








带注意力的深度金字塔池化行人重识别
paper题目:Deep Pyramidal Pooling With Attention for Person Re-Identification
paper于2020年发表在TIP
paper地址:链接
Abstract
学习具有不同语义层次的目标外观的判别性、视角不变性和多尺度表示,对于行人重识别(ReID)是至关重要的。最近,社会各界都在关注学习深度Re-ID模型,以捕捉单一的整体表征。为了改善所取得的成果,人们考虑了额外的视觉属性和物体部分驱动的模型,这不可避免地引入了额外的人类注释工作或计算工作。本文认为受金字塔启发的捕捉多尺度信息的方法可以克服这些问题。确切地说,代表目标视觉信息的多尺度集合区域被整合到一个新的深度架构中,在多个语义层面上将其分解成可判别的特征。这些特征通过一个注意力机制被利用,后来被考虑在一个识别-相似性多任务损失中,通过分类学习策略进行训练。在三个ReID基准上的广泛结果表明,取得了比现有方法更好的性能。代码地址:链接。
索引词——行人重识别、金字塔表示、神经网络、深度学习。
I. INTRODUCTION
行人重识别 (Re-ID) 是关联由不相交的相机在不同时刻获取的目标的任务。由于视角变化、背景杂波和遮挡等开放挑战,该问题最近引起了越来越多的关注。
为了解决 Re-ID 问题,早期的工作要么寻求最佳特征表示,要么学习最佳匹配指标。最近,基于深度学习的方法将上述两种解决方案组合成一个架构,提出新颖特征表示或学习最佳度量的方法在基准数据集上获得了合理的性能。然而,用于表征学习(即深度特征/表征学习)和/或度量学习(即深度度量学习)的基于深度学习的解决方案目前在这个社区中占主导地位,与竞争对手相比具有令人信服的优势。
深度学习的表示带有高度判别的信息,特别是当这是从目标部分获得时。这通过部分知情的深度特征所取得的结果得到证实,这些特征不断提高最先进的 ReID 基准。这种方法取决于准确定位目标部分的能力。现有的解决方案应用基于关键点的身体部位划分策略、学习注意力机制,或考虑统一的划分方案。这些不需要部分标记,但性能与基于部分标记的方法相当。
事实上,语义目标分区为良好的对齐和随后的特征提取提供了稳定的线索。然而,获得这样的分区需要最佳的部分检测,这不可避免地会引入额外的计算工作。虽然可以通过在单个架构中加入类似注意力的机制来缓解这个问题,但现有方法没有考虑到目标分区在不同尺度上分析时可能具有不同的重要性。实际上,从本质上讲,图像包含许多大小的目标以及它们的代表特征。目标也可以与观察者有不同的距离。因此,单一尺度分析可能会遗漏其他尺度的相关信息。
本文假设这些挑战可以通过利用金字塔方法来解决。图像金字塔技术提供了一个有效的框架,反映了人类视觉系统中的多尺度处理。本文提出了一种新的方法,通过金字塔算子在不同细节层次(语义和视觉)上捕获图像相关性。具体来说,引入一种名为 PyrAttNet 的新型深度架构,该架构旨在掌握和利用金字塔信息来解决 Re-ID 问题。
具体来说,本文的贡献是一种新颖的连体架构,它:
- 能够通过提取不同细节级别(即不同网络深度)的信息来捕获属于输入的不同语义概念;
- 聚合在各个级别捕获的细节,以在单个模型中利用多个 Re-ID 决策;
- 采用结合身份和相似性学习的混合学习策略。
这些目标的实现如下。
- 金字塔池块在不同深度的深层架构中引入(第 III-C 节)。所提出的金字塔池化通过在不同尺度上处理图像来捕捉图像的不同细节。具体来说,引入了一种水平条纹池化策略,该策略捕获有关图像特征相对位移的信息。
- 堆叠在一起(第 III-D 节)并通过注意力机制(第 III-E 节)对获得的表示进行加权。这种纠缠的表示用于学习单个分类器,使模型能够查看具有不同细节级别和语义含义的特征。
