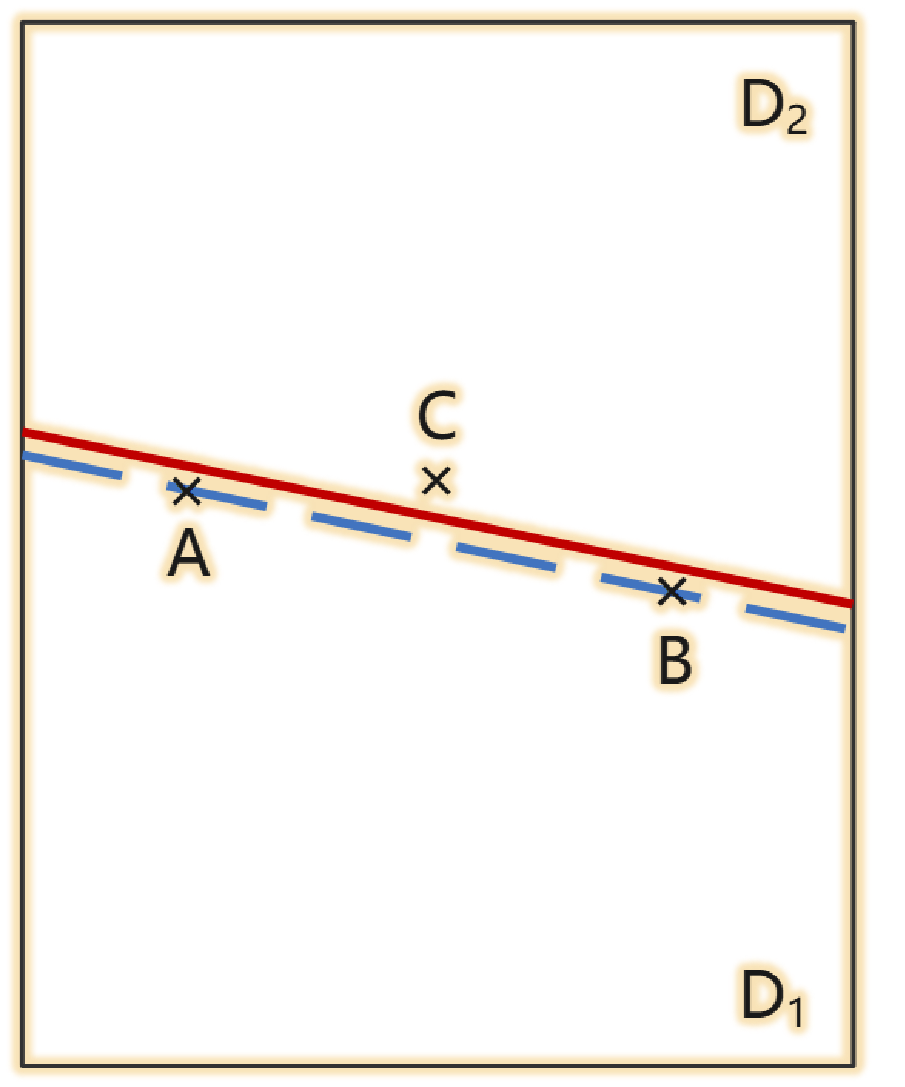
如果是这样的偏移,A、B还在D1里,C还在D2里,不是就没法检出缺陷了吗?实际上,这种情况是不会发生的,因为我们要求C是一个“近边界点”,它和边界之间距离很小,挤不下别的东西了。















 6248
6248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









