










DiffLoRA:通过扩散生成个性化低秩自适应权重
paper title:DiffLoRA: Generating Personalized Low-Rank Adaptation Weights with Diffusion
paper是电子科技大学发表在arxiv 2024的工作
paper地址
Abstract
个性化文本转图像生成因其能够根据用户定义的提示生成特定身份的高保真肖像而备受关注。现有方法通常涉及测试时微调或合并额外的预训练分支。然而,这些方法难以同时满足效率、身份保真度和保留模型原始生成能力的需求。在本文中,我们提出了 DiffLoRA,这是一种新颖的方法,它利用扩散模型作为超网络来根据参考图像预测个性化低秩自适应 (LoRA) 权重。通过将这些 LoRA 权重集成到文本转图像模型中,DiffLoRA 无需进一步训练即可在推理过程中实现个性化。此外,我们提出了一种面向身份的 LoRA 权重构建管道,以促进 DiffLoRA 的训练。通过利用该管道生成的数据集,我们的 DiffLoRA 始终如一地生成高性能和准确的 LoRA 权重。广泛的评估证明了我们方法的有效性,在整个个性化过程中既实现了时间效率,又保持了身份保真度。
Introduction
大规模文本到图像扩散模型的最新重大进展促使人们对其可定制性进行了广泛的研究(Ho、Jain 和 Abbeel 2020;Rombach 等人 2022;Song、Meng 和 Ermon 2020)。一个突出的重点领域是以人为中心的定制图像生成(Liu 等人 2024;Ruiz 等人 2024;Li 等人 2024;Wang 等人 2024b),由于其众多应用,包括具有自定义风格的个性化图像(Ren 等人 2022;Cui 等人 2024;Zhang 等人 2023)以及可控的人体图像生成(Wang 等人 2018;Zhou 等人 2022;Ju 等人 2023),该领域引起了广泛关注。这些应用程序背后的核心思想是将用户定义的主题集成到生成的图像中,使用户能够创建与其身份一致的个性化视觉效果。
为了满足这一需求,已经开发了各种用于文本到图像合成个性化的高级方法。一种重要的方法是使用特定参考图像对模型进行微调,如 (Ruiz et al 2023; Gal et al 2023; Kumari et al 2023; Avrahami et al 2023; Tewel et al 2023) 等著作中概述的那样。这些方法可以生成高保真图像,同时保持原始模型的功能。然而,它们需要大量的数据集和大量的训练,因此导致每个个性化的处理时间为 10 到 30 分钟,这使得它们对于以用户为中心的应用程序来说不切实际。相反,像 (Ye et al 2023; Wang et al
2024b; Li et al 2024; Xiao et al 2023; Valevski et al 2023; Wei et al 2023) 这样的研究通过合并额外的可训练条件分支,无需测试时微调即可实现个性化。虽然这些无需调整的方法提供了一种可行的替代方案,但它们往往会损害模型的保真度和多功能性,难以保持身份保真度和模型的原始生成能力 (Zeng et al 2024)。此外,与原始扩散模型相比,冻结原始扩散模型的权重以训练辅助可学习分支也会产生额外的训练成本并增加推理成本 (Ju et al 2023)。
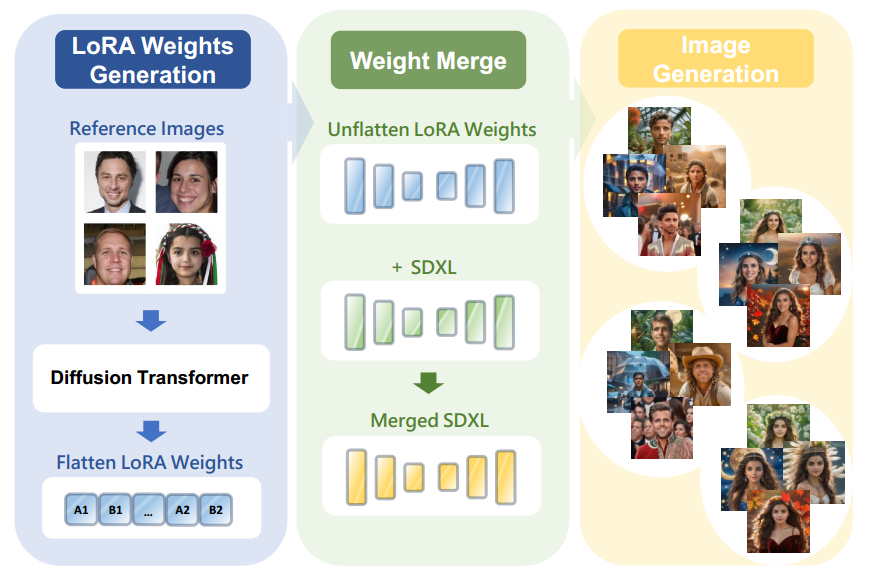
图 1:DiffLoRA 采用扩散变压器模型根据参考图像预测个性化 LoRA 权重,随后将其集成到 SDXL 模型中进行图像生成。