- 混合学习策略(第 III-F 节)允许逐渐从识别任务转向相似性学习问题。首先获得一个稳健的人表示(识别任务),该表示经过修改,使其对于相似的人应该是相似的,否则是不同的(相似性学习任务)。
II. RELA TED WORK
Re-ID 社区目前非常活跃。在下文中,简要概述了与本文的方法最相关的工作。
-
手工制作的视觉特征:属于该组的工作通过设计有判别的外观特征描述符来解决 Re-ID 问题。多个局部和全局特征与patch匹配策略、显著性学习、迁移学习、点属性和面向相机网络的方案相结合。在这一类的所有方法中,迄今为止,使用最广泛的外观描述符是高斯高斯 (GOG) 、局部最大出现 (LOMO) 和重叠条纹加权直方图 (WHOS)。
-
最优匹配度量:在第二类中分组的方法学习最优的非欧几里得相异度量。具体来说,度量学习方法是通过强制执行正半定 (PSD) 条件、利用零空间或利用低秩解决方案来引入的。虽然大多数现有方法都捕获了相异空间的全局结构,但也提出了局部解决方案。随着这两种方法的成功,引入了将它们组合成集成的方法。通过提出学习列表和成对相似性,还研究了产生相似性度量的不同解决方案。
-
深度学习:目前,基准数据集上最好的 Re-ID 性能是通过基于深度学习的解决方案获得的。随着人体姿态估计的显著进步,提出了利用此类框架输出的方法。然而,姿势估计和 Re-ID 问题之间的概念差距并不能保证检测到的身体部位对于 Re-ID 任务是最优的。鉴于这些考虑,身体分割估计器已被放弃,取而代之的是考虑固定身体部位或注意力启发机制的方法。更具体地说,在 [11] 中,作者介绍了一个同时查看图像条纹的网络,然后通过基于部分的分类器单独考虑这些条纹。类似地,在 [47] 中,利用不同特征图的高度活跃位置来识别稍后用于部分损失计算的感兴趣区域。
本文提出学习和利用目标部分和基于多尺度的表示。不依赖于需要标记部分掩码/框数据的对象姿态估计框架。
尽管从水平身体条纹或在不同语义级别提取的信息中考虑特征的想法与本文的方法相同,但存在显著差异。具体来说,本文的整体架构介绍:
- 一个金字塔块,建立在任何主干架构上,可以捕获多尺度图像特征;
- 一种利用在架构不同深度获得的特征的解决方案,从而提供特定语义概念的信息。
- 一种从每个多级表示中选择最佳 Re-ID 特征的注意力机制;
- 一个单一的聚合目标函数,强制选择在不同细节级别提取的最佳特征
- 解决联合识别和相似性学习任务的分类学习策略。
III. PYRATTNET
本文的目标是拍摄几张图像并确定它们的相似性。为此,引入了一种新颖的深度架构,该架构通过组合通过金字塔方法获得的不同视觉细节来学习鲁棒的目标表示。然后将深度学习的视觉表示聚合成一个混合的识别相似性学习策略。所提出的架构如图 1 所示,其关键组件如下所述。

图 1. 提出的 PyrAttNet 架构。 siamese 网络一次处理一批三个元组,每个元组由一个图像和相应的标签组成。两个包含同一个人的数据(即 ( I a , y a ) \left(\mathbf{I}^{a}, y^{a}\right) (Ia,ya)和 ( I p , y p ) \left(\mathbf{I}^{p}, y^{p}\right) (Ip,yp)),而第三个(即 ( I n , y n ) \left(\mathbf{I}^{n}, y^{n}\right) (In,yn))包含为不同个人获取的数据。通过在不同深度引入的金字塔池化块获得多尺度和语义不同的特征。这些首先由注意力机制处理,然后 (i) 分别用于预测图像身份和 (ii) 共同考虑使从同一个人的图像中获得的表示“更接近”,并推动为不同的人生成的表示“更远”个人。
A. Notation and Definitions
