







用于行人重识别的局部卷积神经网络
paper题目:Local Convolutional Neural Networks for Person Re-Identification
paper是中国科学技术大学发表在MM 2018的工作
paper地址:链接
ABSTRACT
最近的工作表明,通过引入注意力机制可以显著改善行人重识别,该机制允许学习全局和局部表示。然而,所有这些工作都在不同的分支中学习全局和局部特征。因此,除了最终的特征嵌入层外,不允许全局和局部信息的交互/增强。本文提出将局部操作作为一个通用的构建块,用于在任何层中合成全局和局部信息。这个构建块可以插入到任何卷积网络中,只需少量关于局部部分的大致位置的先验知识。对于行人重识别任务,即使只插入一个局部块,局部卷积神经网络 (Local CNN) 也可以在三个大型基准测试(包括 Market-1501、CUHK03 和 DukeMTMC-)上始终优于最先进的方法。
1 INTRODUCTION
(ReID)可以跨多个摄像头或在单个摄像头内跨时间匹配同一个人,在计算机视觉社区中受到越来越多的关注。该技术广泛用于许多与视觉相关的应用,包括基于内容的视频检索、视频监控、CCTV 摄像机的识别等。与其他图像搜索任务相比,person ReID 仍然非常具有挑战性,原因如下:1) 来自不同相机的不同图像导致的剧烈背景变化,2) 人体姿势随时间和空间的变化导致视觉外观的显著变化, 3) 杂波或遮挡。这些挑战凸显了对行人 ReID 强大而健壮的功能的必然需求。
以前的行人 ReID 工作首先专注于提取低级特征,例如形状、局部描述符,后来转向使用卷积神经网络 (CNN) 进行端到端全局特征学习。此外,考虑到上述由多视角和不同相机引起的差异,许多工作都集中在开发注意力机制以减轻背景不一致的影响。这种方法背后的核心思想是将特征图乘以学习的注意力掩码,这不仅可以选择聚焦的前景,还可以增强所选目标的不同表示。然而,在不考虑人的空间结构和局部细节的情况下,全局特征对于以下情况的判别力不够。 1)面对姿势变化时,需要对人体局部部位进行更详细的表示。 2)很难区分全局特征中的局部差异,特别是当需要在两个外表非常相似的人之间进行匹配时。一个自然的选择是学习与全局特征互补的基于局部的详细局部特征,或者学习两者的特征嵌入。
由于人体由定义明确的部分组成,即头部、躯干和腿,解决姿势变化和局部差异引起的各种外观的更好方法是基于部分的模型。然而,以前的基于部分的模型将卷积神经网络分成几个分支,每个分支处理一个部分。然后,他们通过级联或特征嵌入来合并全局和局部特征。要将全局输入拆分为局部部分,一种广泛使用的方法是将输入图像或较低/最终卷积层中的全局输出分成相等的部分。另一种流行的方法是将全局特征图乘以学习的注意力掩码 [5, 20],作为重点局部部分的选择。此外,一些工作通过使用空间变换网络(STN)或区域提议网络(RPN)从全局输入中采样局部区域。具体来说,最近的工作试图通过软像素级掩码和局部区域采样的组合来提取局部部分。
为了合并全局和局部特征,最流行的方法是将它们连接到最终的全连接层。另一种方法是将全局和局部表示嵌入到一个固定长度的向量中。此外,仅在训练阶段合并局部特征或以分层方式融合局部特征也是可能的选择。然而,所有这些工作都在不同的路径中学习全局和部分特征。因此,不允许全局和局部信息的交互/增强,除非在最终的特征嵌入层中。直观地说,在卷积神经网络的构建块中合成不同信息路径的输出,这反映在 GoogleNet、ResNet和DenseNet的设计理念中,是改善backbone视觉的有效方法楷模。因此,考虑到人体的自然部分定义,基于集成全局特征和局部特征的构建块的卷积神经网络值得一试。这些架构的核心模式如图 1 所示。