受低秩自适应 (LoRA) (Hu 等人 2022) 和超网络 (Peebles 等人 2022;Ha、Dai 和 Le 2022) 成功的启发,我们提出了一种基于潜在扩散的新型超网络框架,名为 DiffLoRA,旨在预测个性化的 LoRA 权重。与以前使用超网络生成特定组件(例如多层感知器 (MLP) 或规范化层)权重的方法不同(Erkoc¸ 等人 2023;Wang 等人 2024a),我们的框架提供了一个全面的解决方案,用于生成特定身份的 LoRA 权重,由参考图像引导,如图 1 所示。DiffLoRA 包含一个用于 LoRA 权重的自动编码器和一个专门针对 LoRA 潜在表示定制的扩散变压器模型。该框架利用混合专家启发 (MoE-inspired) 门网络 (Shazeer 等人 2016) 合成参考图像的面部和整体混合特征信息。在推理阶段,扩散模型利用这些混合特征作为条件输入来促进去噪过程。通过使用解码器重建生成的 LoRA 潜在表示,我们可以在稳定扩散 XL (SDXL) (Podell 等人 2023) 中获得特定身份适应的相应 LoRA 权重。与其他框架相比,这种基于潜在扩散的超网络框架能够预测更大规模的参数 (Wang 等人 2024a)。此外,扩散框架支持跨模态生成,通过迭代去噪实现比其他网络框架更稳定、更优越的结果 (Ruan 等人 2023;Zhang 等人 2024;Erkoc¸ 等人 2023)。通过将 DiffLoRA 生成的 LoRA 权重合并到 SDXL 中,该模型无需额外的微调即可实现个性化,同时保持身份保真度并保留原有的生成能力,而不会引入额外的推理成本。
我们的 DiffLoRA 框架需要在训练过程中为多个身份提供 LoRA 权重,因此需要专门的 LoRA 权重数据集的支持。但是,目前没有可用于特定身份的 LoRA 权重的标准数据集。为了解决这一空白,我们开发了一个自动化管道来构建针对各种身份量身定制的 LoRA 权重数据集,以促进 DiffLoRA 的训练。该管道通过处理具有不同表情、属性和场景的每个身份的图像来生成高质量的 LoRA 权重数据集,并利用 DreamBooth(Ruiz et al 2023)等技术进行模型训练。
我们的贡献总结如下:
- 据我们所知,我们首次尝试利用参考图像引导的扩散模型来生成 LoRA 权重,以实现个性化图像生成。这种无需调整的方法能够在推理过程中生成高保真的个性化肖像,而无需额外的计算成本。
- 我们提出了一种专门的 LoRA 权重自动编码器,用于 LoRA 权重压缩和重构。此外,我们引入了一个受 MoE 启发的门网络,该网络动态集成了详细的面部特征和一般图像特征,以增强身份提取。
- 我们引入了一种用于构建 LoRA 权重数据集的新管道,这增强了 DiffLoRA 训练并确保了广泛身份的表示。
- 综合实验表明,我们的方法在文本图像一致性、身份保真度、生成质量和推理成本方面明显优于现有的最先进方法。
Related Work
扩散模型中的个性化
使用扩散模型进行个性化图像生成在最近的研究中引起了广泛关注。扩散模型 (Nichol 和 Dhariwal 2021;Saharia 等人 2022;Ramesh 等人 2022) 使用预训练的文本编码器(如 CLIP(Radford 等人 2021))将文本提示编码到潜在空间中。稳定扩散 (Rombach 等人 2022) 及其高级版本 SDXL (Podell 等人 2023) 通过增强的架构提高了计算效率和图像质量。早期的个性化方法,如 DreamBooth (Ruiz 等人 2023) 和文本反转 (Gal 等人 2023),需要针对每个主题进行大量微调。最近的技术通过添加分支在推理过程中注入身份信息来提供无需微调的个性化(Wang 等人
