







文章目录
2. The GREW Dataset
2.1. Overview of GREW
\quad \quad
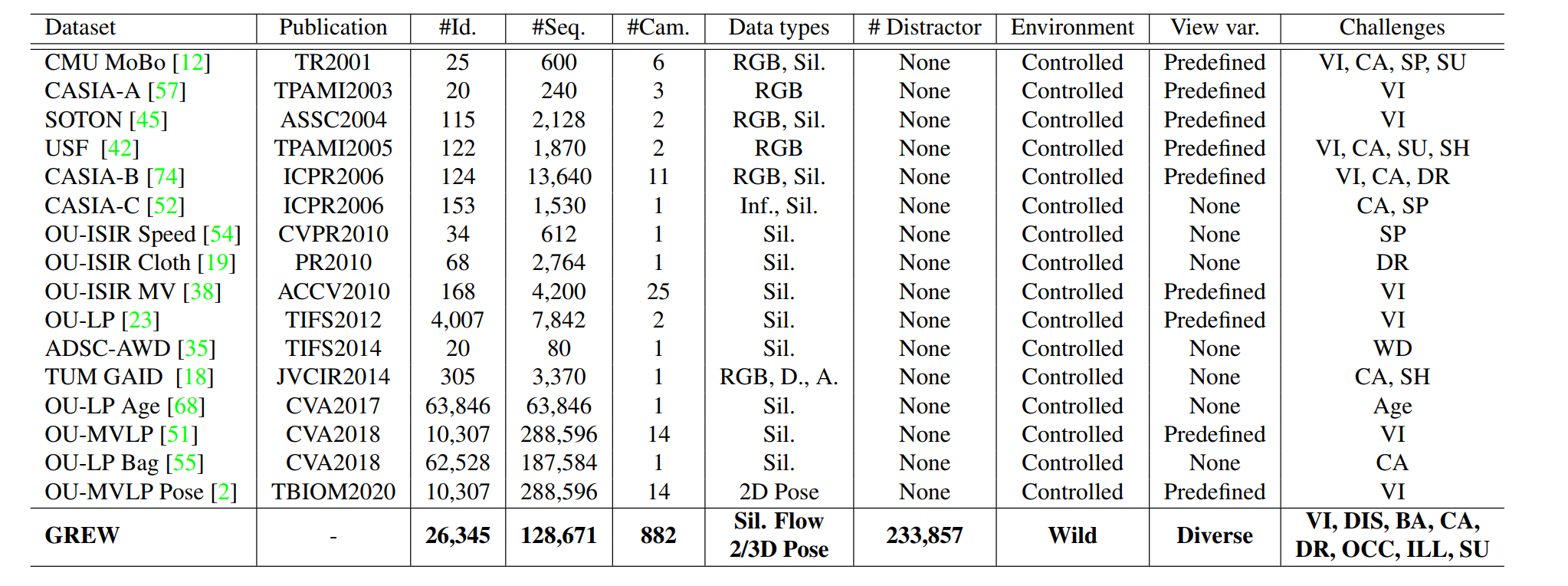
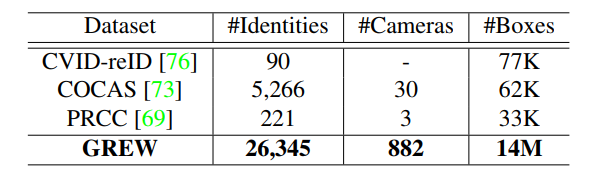
图1和表1分别说明了GREW和代表性步态识别数据集的定性和定量比较。GREW包括26,345个受试者和128,671个序列,它们来自开放环境中的882个摄像头。此外,作者提出了步态研究界的第一个干扰物集,其中包含233,857个序列。如图3所示,为基于外观和基于模型的算法提供了轮廓、GEI和2D/3D人体姿势数据类型。由于原始数据是在自然环境中采集的,与流行的CASIA-B和OU-MVLP相比,在GREW中通过步态识别身份更具挑战性。例如,考虑到遮挡、截断、光照等因素,从复杂的动态背景中检测和分割人体是一项困难的任务。如图2所示,不受约束的环境也给步态模式带来了新的挑战因素,如不同的视角、穿着、携带、拥挤人群和干扰物。


2.2. Data Collection and Annotation
\quad \quad 原始视频是在2020年7月的一天,从大型公共区域的882个摄像头收集的。大约70%的摄像头有不重叠的视角,所有的摄像头覆盖了600多个位置。作者得到了行政部门的授权,所有参与的受试者都被告知要为研究目的收集数据。使用7533个视频片段,包含近3500小时1080$\times$1920的视频流。
\quad \quad 在标注之前,执行 HTC 检测器以提供初始人体框。然后标注器从同一受试者中选择框作为轨迹(序列)。由于有多个摄像机,而且某个人可能进入/离开同一个摄像机视野,所以一个身份ID总是有多个序列。作者确保GREW训练集、验证集和测试集中的每个受试者都出现在1个以上的相机上,这保证了视角的多样性。如第2.5节所示,其它序列被用作干扰物集。
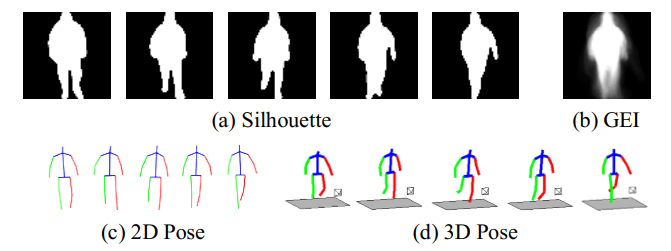
\quad \quad 在表1中,作者将GREW与之前的步态数据集在#身份、#序列、#相机、提供的数据类型、#干扰物集、环境、视角变化和挑战因素方面进行了比较。最后,人工标注了总共128,671 个序列,获得26,345个身份ID,其中包含14,185,478个人体框。目前GREW中的身份ID数比OU-LP Bag/Age少。此外,干扰物集包括233,857个序列和9,676,016个人体框。这个大量的标注标签需要20个标注器工作3个月,作者希望所提出的GREW基准将促进未来无约束步态识别的研究。值得注意的是,只有轮廓图、光流图和姿势图(如图3和4所示)将被使用和发布,其中不包含任何个人的视觉信息。
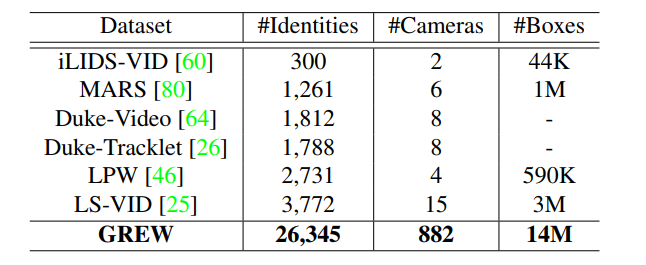
\quad \quad 与基于视频的和长期的行人重识别进行比较。大多数相关的计算机视觉任务是视频中的行人重识别和长期(衣服改变)的行人重识别。步态识别方法目的是通过轮廓(GEI)或姿势信息来识别某个受试者,而不是通过ReID中的RGB输入。这一特点使步态识别器在保护隐私方面更加友好,这可能更容易被公众接受。同时,步态模式更难伪装。此外,与流行的视频ReID和长期的ReID数据集相比,作者的GREW有更多的#身份ID和#摄像头,如表2和3所示。