令 I = { I } i = 1 n \mathcal{I}=\{\mathbf{I}\}_{i=1}^{n} I={I}i=1n其中 I ∈ R W × H × 3 \mathbf{I} \in \mathbb{R}^{W \times H \times 3} I∈RW×H×3是一组训练图像。还让 ( I a , y a ) , ( I p , y p ) \left(\mathbf{I}^{a}, y^{a}\right),\left(\mathbf{I}^{p}, y^{p}\right) (Ia,ya),(Ip,yp), 和 ( I n , y n ) \left(\mathbf{I}^{n}, y^{n}\right) (In,yn)表示锚点,正数和负数元组, y y y表示目标对象的身份。选择三个元组使得 y a = y p y^{a}=y^{p} ya=yp和 y a ≠ y n y^{a} \neq y^{n} ya=yn。对于每个图像,计算多个视觉特征表示以捕获不同的图像细节。给定一个表示为 l ∈ N l \in \mathbb{N} l∈N的细节层次和特征提取函数 f l : R W × H × 3 ↦ R d l f_{l}: \mathbb{R}^{W \times H \times 3} \mapsto \mathbb{R}^{d_{l}} fl:RW×H×3↦Rdl由一组可训练参数 W l \mathcal{W}_{l} Wl参数化, I \mathbf{I} I在第 l − t h l^{-th} l−th个细节层次上的特征表示为 x l ^ = f l ( I ; W l ) \widehat{\mathbf{x}_{l}}=f_{l}\left(\mathbf{I} ; \mathcal{W}_{l}\right) xl =fl(I;Wl)。
B. Backbone Architecture
最近的工作表明,如果卷积神经网络 (CNN) 在靠近输入的层和靠近输出的层之间包含较短的连接,则它们可以更深、更准确和更有效地训练。利用这些结果,提出的PyrAttNet建立在ResNet和DenseNet架构最近的成功之上。具体来说,它利用了构成每个此类架构的计算块生成的输出。这些输出被认为是应用金字塔池以提取 Re-ID 最相关信息的基础特征。鉴于此,将 l l l视为主干块的索引。
C. Striped Pyramidal Pooling Block
在许多尺度上分析图像的重要性源于图像本身的性质。世界上的物体包含许多大小的特征,因此仅在单一尺度上进行的分析可能会错过其他尺度的信息。图像金字塔方法提供了一个灵活的多分辨率框架,它反映了人类视觉系统中的多尺度处理。这可以捕获不同大小的对象和特征。在PyrAttNetarchitecture 中使用这种多尺度特征属性。
事实上,行人以直立的姿势行走。这在图像特征的相对位移中引入了一个约束(不希望腿部特征高于躯干特征)。为了捕捉这种关系,引入了条带池功能。这将给定的图像划分为水平条带,然后汇集它们的内容以捕获有关图像中特征垂直分布的信息。
在条带金字塔池化块 (SPPB) 中结合了金字塔框架和条带池化功能。它以不同的比例分析给定的特征图,从而在多个细节层次上捕获不同的特征(见图 2)。由主干架构的第 l − t h l^{-th} l−th个块生成的特征图,表示为 h l ∈ R W l × H l × k l \mathbf{h}_{l} \in \mathbb{R}^{W_{l} \times H_{l} \times k_{l}} hl∈RWl×Hl×kl,由金字塔池化函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)处理,该函数由金字塔层数 m l m_{l} ml参数化。 SPPB的输出是金字塔池化向量 x l \mathbf{x}_{l} xl。