2024b;Li 等人 2024;Wei 等人 2023)。我们的 DiffLoRA 方法可以预测并将参考图像中的 LoRA 权重加载到 SDXL 中,从而消除重新训练。由于 LoRA 是一种通用的微调方法,因此 DiffLoRA 可以集成到现有的参数高效微调 (PEFT) 方法中,从而实现跨各种任务的灵活应用。
参数生成
参数生成,即通过超网络预测模型参数(Ha、Dai 和 Le 2022),已经取得了重大进展。超网络动态生成模型权重,提供灵活性和效率。最近,扩散模型已被用作超网络框架,从而产生更稳定和更优越的结果。例如,(Zhang et al 2024;Erkoc¸ et al 2023;Peebles et al 2022)表明,与其他框架相比,作为超网络的扩散模型可以产生更好的结果。这些方法利用扩散模型的优势来预测网络权重。此外,这种方法的可扩展性允许与其他技术无缝集成,使其非常适合个性化图像生成(Ruiz et al 2024)。在我们的研究中,我们研究了 LoRA 相对于 MLP 的优势,随后设计了一个新颖的扩散模型框架以与目标 LoRA 权重保持一致。
Preliminaries and Motivation
本节确立了我们研究的基本概念和动机。“准备工作”部分探讨了潜在扩散模型 (Rombach 等人,2022) 的核心原则,这些原则构成了我们提出的方法的基石。“动机”部分全面分析了为什么 LoRA 权重相对于 MLP 权重具有更高的效率和更易于拟合。
Preliminaries - Latent Diffusion Models
LDM 是针对潜在表示而非原始样本进行操作的扩散模型。图像通过 VAE 投影到潜在表示中(Kingma 和 Welling 2013;Razavi、Van den Oord 和 Vinyals 2019)。扩散过程发生在这些潜在表示上,由逐步去噪的条件引导。目标是使用类似于 vanilla 扩散模型中的损失函数(Ho、Jain 和 Abbeel 2020;Song、Meng 和 Ermon 2020;Sohl-Dickstein 等人 2015),尽量减少预测噪声与每个时间步注入的实际噪声之间的差异,公式如下:
L
L
D
M
=
E
t
,
z
,
ϵ
[
∥
ϵ
−
ϵ
θ
(
α
t
‾
z
0
+
1
−
α
t
‾
ϵ
,
c
,
t
)
∥
2
]
L_{\mathrm{LDM}}=\mathbb{E}_{t, z, \epsilon}\left[\left\|\epsilon-\epsilon_\theta\left(\sqrt{\overline{\alpha_t}} z_0+\sqrt{1-\overline{\alpha_t}} \epsilon, c, t\right)\right\|^2\right]
LLDM=Et,z,ϵ[
ϵ−ϵθ(αtz0+1−αtϵ,c,t)
2]
其中, z 0 z_0 z0 是训练样本 x 0 x_0 x0 的潜在表示, ϵ \epsilon ϵ 是实际噪声, ϵ θ \epsilon_\theta ϵθ 是模型在时间步 t t t 的噪声估计。这里, c c c 表示条件嵌入, α t ‾ \overline{\alpha_t} αt 是一个保留方差的系数。通过引入条件引导的嵌入,模型能够生成多样且与上下文相关的潜在表示,这对各类下游任务至关重要。
Motivation - Why Predict LoRA Weights?