2.3. Automatical Pre-processing
\quad \quad 有代表性的步态识别方法可以大致分为基于外观的和基于模型的两类,它们分别以轮廓(GEI)和人体姿势作为输入。在GREW基准中,作者通过自动预处理提供这两种数据类型。具体来说,轮廓是利用HTC算法分割前景人体来产生的。作者还尝试了Mask R-CNN,其结果是步态识别精度较差。值得注意的是,如图3所示,人体的检测和分割可能不太准确。与CASIA-B和OU-MVLP在静态背景下的近乎完美的结果相比,GREW能够评估较少启发式预处理对步态识别的影响。这是一个对实际应用有很大吸引力的话题,但在以前的数据集中很少考虑。对于GEIs,由于在野外检测和分割不完善,作者不采用步态周期。对于人体姿势的估计,提供二维和三维关键点,如图3所示。此外,提取光流以用于潜在用途,如图 4 所示。
2.4. Human Attributes
\quad \quad
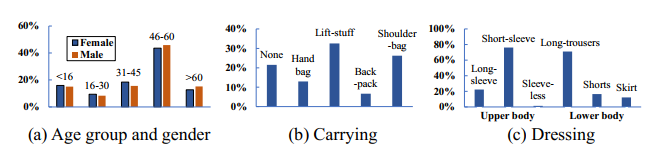
为了进行精细的识别分析,作者用丰富的属性对每个序列进行注释。包括性别和年龄在内的软性生物识别特征对所有受试者进行了标注。年龄分为5组,成人采用14年的间隔(即16至30岁,31至45岁,46至60岁)。儿童(16岁以下)和长者(60岁以上)被作为单独的群体对待。
图5中给出了性别和年龄组的统计。在每个年龄组中,男性和女性的分布基本平衡。由于携带和穿戴对步态模式的提取有影响,GREW基准进一步提供了5种携带条件(即没有、背包、肩包、手提包和提包)和6种穿戴方式(即上长袖、上短袖、上无袖、下长裤、下短裤和下裙)。图5显示了这些属性的详细统计。70%以上序列中的受试者携带东西,而上短袖和下长裤构成了大多数的穿衣风格。
2.5. Distractor Set
\quad \quad 在现实世界的步态识别应用中,gallery的规模是一个重要因素。因此,作者用一个额外的干扰物集进一步增强了GREW基准。这个数据集包含233,857个序列和9,676,016个框,由不属于GREW训练、验证和测试的额外行走轨迹组成。具体来说,那些被标记但只出现在1台摄像机上的身份将被归入干扰物集合。在第4.2节中,除了GREW测试集之外,我们还报告了GREW测试+干扰物集的基线结果。
2.6. Evaluation Protocol
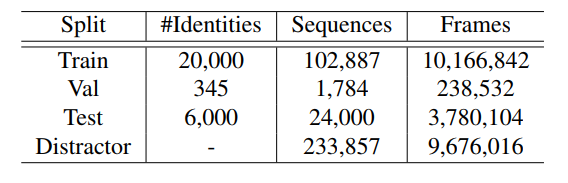
\quad \quad GREW数据集分为3个部分:一个有20,000个身份和102,887个序列的训练集,一个有345个身份和1,784个序列的验证集,一个有6,000个身份和24,000个序列的测试集。3组中的身份是在不同的相机中拍摄的。测试集中的每个受试者都有4个序列,2个用于probe,2个用于gallery。此外,还有一个有233,857个序列的干扰物集。拆分的详细统计数据见表4。
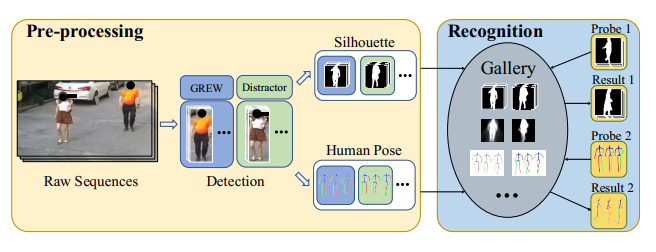