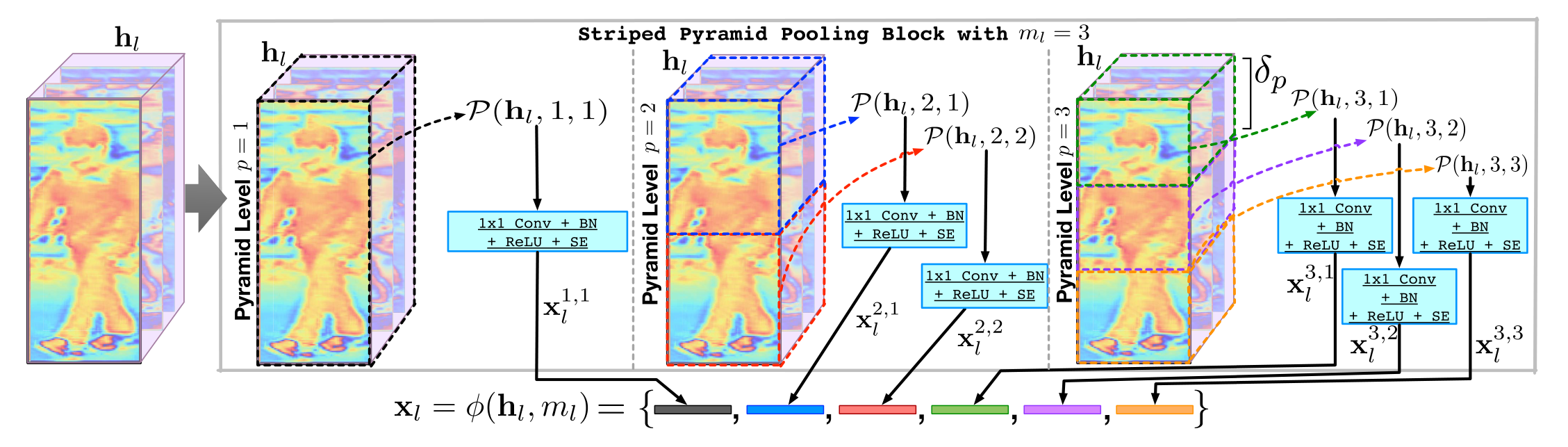
图 2. 条带金字塔池化块,其中显示了 m l = 3 m_{l}=3 ml=3金字塔级别的操作。在每个金字塔级别,输入特征图首先被划分为不重叠的条纹。每个这样的条纹都由全局池化、卷积和注意力操作独立处理。
更具体地说,在金字塔的
p
∈
{
1
,
⋯
,
m
l
}
p \in\left\{1, \cdots, m_{l}\right\}
p∈{1,⋯,ml}层,使用全局池化函数
P
(
⋅
)
\mathcal{P}(\cdot)
P(⋅)来投影第
i
i
i个条带,其中
i
∈
{
1
,
⋯
,
p
}
i \in\{1, \cdots, p\}
i∈{1,⋯,p}, 到
k
l
k_{l}
kl维向量上。和
h
l
p
,
i
,
c
=
h
l
(
:
,
(
i
−
1
)
δ
p
:
i
δ
p
,
c
)
\mathbf{h}_{l}^{p, i, c}=\mathbf{h}_{l}\left(:,(i-1) \delta_{p}: i \delta_{p}, c\right)
hlp,i,c=hl(:,(i−1)δp:iδp,c)
表示高度为
δ
p
=
H
p
\delta_{p}=\frac{H}{p}
δp=pH的第
i
i
i个条带的第
c
c
c个特征图,全局池化函数可以正式定义为
P
(
h
l
,
p
,
i
)
=
[
ψ
(
h
l
p
,
i
,
c
)
∣
c
∈
{
1
,
⋯
,
k
l
}
]
T
\mathcal{P}\left(\mathbf{h}_{l}, p, i\right)=\left[\psi\left(\mathbf{h}_{l}^{p, i, c}\right) \mid c \in\left\{1, \cdots, k_{l}\right\}\right]^{T}
P(hl,p,i)=[ψ(hlp,i,c)∣c∈{1,⋯,kl}]T
其中
ψ
(
⋅
)
∈
R
\psi(\cdot) \in \mathbb{R}
ψ(⋅)∈R是一个池化算子(例如,最大值/平均值)。
为了压缩通过 P ( ⋅ ) \mathcal{P}(\cdot) P(⋅)获得的数量或特征图并提高为每个条带生成的表示的质量,明确地对 P ( h l , p , i ) \mathcal{P}\left(\mathbf{h}_{l}, p, i\right) P(hl,p,i)中的 k l k_{l} kl元素之间的相互依赖关系进行建模。具体来说,首先通过具有 1 × 1 1 \times 1 1×1内核的 Convlayer 减少特征图的数量,然后是批量归一化 (BN) 和ReLU,生成 k ^ l \widehat{k}_l k l特征图。然后将生成的特征图提供给 Squeeze-and-Excitation (SE) 块,它允许网络执行特征重新校准,因此让它学会使用全局信息来选择性地强调信息特征并抑制不太有用的特征。通过这样的操作得到的向量是 x l p , i ∈ R k ^ l \mathbf{x}_{l}^{p, i} \in \mathbb{R}^{\widehat{k}_{l}} xlp,i∈Rk l
通过独立地将这些操作应用于所有金字塔级别的每个条带,得到金字塔池化向量 x l = ϕ ( h l , m l ) = [ x l 1 , 1 , x l 2 , 1 , ⋯ , x l m l , m l − 1 , x l m l , m l ] T \mathbf{x}_{l}=\phi\left(\mathbf{h}_{l}, m_{l}\right)=\left[\mathbf{x}_{l}^{1,1}, \mathbf{x}_{l}^{2,1}, \cdots, \mathbf{x}_{l}^{m_{l}, m_{l}-1}, \mathbf{x}_{l}^{m_{l}, m_{l}}\right]^{T} xl=ϕ(hl,ml)=[xl1,1,xl2,1,⋯,xlml,ml−1,xlml,ml]T。