在本节中,我们提供了一个详细的理论分析,解释了为什么 LoRA 权重相比 MLP 权重更容易预测。我们认为,低秩结构的效率及其受限的分布范围是这种优势的重要原因。
LoRA 的低秩结构通过将权重更新 Δ W ∈ R m × n \Delta W \in \mathbb{R}^{m \times n} ΔW∈Rm×n 分解为两个低秩矩阵 B ∈ R m × r B \in \mathbb{R}^{m \times r} B∈Rm×r 和 A ∈ R r × n A \in \mathbb{R}^{r \times n} A∈Rr×n,将所需参数从 m × n m \times n m×n 显著减少到 ( m + n ) × r (m+n) \times r (m+n)×r,其中 r ≪ min ( m , n ) r \ll \min (m, n) r≪min(m,n)。前向传递方程为:
W ′ ( x ) = W 0 ( X ) + B ( A ( x ) ) + b , W^{\prime}(x)=W_0(X)+B(A(x))+b, W′(x)=W0(X)+B(A(x))+b,
其中, Δ W = B A \Delta W=B A ΔW=BA 是更新项。如 (Biderman et al. 2024) 所述,LoRA 更集中和稳定的参数分布通过降低过拟合风险,促进了更好的泛化能力。LoRA 权重的这种受限分布范围也便于其压缩和重构,使其相较于全秩 MLP 更为高效,能够在相同的计算资源下实现更好的重构质量。
为了更好地证明我们的理论主张,我们设计了一个专注于低秩特征压缩和重构的玩具实验。按照 (Prasantha、Shashidhara 和 Murthy 2007) 概述的使用奇异值分解 (SVD) (Klema 和 Laub 1980) 进行图像压缩的方法,我们对来自 FFHQ 数据集 (Karras、Laine 和 Aila 2019) 的几张人脸图像执行 SVD,并提取前几个维度的低秩矩阵以获得低秩特征。该方法利用 SVD 有效压缩能量和捕获局部统计变化的能力,从而有效地压缩成低秩特征 (Guo 等人 2015)。
随后,我们训练两个具有相同架构的卷积自动编码器,分别重建全秩和低秩特征。在训练过程中,两个自动编码器都旨在重建输入特征。一旦在低秩特征上训练的自动编码器收敛,我们就会使用峰值信噪比 (PSNR) 和结构相似性指数 (SSIM) 指标 (Hore and Ziou 2010) 评估两个模型的重建质量。如图 2 所示,结果表明,重建低秩特征的自动编码器在 PSNR 和 SSIM 中均实现了更高的值,表明重建质量更高。相比之下,在相同训练条件下在全秩特征上训练的自动编码器表现明显较差。补充材料中提供了有关我们的小实验的更多细节。
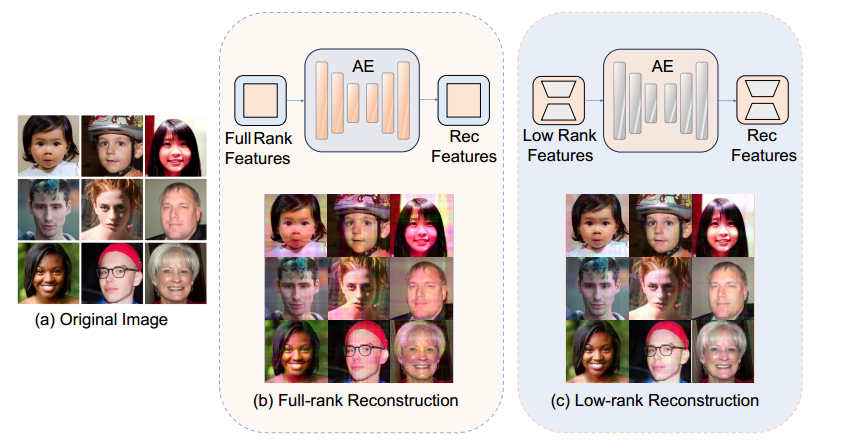
图 2:一个玩具实验,用于演示低秩特征更易于压缩和重构。训练两个具有相同参数的自动编码器分别重构全秩和低秩特征。在测试中,低秩特征使自动编码器能够以相同的配置实现卓越的重构质量。
这一实证证据支持了我们的假设,即低秩特征更容易压缩和重建,并且推而广之,LoRA 权重更容易预测。
Method
LoRA 权重生成