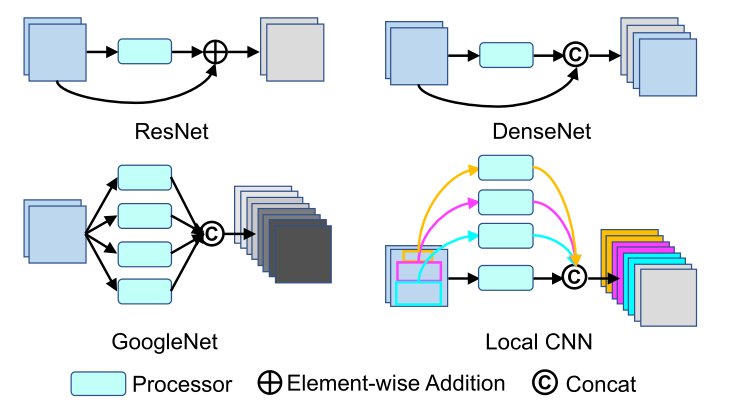
图 1:backbone CNN 中的块。处理器是包括批量归一化、ReLU、卷积和池化在内的复合。所有这些网络在每个构建块中合成不同路径的输出。与这些网络中的模块不同,本文的 Local CNN 模块尝试从不同路径合成局部和全局信息。
本文提出了一组局部操作作为通用构建块,用于在任何 CNN 层中合成局部和全局信息,称为局部 CNN。这个构建块可以插入到任何卷积模块中,只需少量关于局部部分的大致位置的先验知识。作为全局路径的补充,局部路径由四个组件组成:定位模块、采样模块、特征提取模块和融合模块。定位模块旨在定位头部、躯干和腿部的位置。采样模块被表述为一种显式的二维注意力形式,产生平滑变化的位置和尺度的局部切片。特征提取模块由几个卷积、ReLU和批量归一化层组成,就像一般的卷积块一样。特征提取模块的当前形式仅限于一个滤波器大小为 3 × 3 3 \times 3 3×3的卷积层。融合模块由全局和局部输出的串联层组成,然后是 1 × 1 1 \times 1 1×1卷积层。现有的backbone CNN 可以被视为全局路径,并且提出的局部路径可以很容易地插入到这些块中,而无需对训练方案进行任何更改。此外,局部操作中每个组件的架构对于不同的配置都非常灵活。
这项工作的主要贡献总结如下:
-
与 GoogleNet、ResNet 和 DenseNet 相比,本文为backbone CNN 设计了一个新的构建块,它融合了局部信息,称为局部卷积神经网络(Local CNN)。
-
本文为行人 ReID 实现了一种简单但有效的局部 CNN 形式。该模型在 Market-1501、CUHK03 和 DukeMTMCReID 三个大规模基准上优于最先进的基于注意力和基于部分的方法。
-
据作者所知,他们是第一个提出一个框架,该框架能够在 CNN 的任何层中实现全局和局部信息的交互/增强。
本文的其余部分的结构如下。第 2 节讨论了局部 CNN 和基于注意力或基于部分的人 ReID 模型的相关工作。第 3 节描述了所提出的局部 CNN 的体系结构和学习过程。与最新技术相比的广泛评估第 4 节报告了对提出方法的全面分析。第 5 节给出了结论。
2 RELATED WORK
基于注意力的模型。为了减轻背景不一致的影响,学习注意力掩码来选择一个集中的前景或目标。Liu等人提出了HydraPlus-Net,将多层次的注意力图谱多方位地反馈给不同的特征层,以捕捉从低层次到语义层次的多种注意力。Li等人提出了一个用于联合学习硬区域注意和软像素注意的和谐注意模型。在这个模型中,多个重点区域在不同的分支被处理,并在最后一层与全局特征合并。Zhao等人从最后的卷积特征中引入了一个无监督的部分注意步骤,以避免准确的身体部位定位。Ding等人提出了一个特征屏蔽网络。该网络采用高层次的特征来预测特征图mask,然后将其强加于低层次的特征上。Song等人学习了一个用于行人的重识别的掩码引导的对比性注意力模型。此外,Si等人提出了一个双注意匹配网络,其中注意策略被用于特征细化和特征对排列。
基于部位的模型。由于详细的部位信息对于匹配不同姿势的人或判别具有相似外观的不同人来说非常重要,因此已经提出了许多基于部位的模型。Cheng等人将低水平特征图水平划分为四个刚性块,并将每个块视为一个身体部位。应用多个通道来学习全身和局部身体部位的特征。Li等人将第一卷积层的输出特征图水平地划分为m个局部区域。局部区域和全局特征在不同的分支进行处理。Zhao等人提出首先根据身体关节检测定位身体部位,然后以分层的方式合并这些部位的特征。Li等人提出使用空间变换器网络(STN)学习和定位可变形的行人部分,并应用空间约束。Su等人明确地利用人体部位线索来缓解姿势变化,并从全局图像和不同的局部部位学习稳健的特征表示。同时,进一步设计了一个姿势驱动的特征加权子网络来学习自适应的特征融合。Zhang等人将最终卷积层的输出分成条状,并将其输入不同的分支。局部特征只在训练阶段使用。为了减轻缺失部分的影响,He等人使用流行的字典学习模型的重建误差来计算不同空间特征图之间的相似度。
