










CTRL-ADAPTER:一种高效且通用的框架,用于将多种控制适配到任意扩散模型
paper是UNC发表在ICLR 2025的工作
paper title:CTRL-ADAPTER: AN EFFICIENT AND VERSATILE FRAMEWORK FOR ADAPTING DIVERSE CONTROLS TO ANY DIFFUSION MODEL
Code:链接
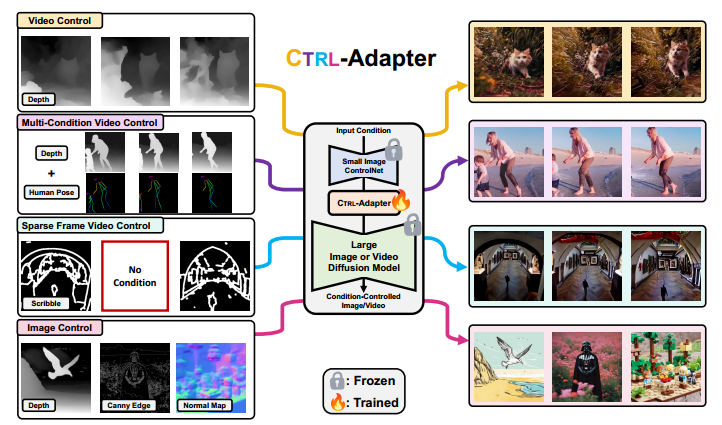
图 1:我们提出了 CTRL-Adapter,这是一种高效且通用的框架,可为任意扩散模型添加多种控制。CTRL-Adapter 支持多种实用应用。
ABSTRACT
ControlNets 被广泛用于向文本到图像的扩散模型添加空间控制,并支持不同的条件,例如深度图、涂鸦/素描和人体姿态。然而,在可控视频生成方面,ControlNets 由于特征空间的不匹配,无法直接集成到新的主干网络中,并且为新主干网络训练 ControlNets 对许多用户来说是一项巨大的负担。此外,独立地将 ControlNets 应用于不同帧无法有效保持目标的时间一致性。为了解决这些挑战,我们提出了 CTRL-Adapter,一种高效且通用的框架,可通过对预训练 ControlNets 的适配,将多种控制方式添加到任何图像/视频扩散模型中。CTRL-Adapter 提供强大且多样化的功能,包括图像和视频控制、稀疏帧视频控制、细粒度的 Patch 级多条件控制(通过 MoE 路由器)、零样本适配至未知条件,并支持多种下游任务,超越了传统的空间控制,例如视频编辑、视频风格迁移和文本引导的运动控制。CTRL-Adapter 兼容六种不同的 U-Net/DiT 扩散模型(SDXL、PixArt-α、I2VGen-XL、SVD、Latte、Hotshot-XL),在 COCO 数据集上的性能与预训练 ControlNets 相当,并在 DAVIS 2017 数据集上达到了最先进的水平,同时计算量大幅降低(< 10 GPU 小时)。
1 INTRODUCTION
近年来,扩散模型在生成高质量图像(Rombach et al., 2022; Podell et al., 2024; Saharia et al., 2022; Ramesh et al., 2022)和视频(Blattmann et al., 2023; Girdhar et al., 2023; Chen et al., 2024a; Lin et al., 2023; Long et al., 2024)方面取得了重大进展。然而,仅使用文本来描述每个图像/视频的细节通常较为困难,因此许多研究致力于通过额外的控制输入(如边界框(Li et al., 2023c; Yang et al., 2023)、参考图像(Ruiz et al., 2023; Gal et al., 2023; Li et al., 2023d)和分割图(Gafni et al., 2022; Avrahami et al., 2023; Zhang et al., 2023c)等)来实现更精细的控制。其中,Zhang et al.(2023c)发布了一系列基于 Stable Diffusion(Rombach et al., 2022; V1.5) 的 ControlNet 检查点,并得到了广泛应用,社区贡献了大量针对不同输入条件训练的 ControlNets。如今,ControlNet 已成为最受欢迎的可控图像生成方法之一。
然而,在可控视频生成任务中使用现有的预训练 ControlNets 仍然存在挑战。首先,预训练 ControlNet 无法直接集成到新的主干模型中,并且为新主干模型训练 ControlNets 对许多用户而言是一个巨大的计算成本。例如,为 SDv1.5 训练一个 ControlNet 需要 500-600 A100 GPU 小时(Zhang et al., 2023b)。其次,ControlNet 最初是为可控图像生成设计的,因此直接将预训练 ControlNets 独立应用于每一帧视频会忽略帧间的时间一致性。