D. Visual Concepts
CNN生成的特征在语义上与所考虑的深度水平相关(即,第一层响应颜色、边缘和角落,而更深的层由更复杂和抽象的特征激活)。因此,不同的层在检索具有特定特征的对象时具有不同的重要性。因此,主干架构在其第 l l l层的输出可能包含一组特征,这些特征表示语义上不同的概念,这些概念对 Re-ID 可能具有不同的重要性。
为了在提出的架构中加入这种直觉,在每个主干块的输出处添加了一个SPPB。然后,如图 1 所示,通过注意力机制利用每个此类块生成的特征。得到的向量首先被单独考虑用于身份损失,然后连接以获得用于相似性学习的纠缠表示,从而允许使用不同的视觉概念执行 Re-ID。
E. Attention
在不同细节级别(即,由不同的主干块)生成的输出向量提供了多个潜在语义特征表示。通过每个SPPB中的SE机制,对每个类特征执行一种自注意。但由于这对每个细节级别都是独立应用的,因此不能保证这些特征相互竞争以提供最佳的整体表示。事实上,虽然作者认为最高级别的语义可能是对 Re-ID 任务最有价值的语义(即,可以帮助区分穿着红色衬衫和绿色帽子的人和穿着红色衬衫的人并且背着一个蓝色的包),但可能有其他层携带的相关信息对Re-ID也有帮助。为了捕捉这种直觉并从所有多级语义特征中受益,引入了一个额外的注意力步骤,它共同考虑和加权在不同细节级别生成的表示。如图 3 所示,这是通过获取第三个主干块的输出并将其馈送到 IBN-a-ResNet 块来实现的。然后将得到的输出提供给 GAPoperator,然后由 FClayer 生成一个向量,该向量与在每个细节级别生成的所有金字塔表示的级联具有相同的大小。 BN 和 sigmoid 函数最终被用于压缩
[
0
,
1
]
[0,1]
[0,1]中的值。这样的权重向量表示为
w
=
[
w
1
,
⋯
,
w
L
]
T
\mathbf{w}=\left[\mathbf{w}_{1}, \cdots, \mathbf{w}_{L}\right]^{T}
w=[w1,⋯,wL]T其中每个
w
l
\mathbf{w}_{l}
wl也可以用金字塔级别和条带形式写成
w
l
=
\mathbf{w}_{l}=
wl=
[
w
l
p
,
i
∣
p
∈
{
1
,
⋯
,
m
l
}
∧
i
∈
{
1
,
⋯
,
p
}
]
T
\left[\mathbf{w}_{l}^{p, i} \mid p \in\left\{1, \cdots, m_{l}\right\} \wedge i \in\{1, \cdots, p\}\right]^{T}
[wlp,i∣p∈{1,⋯,ml}∧i∈{1,⋯,p}]T。这些用于计算
x
^
l
p
,
i
=
x
l
p
,
i
⊙
w
l
p
,
i
\widehat{\mathbf{x}}_{l}^{p, i}=\mathbf{x}_{l}^{p, i} \odot \mathbf{w}_{l}^{p, i}
x
lp,i=xlp,i⊙wlp,i
其中
⊙
\odot
⊙是哈达玛乘积。对所有
p
∈
p \in
p∈
{
1
,
⋯
,
m
l
}
\left\{1, \cdots, m_{l}\right\}
{1,⋯,ml}和
i
∈
{
1
,
⋯
,
p
}
i \in\{1, \cdots, p\}
i∈{1,⋯,p}
p
∈
p \in
p∈
{
1
,
⋯
,