Backbone CNNs。一般使用的backbone CNN显示,综合构建块中不同信息路径的输出,有助于改善视觉模型。Szegedy等人提出了一个初始模块,在构建块的不同路径中引入多尺度处理。然后通过串联将这些多尺度特征合并起来。He等人提出了一个残差学习框架,从层的输入到输出增加了一个捷径连接。在一个块中,来自捷径连接和卷积模块的信息通过元素相加的方式进行合成。在DenseNet中,前面各层的特征图被用作当前层的输入,而其自身的特征图被用作所有后续层的输入。 1 × 1 1 \times 1 1×1卷积、ReLU和批量归一化被用来合并所有层的特征图。
3 APPROACH
首先阐述了为什么需要在 CNN 的构建块中进行局部操作,然后是局部操作的一般定义。然后,提供了一个简单的局部 CNN 实例。最后,描述了用于person ReID基准测试的特定Local CNN模型。
3.1 Motivation
输入的失真或偏移会导致显著特征的位置发生变化。具有共享权重的局部感受野旨在检测不变的基本特征,尽管显著特征的位置发生了变化。因此,权重共享在卷积模块的设计中起着关键作用。一方面,权重共享确保可以提取特定的局部视觉模式,而不管它们的位置如何。另一方面,与目标的一个部分相对应的权重偶尔会在其他部分出现强烈的响应,这可以被视为噪声,如图 2 所示。这些意想不到的响应会越过块。为了消除其他部分的意外噪声响应,需要局部操作来提取构建块中部分的特定特征。直观地说,在 CNN 的构建块中合成不同信息路径的输出,这反映在 GoogleNet、ResNet和DenseNet的设计理念中,是改善backbone视觉模型的有效方法。因此,考虑到人体的自然部分定义,提出了基于集成全局特征和局部特征的构建块的 Local CNN。
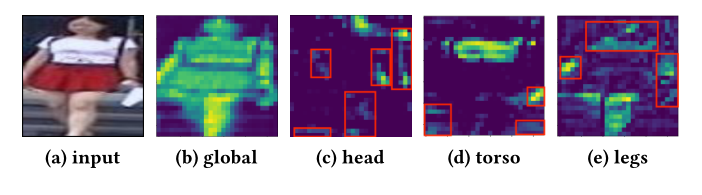
图 2:卷积构建块中权重共享的限制。 (a):输入图像,(b)-(e):backbone ResNet-50 行人ReID 模型中 block2 的输出特征图。红色边界框中的激活可以被视为其他部分的意外响应。
3.2 Formulation
考虑一个卷积构建块,输入 I \mathcal{I} I,操作的复合函数 F \mathcal{F} F,包括批量归一化、ReLU、卷积和池化,以及相应的输出 O O O。
GoogleNet。如图 1 所示,GoogleNet提取输入的多尺度特征并通过级联合并它们:
O
=
[
F
1
(
I
)
;
F
2
(
I
)
;
F
3
(
I
)
;
F
4
(
I
)
]
,
\mathcal{O}=\left[\mathcal{F}_{1}(\mathcal{I}) ; \mathcal{F}_{2}(\mathcal{I}) ; \mathcal{F}_{3}(\mathcal{I}) ; \mathcal{F}_{4}(\mathcal{I})\right],
O=[F1(I);F2(I);F3(I);F4(I)],
其中,不同的路径
F
i
(
I
)
\mathcal{F}_{i}(\mathcal{I})
Fi(I)被定义为卷积权重或池化操作的不同配置。
ResNet。ResNet增加了一个跳过连接,用一个恒等函数绕过了非线性变换:
O
=
F
(
I
)
+
I
.