\quad \quad 如图6所示,在推理阶段,识别野外的步态首先要从原始视频中检测出受试者。然后执行分割或姿态估计模块以获得步态输入。步态识别始终是一个1:N的搜索过程,其目的是在给定一个探测受试者的情况下,从gallery中检索出同一个人。在测试集上进行评估时,步态probe和gallery都是成对的。当对某一属性进行评估时,会选择一个探针子集(具有相应属性的序列)来进行步态识别。作者采用普遍的Rank-k作为评价指标,它表示在前k个等级中至少找到一个正样本的可能性。
3. Baselines on GREW
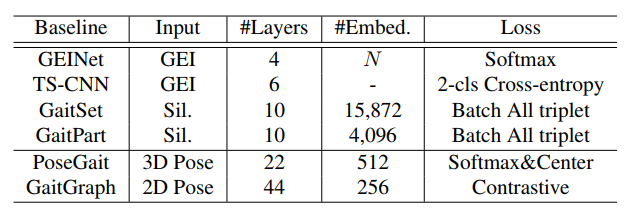
\quad \quad 为了建立基线,探索了有代表性的基于外观的方法和基于模型的方法。表5显示了输入类型、网络和损失的概况,详细说明如下。所有的模型都是在一个代码库中使用PyTorch重新实现的,并在集群上进行训练。(each with 8 × 2080TI GPUs, Intel E5-2630-v4@2.20GHz CPU, 256G RAM).对于GREW训练,作者对所有模型进行了25万次迭代训练,批次大小为(p=32,k=8)和优化器为Adam。学习率从 1 0 − 4 10^{-4} 10−4 开始,15万次迭代后下降到 1 0 − 5 10^{-5} 10−5。对于 CASIA-B 微调,模型以 1 0 − 5 10^{-5} 10−5 的恒定学习率进行额外 50K 次迭代训练。没有一个层的权重被冻结。
3.1. Appearance-based
GEINet直接从 GEI 学习步态表示特征,然后对应到身份。如表5所示,GEINet的网络有4层,由2个卷积层和2个全连接(FC)层组成。采用Softmax损失进行优化,并利用最后一个FC的输出来计算探针和图库之间的距离。
TS-CNN框架采用双流CNN架构,学习GEI对之间的相似性来进行步态识别。本文采用MT架构设置,在顶层匹配中层特征。TS-CNN也将GEI作为输入,有6层。2-class Cross Entropy loss 用于训练,而分类器表示两个受试者在推理过程中是否为同一受试者的概率。
GaitSet使用多个卷积和池化层在无序轮廓集上提取卷积模板。采用 Batch All triplet loss进行优化,并在推理过程中利用15,872维嵌入特征进行识别。遵循 OU-MVLP 训练设置,本文使用更多通道卷积层和 250K 次迭代和 2 个学习率计划。
GaitPart提出了一种基于部位的网络设计,专注于人体不同部位的细粒度表示和微运动捕捉。GRWE基准的训练和测试遵循GaitSet的大多数设置。
3.2. Model-based
PoseGait探索 3D 人体姿势作为步态识别输入,由 5 估计。并利用从47中提取的二维姿态来获得三维姿态信息。对于步态特征部分,训练了一个 22 层(20 个卷积和 2 个 FC)具有 512-d 嵌入的 CNN 进行提取,并通过 Softmax loss和Center loss进行了优化。
GaitGraph是最近的一种基于模型的步态识别方法,在CASIA-B上取得了很好的效果。这项工作结合了二维人体姿势输入和图卷积网络来实现步态识别。利用有监督对比损失对图网络进行优化,并严格遵循其扩充和训练细节。在评估过程中,提取 256 维特征向量用于计算probe和gallery之间的距离。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











