







论文阅读笔记:From Image-level to Pixel-level Labeling with Convolutional Networks
Introduce
Task
Weakly supervised learning for image semantic segmentation, only use image class label.
Contribution
- combine MIL(Multiple Instance Learning) with CNN
- performance state of the art
Framework
Train
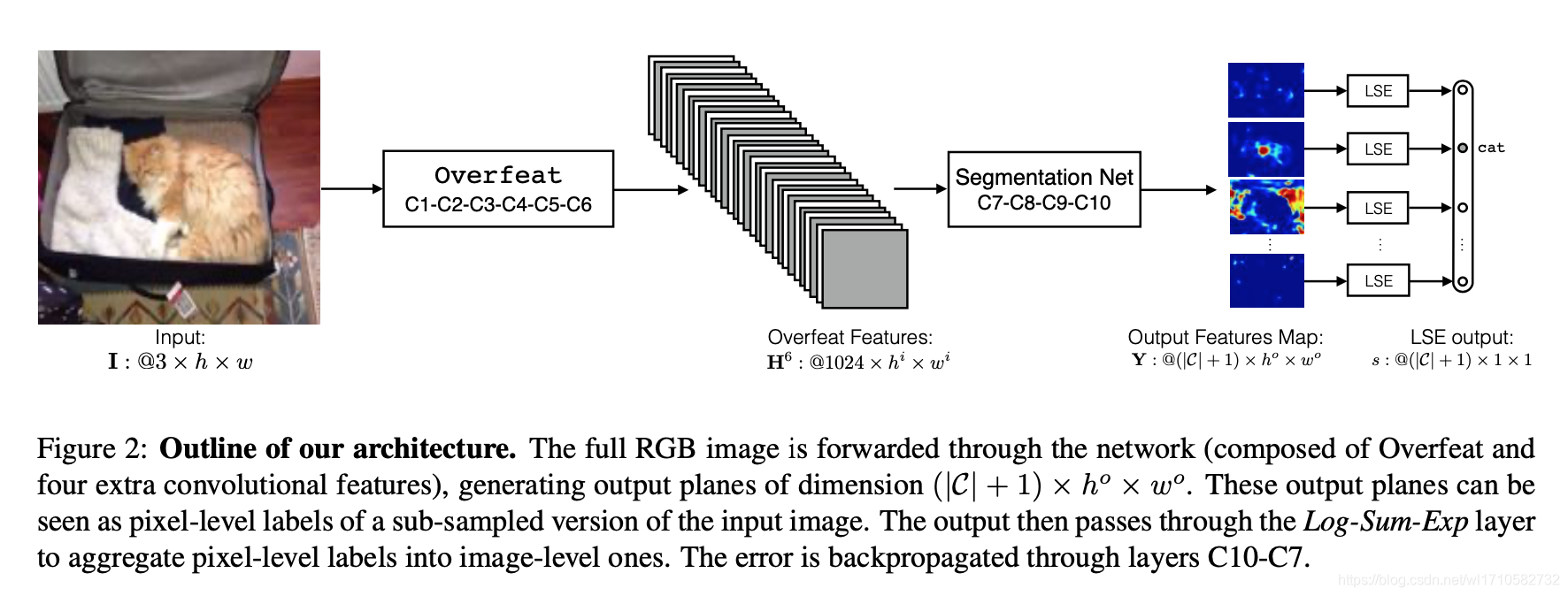 For input image
I
:
3
×
h
×
w
I:3\times h \times w
I:3×h×w, pass a backbone(i.e. Overfeat + Segmentation Net), output feature maps
Y
:
(
∣
C
∣
+
1
)
×
h
o
×
w
o
Y:(|C|+1) \times h^{o} \times w^{o}
Y:(∣C∣+1)×ho×wo, then
Y
Y
Y pass a LSE(Log-Sum-Exp) pooling, output
s
:
(
∣
C
∣
+
1
)
×
1
×
1
s:(|C|+1) \times 1 \times 1
s:(∣C∣+1)×1×1. Finally compute a softmax cross entrophy loss for
s
s
s, gradients backpropagation to train backbone.
For input image
I
:
3
×
h
×
w
I:3\times h \times w
I:3×h×w, pass a backbone(i.e. Overfeat + Segmentation Net), output feature maps
Y
:
(
∣
C
∣
+
1
)
×
h
o
×
w
o
Y:(|C|+1) \times h^{o} \times w^{o}
Y:(∣C∣+1)×ho×wo, then
Y
Y
Y pass a LSE(Log-Sum-Exp) pooling, output
s
:
(
∣
C
∣
+
1
)
×
1
×
1
s:(|C|+1) \times 1 \times 1
s:(∣C∣+1)×1×1. Finally compute a softmax cross entrophy loss for
s
s
s, gradients backpropagation to train backbone.
Inference