\mathcal{O}=\mathcal{F}(I)+\mathcal{I} \text {. }
O=F(I)+I.
这里两条路径是复合函数
F
\mathcal{F}
F和恒等映射,所有路径的融合定义为加法。
DenseNet。在DenseNet中,输出端接收当前构建块中所有前面层的特征图,并通过级联将其合并:
O
=
[
F
(
I
)
;
I
]
.
\mathcal{O}=[\mathcal{F}(\mathcal{I}) ; \mathcal{I}] .
O=[F(I);I].
局部 CNN。为了确保全局和局部信息的提取和交互/增强,为局部部分添加路径,并通过级联和卷积融合全局和局部路径:
O
=
F
′
(
[
F
(
I
)
;
L
(
I
)
]
)
,
\mathcal{O}=\mathcal{F}^{\prime}([\mathcal{F}(\mathcal{I}) ; \mathcal{L}(\mathcal{I})]),
O=F′([F(I);L(I)]),
其中
L
\mathcal{L}
L表示结合了定位模块、采样模块、特征提取模块和融合模块的局部操作。
3.3 Instantiation
本文的局部 CNN 构建块的实例如图 3 所示。该块由一个全局路径(与其他backbone构建块一样)和几个局部路径组成。本文的局部操作有四个组件:定位模块、采样模块、特征提取模块和融合模块。现在详细说明局部路径的组成部分。
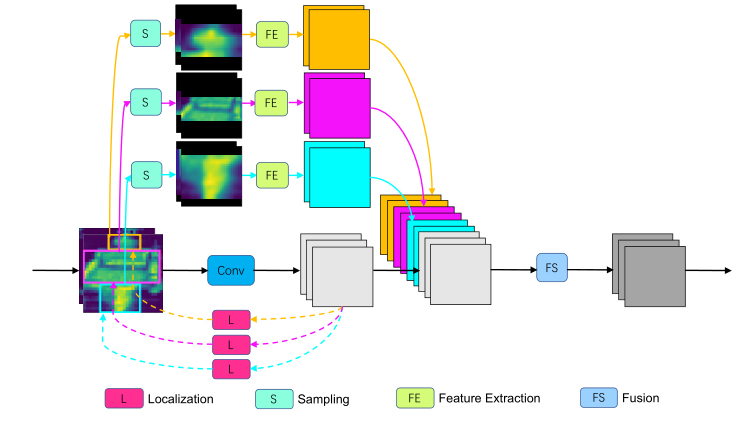
图 3:Local CNN 的构建块。有四个组件:定位模块、采样模块、特征提取模块和融合模块。定位模块旨在定位头部、躯干和腿部的位置。该模块由每个部分的中心位置 ( c x , c y ) \left(c_{x}, c_{y}\right) (cx,cy)参数化。采样模块被表述为一种显式的二维注意力形式。二维高斯滤波器阵列应用于输入,产生平滑变化的位置和尺度的局部切片。特征提取模块由几个卷积、ReLU和批量归一化层组成,就像一般的卷积块一样。融合模块形成为全局和局部输出的级联层,后跟 1 × 1 1 \times 1 1×1卷积层。
局部化模块。受 [7, 8] 中使用的可微注意力机制的启发,通过五个独立参数来指定定位模块:
(
Δ
x
,
Δ
y
,
δ
,
σ
2
,
γ
)
\left(\Delta x, \Delta y, \delta, \sigma^{2}, \gamma\right)
(Δx,Δy,δ,σ2,γ)。它们是针对每个输入动态确定的。
(
Δ
x
,
Δ
y
)
(\Delta x, \Delta y)
(Δx,Δy)是当前采样网格中心到相应部分的预定义中心的实值列和行偏移量。
δ
\delta
δ是采样网格的实值步长。
σ
2
\sigma^{2}
σ2是应用于输入的高斯滤波器的各向同性方差。
δ
\delta
δ和
σ
2
\sigma^{2}
σ2的组合控制局部部分的“缩放”,如图 4 所示。
γ
\gamma
γ充当乘以滤波器响应的置信度分数。理想情况下,
γ
\gamma
γ表示焦点部分的存在,即在面对遮挡时它应该接近于0。给定全局路径的
H
×
W
H \times W
H×W输出特征图,利用具有卷积、ReLU、批量归一化、最大池化和全连接层的卷积块来推断以下参数:
(
tanh
−
1
(
Δ
c
x
)
,
tanh
−
1
(
Δ
c
y
)
,
log
σ
2
,
log
δ
,
σ
−
1
(
γ
)
)
=
L
(
G
(
x
)
)
,
\left(\tanh ^{-1}\left(\Delta c_{x}\right), \tanh ^{-1}\left(\Delta c_{y}\right), \log \sigma^{2}, \log \delta, \sigma^{-1}(\gamma)\right)=\mathbf{L}(\mathbf{G}(x)),
(tanh−1(Δcx),tanh−1(Δcy),logσ2,logδ,σ−1(γ))=L(G(x)),
其中
G
\mathbf{G}
G是全局模块,
x
x
x是输入,
L
\mathbf{L}
L是定位模块
σ
(
γ
)
=
1
1
+
exp
(
−
γ
)
.