为了解决这些问题,我们提出 CTRL-Adapter,一种新的、灵活的框架,能够高效复用预训练 ControlNets 以适配任意图像/视频扩散模型,并增强时间对齐能力。如图 3 左侧(第 2 节)所示,CTRL-Adapter 通过适配器层(Houstly et al., 2019; Yi-Lin Sung, 2022)映射预训练 ControlNet 的特征到目标图像/视频扩散模型,同时保持 ControlNet 和主干模型的解码层不变。如图 3 右侧所示,CTRL-Adapter 由四个模块组成:空间卷积、时间卷积、噪声适配、条件融合。其中,时间卷积/注意力模块可以增强时序一致性。为了确保 ControlNet 在具有不同噪声尺度和稀疏帧输入的主干模型上的适配,我们提出了跳过 ControlNet 输入的视觉潜变量的方法。此外,我们引入逆时间步采样,以便高效适配 ControlNets 至新主干模型,并保持连续时间步采样。为了在超越单一条件的情况下实现更精确的控制,我们设计了一种新颖且强大的Mixture-of-Experts (MoE) 路由器,该路由器允许在 Patch 级别进行细粒度特征融合。
如表 5 所示,CTRL-Adapter 具有许多实用功能,包括图像控制、视频控制(支持稀疏帧输入)、多条件控制,并能够适配不同的主干模型,而现有方法仅支持其中的部分功能(见第 5 节)。我们通过大量实验和分析,证明 CTRL-Adapter 在适配 ControlNets(预训练于 SDv1.5)到各种视频和图像扩散主干模型时表现优异,包括图像到视频生成(I2VGen-XL(Zhang et al., 2023d) 和 Stable Video Diffusion(SVD)(Blattmann et al., 2023))、文本到视频生成(Latte(Ma et al., 2024) 和 PixArt-α(Chen et al., 2024c))、文本到图像生成(SDXL(Podell et al., 2024) 和 PixArt-α(Chen et al., 2024c))。CTRL-Adapter 还能够无缝适配 DiT 模型(如 Latte 和 PixArt-α),这些模型的架构与传统 U-Net ControlNets 结构完全不同,这充分证明了 CTRL-Adapter 的灵活性。
在第 4.1 和第 4.2 节,我们首先展示 CTRL-Adapter 在 COCO 数据集上与预训练的 ControlNet 性能相当(Lin et al., 2014),并且在 DAVIS 2017 数据集上超越了现有方法,在可控视频生成任务中达到了最先进水平(SOTA)(Pont-Tuset et al., 2017),同时计算量大幅降低(< 10 GPU 小时,如图 2)。接下来,我们证明 CTRL-Adapter 使可控视频生成支持多个控制条件,而不仅限于单一控制。我们的细粒度 Patch 级 MoE 路由始终优于等权加权基线和全局 MoE 路由(见第 4.3 节)。此外,我们展示了跳过 ControlNet 视觉潜变量允许视频控制仅作用于少量帧(即,稀疏控制),消除了对所有帧提供密集控制的需求。
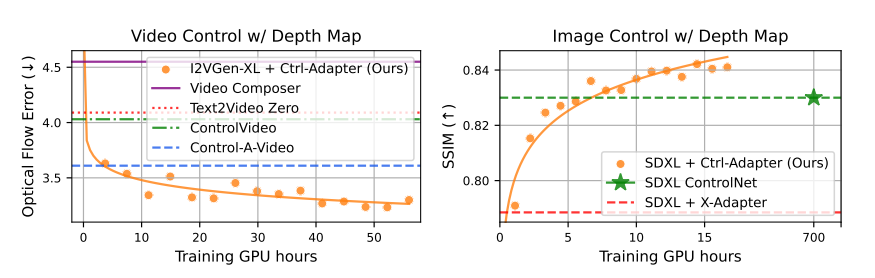
图 2:CTRL-Adapter 在视频(左)和图像(右)控制任务上的训练速度(使用深度图),在 A100 80GB GPU 上测量。对于视频和图像控制任务,CTRL-Adapter 仅训练 10 GPU 小时即可超越强基线模型,包括训练 700 GPU 小时的 SDXL。
(第 4.4 节)我们还强调了零样本适配——CTRL-Adapter 在一种控制条件上训练后,可以轻松适配到使用不同条件训练的 ControlNet(见第 4.5 节)。在第 4.6 和第 4.7 节,我们提供了 ControlNet 训练效率的对比,并与单一 CTRL-Adapter 和各个 ControlNets 进行对比。此外,我们展示 CTRL-Adapter 可以灵活应用于超越空间控制的多种下游任务,包括视频编辑、视频风格迁移、文本引导的运动控制(附录 H.3)。最后,我们提供了对 CTRL-Adapter 设计选择的全面消融实验(附录 E),关于视觉质量和空间控制权衡的定量分析(附录 F),以及定性示例(附录 G)。