m
l
}
\left\{1, \cdots, m_{l}\right\}
{1,⋯,ml} and
i
∈
{
1
,
⋯
,
p
}
i \in\{1, \cdots, p\}
i∈{1,⋯,p}计算上式得出
x
^
l
=
[
x
l
p
,
i
⊙
w
l
p
,
i
∣
p
∈
{
1
,
⋯
,
m
l
}
∧
i
∈
{
1
,
⋯
,
p
}
]
T
\widehat{\mathbf{x}}_{l}=\left[\mathbf{x}_{l}^{p, i} \odot \mathbf{w}_{l}^{p, i} \mid p \in\left\{1, \cdots, m_{l}\right\} \wedge i \in\{1, \cdots, p\}\right]^{T}
x
l=[xlp,i⊙wlp,i∣p∈{1,⋯,ml}∧i∈{1,⋯,p}]T
这反过来被认为是生成一个纠缠图像表示,该表示考虑了所有的注意力加权金字塔级特征以及不同主干块的输出。纠缠图像表示
x
^
∗
=
\widehat{\mathbf{x}}_{*}=
x
∗=
[
x
^
1
,
⋯
,
x
^
L
]
T
\left[\widehat{\mathbf{x}}_{1}, \cdots, \widehat{\mathbf{x}}_{L}\right]^{T}
[x
1,⋯,x
L]T。
F . Mixed Learning Strategy
最近的工作表明,可以通过使用身份损失微调现有架构来学习稳健的表示。其他工作表明,通过查看图像对或三元组的整体架构学习相似性度量,可以获得类似的结果。本文将这两种方案组合成一个联合身份相似性损失。
具体来说,作者分别考虑每个不同主干块生成的每个条带的特征来计算专用身份损失。这种方法用于让网络通过专注于可以在不同图像条纹中找到的特征来学习对输入数据进行分类。同时,考虑通过连接来自所有条带和每个主干块的特征获得的纠缠表示 x ^ ∗ \widehat{\mathbf{x}}_{*} x ∗用于相似性学习。有了这个,本文的目标是加强特征之间的竞争,以提供有判别的图像表示。
身份损失:给定一个特定的主干块,每个生成的
x
l
^
p
,
i
\widehat{\mathbf{x}_{l}} p, i
xl
p,i,其中
p
∈
{
1
,
⋯
,
m
l
}
p \in\left\{1, \cdots, m_{l}\right\}
p∈{1,⋯,ml}和
i
∈
{
1
,
⋯
,
p
}
i \in\{1, \cdots, p\}
i∈{1,⋯,p}被馈送到专用的 FClayer 以预测身份标签
y
^
l
p
,
i
\hat{y}_{l}^{p, i}
y^lp,i。这与ground truth标签
y
y
y一起考虑以计算交叉熵损失
L
c
e
(
y
^
l
p
,
i
,
y
)
\mathcal{L}_{\mathrm{ce}}\left(\hat{y}_{l}^{p, i}, y\right)
Lce(y^lp,i,y)。考虑所有主干块、金字塔层级和条带,用于网络优化的身份损失定义为
L
i
d
(
I
)
=
∑
l
=
1
L
∑
p
=
1
m
l
∑
i
=
1
p
L
c
e
(
y
^
l
p
,
i
,
y
)
\mathcal{L}_{\mathrm{id}}(\mathbf{I})=\sum_{l=1}^{L} \sum_{p=1}^{m_{l}} \sum_{i=1}^{p} \mathcal{L}_{\mathrm{ce}}\left(\hat{y}_{l}^{p, i}, y\right)
Lid(I)=l=1∑Lp=1∑mli=1∑pLce(y^lp,i,y)
相似度损失:anchor 的纠缠图像表示、三元组的正图像和负图像之间的边距排序损失计算为