(
Δ
c
x
,
Δ
c
y
)
\sigma(\gamma)=\frac{1}{1+\exp (-\gamma)} .\left(\Delta c_{x}, \Delta c_{y}\right)
σ(γ)=1+exp(−γ)1.(Δcx,Δcy)被归一化并缩放到
(
−
1
,
1
)
(-1,1)
(−1,1)以确保网格中心位于采样输入中。方差和步幅以对数标度发出以确保正性。置信度分数
γ
\gamma
γ缩放到
(
0
,
1
)
(0,1)
(0,1)。定位模块的架构详见表 1。在输入和每个卷积层之后采用批量归一化和 ReLU 非线性。值得注意的是,为了确保全局路径仅关注表示,该模块的梯度不会传播到全局路径。
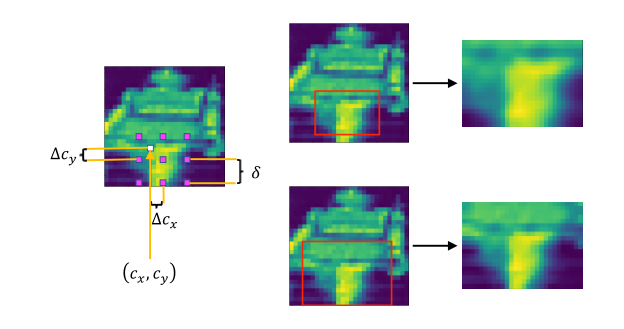
图 4:左:应用于输入的 3 × 3 3 \times 3 3×3滤波器网格。网格由 ( c x , c y ) , ( Δ c x , Δ c y ) \left(c_{x}, c_{y}\right),\left(\Delta c_{x}, \Delta c_{y}\right) (cx,cy),(Δcx,Δcy)和 δ \delta δ确定。右图:给定放大但模糊的腿部视图,顶部的切片有一个小的 δ \delta δ和一个高的 σ。底部贴片有一个大的 δ 和一个小的 σ \sigma σ,给出了完整而清晰的腿部视图。
采样模块。为了从给定的输入中采样局部切片,考虑了一种显式的二维形式的注意力,如 [8] 中所示。二维高斯滤波器阵列应用于输入,产生平滑变化的位置和尺度的局部补丁。给定预期的局部输出大小
M
×
N
M \times N
M×N,如图 4 所示,基于网格中心的坐标和相邻滤波器之间的步幅距离,将
M
×
N
M \times N
M×N高斯滤波器网格应用于输入。步幅越大,在注意力切片中可见的输入区域越大,但切片的有效分辨率越低。各向同性方差越大,输出的patch越平滑,但局部细节越不清晰。基于定位模块提供的归一化先验中心位置
(
c
x
,
c
y
)
\left(c_{x}, c_{y}\right)
(cx,cy)、偏移量
(
Δ
c
x
,
Δ
c
y
)
\left(\Delta c_{x}, \Delta c_{y}\right)
(Δcx,Δcy)和
δ
\delta
δ,滤波器在切片中第
i
i
i行第
j
j
j列的平均位置
(
μ
X
i
,
μ
Y
j
)
\left(\mu_{X}^{i}, \mu_{Y}^{j}\right)
(μXi,μYj)是:
μ
X
i
=
c
x
W
+
Δ
c
x
2
W
+
(
i
−
M
/
2
−
0.5
)
δ
,
μ
Y
j
=
c
y
H
+
Δ
c
y
2
N
+
(
j
−
N
/
2
−
0.5
)
δ
\begin{aligned} \mu_{X}^{i} &=c_{x} W+\frac{\Delta c_{x}}{2} W+(i-M / 2-0.5) \delta, \\ \mu_{Y}^{j} &=c_{y} H+\frac{\Delta c_{y}}{2} N+(j-N / 2-0.5) \delta \end{aligned}
μXiμYj=cxW+2ΔcxW+(i−M/2−0.5)δ,=cyH+2ΔcyN+(j−N/2−0.5)δ
其中
H
×
W
H \times W
H×W是块输入
I
\mathcal{I}
I的大小。
给定定位模块的
σ
2
\sigma^{2}
σ2输出,水平和垂直滤波器组矩阵
F
X
F_{X}
FX和
F
Y
F_{Y}
FY(分别为尺寸
M
×
W
M \times W
M×W和
N
×
H
N \times H
N×H)定义如下:
F
X
[
i
,
h
]
=
1
Z
X
exp
(
−
(
a
−
μ
X
i
)
2
2
σ
2
)
F
Y
[
j
,
k
]
=
1
Z
Y
exp
(
−
(
b
−
μ
Y
j
)
2
2
σ
2
)