给定参考图像,DiffLoRA 旨在通过利用 LoRA 权重自动编码器 (LAE) 结合扩散模型来有效生成准确的 LoRA 权重。这种方法避免了与双分支架构相关的额外训练成本,同时通过 LoRA 权重生成和权重合并实现高保真图像生成。我们首先详细介绍了 LAE 的构造,以将 LoRA 权重压缩到潜在空间中。接下来,按照 (Erkoc¸ et al 2023),我们描述了我们的扩散变换器 (DiT) 模型训练,以直接预测编码的 LoRA 潜在表示,而不是噪声。然后,我们引入了混合图像特征 (MIF) 机制来整合图像中的面部特征和图像特征,指导 DiT 模型进行去噪过程。最后,我们概述了用于生成适应多个身份的 LoRA 权重的数据集构建流程。图 3 概述了我们的训练和推理过程。
LoRA 权重自动编码器
如图 3 所示,LoRA 权重自动编码器 (LAE) 旨在有效压缩和重建 LoRA,特别针对 LoRA 固有的结构和信息相关性。
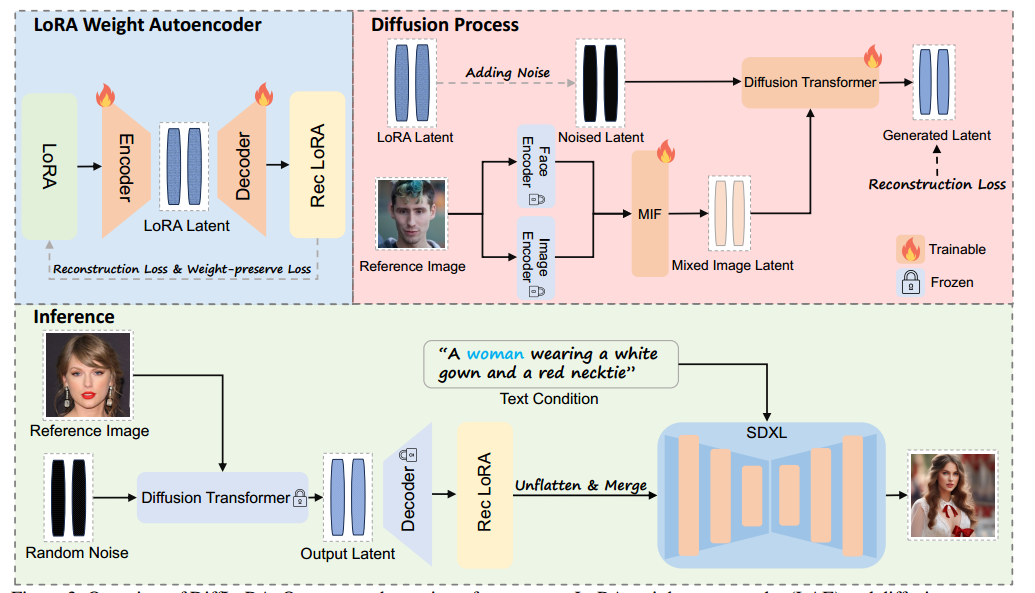
图 3:DiffLoRA 概览。我们的方法包括两个阶段:LoRA 权重自动编码器 (LAE) 和扩散过程。
LAE 编码并重建 LoRA 权重。在扩散过程中,人脸编码器和图像编码器提取的特征与混合图像特征 (MIF) 机制相结合,产生的噪声潜在特征由扩散变换器处理以预测去噪潜在特征。在推理过程中,随机噪声和参考图像被输入到 DiffLoRA 中以生成新的 LoRA 权重。
关于结构特征,不同于图像,LoRA 权重的形状并不一致,其中 LoRA-A 的形状为 R r × n \mathbb{R}^{r \times n} Rr×n,而 LoRA-B 的形状为 R m × r \mathbb{R}^{m \times r} Rm×r,这就需要进行展平操作。为了最大化保留潜在空间中的结构信息,我们直接展平 LoRA-B,并翻转 LoRA-A 以获得形状为 R n × r \mathbb{R}^{n \times r} Rn×r,然后再展平。最终得到的一维向量会被连接起来,作为 LAE(潜在自编码器)的输入。随后,我们采用一维卷积层作为主要的压缩层,以捕捉 LoRA 权重的结构特征。
关于LoRA权重的信息特征,我们深入分析了不同大小的LoRA参数对最终生成图像的影响。我们将LoRA中的参数按大小排序,并将它们分成四个比例组:第一组代表大权重,最后一组代表小权重。随后,我们将大权重和小权重设置为零,或者用按比例缩放的噪声扰动它们。如图4所示,扰动或将小权重设置为零对生成的图像影响不大,而对大权重执行相同操作会显著降低身份保真度。

图 4:说明扰动或将 LoRA 权重设置为零对生成图像的影响的示例。
该分析表明,较大的 LoRA 权重往往包含有关特定身份的更精确信息。因此,为了在压缩和重建过程中增强较大权重的重建,我们提出了一种称为权重保留损失的新型损失函数来训练 LAE。权重保留损失被纳入原始重建损失中,专门针对较大的权重。我们的 LAE 中权重保留损失的实现由以下公式给出:
L
W
P
=
1
n
∑
i
=
1
n
∣
x
i
∣
⋅
∣
x
i
−
x
^
i
∣
L_{\mathrm{WP}}=\frac{1}{n} \sum_{i=1}^n\left|x_i\right| \cdot\left|x_i-\hat{x}_i\right|
LWP=n1i=1∑n∣xi∣⋅∣xi−x^i∣