L
sim
(
I
a
,
I
p
,
I
n
)
=
max
(
∥
x
^
∗
a
−
x
^
∗
p
∥
−
∥
x
^
∗
a
−
x
^
∗
n
∥
+
α
,
0
)
\mathcal{L}_{\operatorname{sim}}\left(\mathbf{I}^{a}, \mathbf{I}^{p}, \mathbf{I}^{n}\right)=\max \left(\left\|\widehat{\mathbf{x}}_{*}^{a}-\widehat{\mathbf{x}}_{*}^{p}\right\|-\left\|\widehat{\mathbf{x}}_{*}^{a}-\widehat{\mathbf{x}}_{*}^{n}\right\|+\alpha, 0\right)
Lsim(Ia,Ip,In)=max(∥x
∗a−x
∗p∥−∥x
∗a−x
∗n∥+α,0)
这种损失确保了正样本的表示比负样本的表示更接近锚样本,至少有一个margin
α
\alpha
α。
混合损失:然后将前面提到的两个损失结合起来得到混合损失
L
=
λ
L
sim
(
I
a
,
I
p
,
I
n
)
+
(
1
−
λ
)
/
3
∑
π
∈
{
a
,
p
,
n
}
L
i
d
(
I
π
)
\mathcal{L}=\lambda \mathcal{L}_{\operatorname{sim}}\left(\mathbf{I}^{a}, \mathbf{I}^{p}, \mathbf{I}^{n}\right)+(1-\lambda) / 3 \sum_{\pi \in\{a, p, n\}} \mathcal{L}_{\mathrm{id}}\left(\mathbf{I}^{\pi}\right)
L=λLsim(Ia,Ip,In)+(1−λ)/3π∈{a,p,n}∑Lid(Iπ)
其中
π
\pi
π表示锚点,三元组的正负元素和
λ
∈
[
0
,
1
]
\lambda \in[0,1]
λ∈[0,1]控制身份和相似性损失之间的权衡。
课程学习策略:作为人类,当要掌握的每个概念都以越来越复杂的程度呈现时,可以更容易地学习一组概念。因此,作者采用了课程学习策略[65]。在转向具有挑战性的相似性学习问题之前,最初专注于人员识别任务。这是通过以 1 / 1 / 1/#epochs 的步长增加 λ \lambda λ来实现的。
参考文献
[11] Y . Sun, L. Zheng, Y . Y ang, Q. Tian, and S. Wang, “Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline),” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 480–496.
[47] H. Y ao, S. Zhang, R. Hong, Y . Zhang, C. Xu, and Q. Tian, “Deep representation learning with part loss for person re-identification,” IEEE Trans. Image Process., vol. 28, no. 6, pp. 2860–2871, Jun. 2019.
[65] Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” in Proc. Int. Conf. Mach. Learn., 2009, pp. 41–48



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