\begin{gathered} F_{X}[i, h]=\frac{1}{Z_{X}} \exp \left(-\frac{\left(a-\mu_{X}^{i}\right)^{2}}{2 \sigma^{2}}\right) \\ F_{Y}[j, k]=\frac{1}{Z_{Y}} \exp \left(-\frac{\left(b-\mu_{Y}^{j}\right)^{2}}{2 \sigma^{2}}\right) \end{gathered}
FX[i,h]=ZX1exp(−2σ2(a−μXi)2)FY[j,k]=ZY1exp⎝⎜⎛−2σ2(b−μYj)2⎠⎟⎞
其中
(
i
,
j
)
(i, j)
(i,j)是注意力切片中的一个点,
(
h
,
k
)
(h, k)
(h,k)是输入中的一个点。
Z
X
Z_{X}
ZX和
Z
Y
Z_{Y}
ZY是确保
∑
h
F
X
[
i
,
h
]
=
1
\sum_{h} F_{X}[i, h]=1
∑hFX[i,h]=1和
∑
k
F
Y
[
j
,
k
]
=
1
\sum_{k} F_{Y}[j, k]=1
∑kFY[j,k]=1的归一化常数。
最后,根据定位模块提供的
(
F
X
,
F
Y
)
\left(F_{X}, F_{Y}\right)
(FX,FY)和置信度分数
γ
\gamma
γ,输出局部切片
L
(
I
)
\mathcal{L}(\mathcal{I})
L(I)计算为:
L
(
I
)
=
γ
F
Y
I
F
X
T
\mathcal{L}(\mathcal{I})=\gamma F_{Y} \mathcal{I} F_{X}^{T}
L(I)=γFYIFXT
在实践中,可以将期望的局部输出特征图的较大维度 ( max ( M , N ) ) (\max (M, N)) (max(M,N))设置为与全局输出相同,然后根据期望的高/宽比设置另一个维度。此外,用 0 填充采样切片以匹配全局路径的特征图的大小。
特征提取模块。如图 3 所示,特征提取模块用于提取局部路径的特征。所有类型的卷积块,例如 GoogleNet、ResNet 和 DenseNet,都是候选者。本文中特征提取模块的仅限于一个滤波器大小为 3 × 3 3 \times 3 3×3的卷积层,然后是 ReLU 和批量归一化,这种设计更多地基于方便性而不是必要性。特征提取模块中更复杂的架构可能会带来更大的性能提升,但这不是本文的重点。该模块的输出特征图的数量设置为全局路径的一半。
特征融合模块。特征融合模块旨在通过综合给定的全局和局部输出来产生更健壮和判别性的表示。在本文中,特征融合模块形成为全局和局部输出的连接层,然后是具有 ReLU 和批量归一化的 1 × 1 1 \times 1 1×1卷积层,它基于局部和全局信息的合成来细化表示,并确保基数保持不变。该模块的输出特征图的数量设置为与全局路径相同。
3.4 Local CNN for Person ReID
如上一节所述,要将Local CNN 块插入到backbone CNN 中,需要根据先验知识定义以下设置:1)局部路径的数量,2)采样网格中心的先验位置 ( c x , c y ) \left(c_{x}, c_{y}\right) (cx,cy),3) 每条路径的局部采样输出 ( M , N ) (M, N) (M,N)的预期维度。
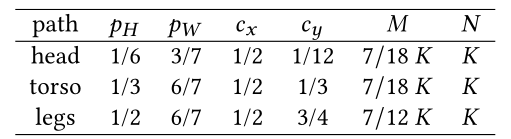
对于person ReID特征学习,定义头部、躯干和腿对应的3条局部路径是很自然的(如图3所示)。如[2]所述,人体头部、躯干和腿部的一般(高度、宽度)比例 ( p H , p W ) \left(p_{H}, p_{W}\right) (pH,pW)为 ( 1 / 6 , 3 / 7 ) , ( 1 / 3 , 6 / 7 ) (1 / 6,3 / 7),(1 / 3,6 / 7) (1/6,3/7),(1/3,6/7)和 ( 1 / 2 , 6 / 7 ) (1 / 2,6 / 7) (1/2,6/7)。因此,这 3 条局部路径的先验设置总结在表 2 中,其中 K × K K \times K K×K是全局路径的输出特征图的大小。填充应用于采样的切片以确保其大小为 K × K K \times K K×K。