p
i
,
j
(
k
)
p_{i,j}(k)
pi,j(k) be the
Y
Y
Y for location
(
i
,
j
)
(i,j)
(i,j) and
k
t
h
k^{th}
kth class label. ILP
p
(
k
)
p(k)
p(k) be the
s
s
s by softmax.
y
^
i
,
j
=
p
i
,
j
(
k
∣
I
)
×
p
(
k
∣
I
)
\widehat{y}_{i,j}=p_{i,j}(k|I) \times p(k|I)
y
i,j=pi,j(k∣I)×p(k∣I)
Finally,
y
^
i
,
j
\widehat{y}_{i,j}
y
i,j pass a interpolation to restore input image resolution. Then use a threshold(Smoothing Prior) to get the final segmentation results.
Log-Sum-Exp(LSE)
s
k
=
1
r
log
[
1
h
o
w
o
∑
i
.
j
e
x
p
(
r
s
i
,
j
k
)
]
s^k = \frac{1}{r}\log \left[ \frac{1}{h^o w^o} \sum\limits_{i.j} exp\left( r s_{i,j}^k \right)\right]
sk=r1log[howo1i.j∑exp(rsi,jk)]
LSE is a pooling method for
Y
:
(
∣
C
∣
+
1
)
×
h
o
×
w
o
Y:(|C|+1) \times h^{o} \times w^{o}
Y:(∣C∣+1)×ho×wo to
s
:
(
∣
C
∣
+
1
)
×
1
×
1
s:(|C|+1) \times 1 \times 1
s:(∣C∣+1)×1×1, it is more smooth. When
s
s
s is high LSE similar to max pooling,
r
r
r low LSE similar to average pooling.
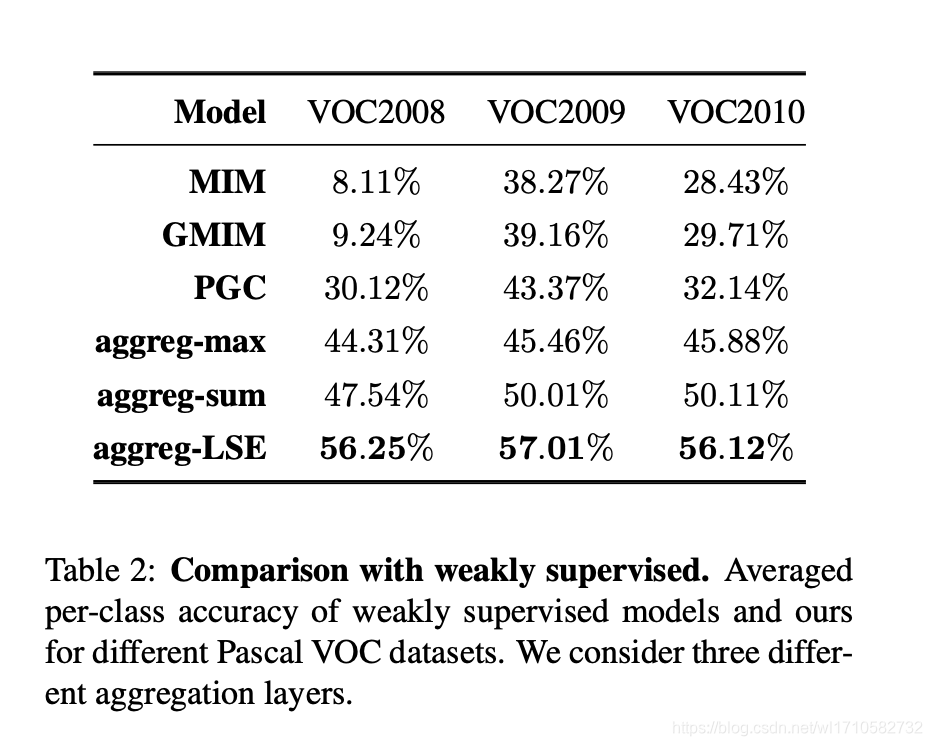
For accuracy, performance be more high compare to max pooling and sum pooling.
Summary
- LSE is smooth pooling than max and average pooling. Maybe it is useful.














 6148
6148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