其中, n n n 是参数的数量, x i x_i xi 表示第 i i i 个参数, x ^ i \hat{x}_i x^i 表示第 i i i 个重建的参数。 ∣ x i ∣ ⋅ ∣ x i − x ^ i ∣ \left|x_i\right| \cdot\left|x_i-\hat{x}_i\right| ∣xi∣⋅∣xi−x^i∣ 这一项强调了较大权重的重建误差。通过将保权损失(Weight-Preserved Loss)集成到训练过程中,我们的方法确保了较大权重中编码的身份信息能够更加准确地被保留,从而显著提升了重建后生成图像的质量。此外,我们的 LAE 可以将原始 LoRA 权重压缩近 300 倍,展现了卓越的压缩与重建性能。
混合图像特征 (MIF)。MIF 的核心概念是利用面部细节和一般图像信息来更好地提取身份特征,从而提高去噪过程的准确性。MIF 受到 Mixture-of-Experts (MoE) 结构 (Shazeer et al 2016) 的启发,将图像特征和面部特征与门网络相结合。整体工作流程如图 5 所示。
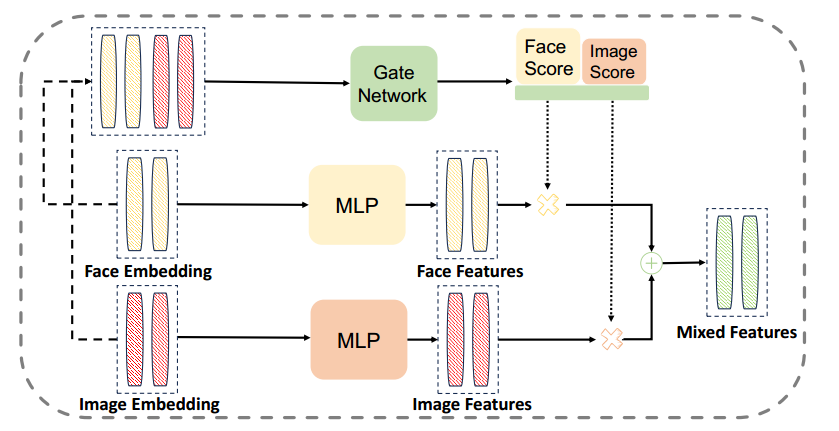
图 5:我们的 MIF 由受 MoE 启发的门网络组成,将人脸嵌入和图像嵌入组合成混合特征,以改进身份特征提取。
我们首先从 InsightFace 编码器 E face E_{\text {face }} Eface (Deng 2022) 提取用于身份识别的包含面部细节的嵌入,并从 CLIP 图像编码器 E img E_{\text {img }} Eimg (Radford et al. 2021) 提取包含整体外观的图像嵌入,这些嵌入是基于参考图像 I I I 得到的。接着将这些嵌入拼接,获得包含更全面身份信息的混合嵌入。
通过将混合嵌入 M M M 输入门控网络 G G G,我们可以获得表示面部特征重要性的面部得分 S face S_{\text {face }} Sface ,以及表示图像整体特征重要性的图像得分 S img S_{\text {img }} Simg 。基于这些得分,可以计算混合特征 F F F。MIF 的前向过程可以表示为:
F = S img ⊙ M L P ( E img ( I ) ) + S face ⊙ M L P ( E face ( I ) ) F=S_{\text {img }} \odot M L P\left(E_{\text {img }}(I)\right)+S_{\text {face }} \odot M L P\left(E_{\text {face }}(I)\right) F=Simg ⊙MLP(Eimg (I))+Sface ⊙MLP(Eface (I))
其中 ⊙ \odot ⊙ 表示标量乘法, S img S_{\text {img }} Simg 和 S face S_{\text {face }} Sface 是门控网络 G ( M ) G(M) G(M) 的输出。具体地, G ( M ) = G(M)= G(M)= Softmax ( f ( M ) ) (f(M)) (f(M)),函数 f f f 可以是一个线性层。
去噪过程: Transformers 在处理语言领域中的长序列表现出色,因此是用于建模 LoRA 潜在表示的理想选择 (Erkoç et al. 2023)。我们的扩散模型基于 DiT 架构,设计用于处理加入噪声的 LoRA 潜在表示,并随后预测出原始的潜在表示。此外,我们使用自适应层归一化 (AdaLN) 机制,将混合特征引入到扩散过程中以进行引导。
在扩散建模过程中,我们优化模型 M θ M_\theta Mθ 的参数 θ \theta θ 以最小化均方误差 (MSE) 损失:
L ( θ ) = E t , x 0 , c [ w t ∥ M θ ( α t x 0 + σ t ϵ , t , c ) − x 0 ∥ 2 ] L(\theta)=\mathbb{E}_{t, x_0, c}\left[w_t\left\|M_\theta\left(\alpha_t x_0+\sigma_t \epsilon, t, c\right)-x_0\right\|^2\right] L(θ)=Et,x0,c[wt∥Mθ(αtx0+σtϵ,t,c)−x0∥2]
其中, M θ M_\theta Mθ 表示由参数 θ \theta θ 参数化的 DiT 架构模型, t t t 是从范围 [ 0 , T ] [0, T] [0,T] 中均匀采样的时间步, ϵ \epsilon ϵ 是标准高斯噪声。参数 α t \alpha_t αt、 σ t \sigma_t σt 和 w t w_t wt 是扩散噪声参数。 x 0 x_0 x0 表示原始的潜在表示,而 c c c 是通过 MIF 集成到扩散模型中的条件信息。
我们在图 3 中展示了 LoRA 权重的推理过程。随机噪声在参考图像的引导下去噪为 LoRA 潜在表示。在扩散过程中,我们使用 DDIM (Song, Meng, and Ermon 2020) 采样新的 LoRA 权重。
LoRA 权重管道
如图 6 所示,我们开发了生成高质量 LoRA 权重数据集的管道。我们的方法首先从 FFHQ(Karras、Laine 和 Aila 2019)和 CelebA-HQ(Karras 等人 2018)数据集收集面部图像。为了确保 LoRA 权重的性能,我们利用 PhotoMaker(Li 等人 2024)以 1024×1024 的分辨率为每个个体生成 100 张不同的图像。
通过此管道,我们创建了一个多样化的图像数据集,适合训练和导出 100k 个 LoRA 检查点。
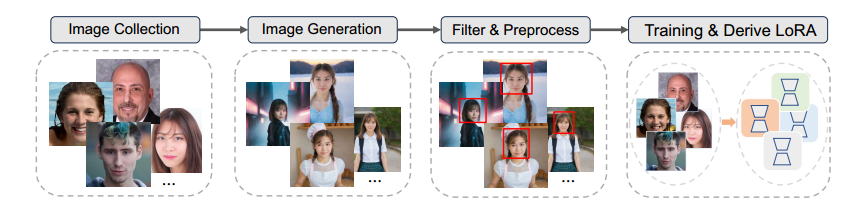
图 6:构建 LoRA 权重数据集的流程。
图像收集。我们首先从 FFHQ(Karras、Laine 和 Aila 2019)和 CelebA-HQ(Karras 等人 2018)数据集获取高质量的面部图像,这些图像是我们流程的基础。
图像生成。利用 PhotoMaker(Li 等人
2024),我们可以为每个个体生成 100 张不同的图像,其中包含 100 个独特的提示,这些提示可以捕捉各种视角、手势和美学。这些提示是专门针对男性和女性类别制作的,以创建一个全面而多样化的数据集。此步骤确保一组多样化的图像代表每个身份的各种表情、属性和场景。
图像过滤和预处理。我们使用 InsightFace(Deng 2022)来计算生成的图像与原始图像之间的面部相似性。选择相似度得分最高的前 85 张图像。这些选定的图像经过丰富,并通过各种数据增强操作进行进一步的预处理,包括裁剪、翻转和颜色变换。
使用 DreamBooth 进行训练。然后使用 85 张预处理后的图像按照 (Ruiz et al 2023) 中的方法训练 SDXL 模型,并按照 (Yeh et al 2023) 中描述的方法应用 LoRA。此过程对 SDXL 进行微调并得出用于高保真图像生成的 LoRA 权重。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