表 2:头部、躯干和腿部路径的先前设置。 K × K K \times K K×K是全局路径的输出特征图的大小。填充应用于采样的切片以确保其大小为 K × K K \times K K×K。
为了验证 Local CNN 的有效性,我们将提出的局部操作插入到 ResNet-50 模型的每个构建块中。该框架如图5所示。训练配置的唯一变化是采用了采样步长
δ
\delta
δ的正则化损失。其公式如下:
δ
~
=
(
p
W
∗
W
∗
p
H
∗
H
)
/
(
M
∗
N
)
,
L
S
=
(
δ
−
δ
~
)
2
,
\begin{gathered} \tilde{\delta}=\left(p_{W} * W * p_{H} * H\right) /(M * N), \\ L_{S}=(\delta-\tilde{\delta})^{2}, \end{gathered}
δ~=(pW∗W∗pH∗H)/(M∗N),LS=(δ−δ~)2,
其中
δ
~
\tilde{\delta}
δ~是先前的步幅,
δ
\delta
δ是预测的步幅。
因此,训练损失计算为:
L
=
L
c
+
∑
(
λ
head
L
s
head
+
λ
torso
L
s
torso
+
λ
legs
L
s
legs
)
,
L=L_{c}+\sum\left(\lambda_{\text {head }} L_{s}^{\text {head }}+\lambda_{\text {torso }} L_{s}^{\text {torso }}+\lambda_{\text {legs }} L_{s}^{\text {legs }}\right),
L=Lc+∑(λhead Lshead +λtorso Lstorso +λlegs Lslegs ),
其中
L
c
L_{c}
Lc是分类损失,
∑
(
∑
λ
∗
L
s
∗
)
\sum\left(\sum \lambda_{*} L_{s}^{*}\right)
∑(∑λ∗Ls∗)表示所有块的所有路径中损失的总和。为简单起见,所有局部 CNN 都仅使用分类损失进行训练。
参考文献
[2] Barry Bogin and Maria Ines Varela-Silva. 2010. Leg Length, Body Proportion, and Health: A Review with a Note on Beauty. In International Journal of Environmental Research and Public Health, Vol. 7. 1047–1075.
[5] Guodong Ding, Salman Hameed Khan, Zhenmin Tang, and Fatih Porikli. 2017. Let Features Decide for Themselves: Feature Mask Network for Person Reidentification. CoRR abs/1711.07155 (2017).
[7] Alex Graves, Greg Wayne, and Ivo Danihelka. 2014. Neural Turing Machines. CoRR abs/1410.5401 (2014).
[8] Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Rezende, and Daan Wierstra. 2015. DRA W: A Recurrent Neural Network For Image Generation. ICML (2015), 1462–1471.
[20] Xihui Liu, Haiyu Zhao, Maoqing Tian, Lu Sheng, Jing Shao, Shuai Yi, Junjie Yan, and Xiaogang Wang. 2017. HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis. ICCV (2017), 1–9.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