- 我们提出了一种高效且通用的框架(CTRL-Adapter),能够将多种控制方式适配到任意图像/视频扩散模型,并且匹配从头训练 ControlNet 的性能,同时显著降低训练成本。
- 我们设计了一种细粒度 Patch 级 MoE 路由,能够高效组合 ControlNet 特征,而现有方法仅支持图像级特征融合。
- CTRL-Adapter 兼容 U-Net 和 DiT 结构的扩散模型(如 PixArt-α、Latte),并适用于多种连续时间步采样(通过逆噪声采样)、不同噪声尺度和稀疏输入帧(通过潜变量跳过)。
- 通过广泛的实验,我们证明 CTRL-Adapter 在图像和视频任务中均能匹配预训练 ControlNets 的性能,并且可以灵活应用于视频编辑、视频风格迁移、文本引导的运动控制等任务。
2 METHOD
2.1 PRELIMINARIES: LATENT DIFFUSION MODELS AND CONTROLNETS
潜变量扩散模型(Latent Diffusion Models)
许多最新的视频生成研究利用潜变量扩散模型(LDMs)(Rombach et al., 2022)来学习视频的紧凑表示。首先,给定一个
F
F
F 帧的 RGB 视频
x
∈
R
F
×
3
×
H
×
W
x \in \mathbb{R}^{F \times 3 \times H \times W}
x∈RF×3×H×W,一个视频编码器(源自预训练自动编码器)将其转换为
C
C
C 维的潜变量表示(即 latent):
z
=
E
(
x
)
∈
R
F
×
C
×
H
′
×
W
′
z = \mathcal{E}(x) \in \mathbb{R}^{F \times C \times H' \times W'}
z=E(x)∈RF×C×H′×W′,其中高度和宽度经过降采样(
H
′
<
H
H' < H
H′<H 且
W
′
<
W
W' < W
W′<W)。接下来,在前向过程中,一个噪声调度器(例如 DDPM(Ho et al., 2020))向潜变量
z
z
z 添加噪声。在反向传播过程中,一个扩散模型
F
θ
(
z
t
,
t
,
c
text/img
)
\mathcal{F}_\theta (z_t, t, c_{\text{text/img}})
Fθ(zt,t,ctext/img) 学习逐步去噪这些潜变量,给定扩散时间步
t
t
t,以及文本提示
c
text
c_{\text{text}}
ctext(如 T2V 任务)和/或初始图像帧
c
img
c_{\text{img}}
cimg(如 I2V 任务)(若提供)。
扩散模型的训练目标如下:
L L D M = E z , ϵ ∼ N ( 0 , I ) , t [ ∥ ϵ − ϵ θ ( z t , t , c text/img ) ∥ 2 2 ] \mathcal{L}_{LDM} = \mathbb{E}_{z, \epsilon \sim \mathcal{N}(0, I), t} \left[ \| \epsilon - \epsilon_\theta (z_t, t, c_{\text{text/img}}) \|_2^2 \right] LLDM=Ez,ϵ∼N(0,I),t[∥ϵ−ϵθ(zt,t,ctext/img)∥22]
其中, ϵ \epsilon ϵ 和 ϵ θ \epsilon_\theta ϵθ 分别表示添加到潜变量中的噪声和模型预测的噪声。我们在 CTRL-Adapter 训练中采用相同的目标函数。
ControlNets
ControlNet(Zhang et al., 2023c)旨在为图像扩散模型添加空间控制(例如深度图、素描、分割图等)。具体而言,给定一个预训练的主干图像扩散模型
F
θ
\mathcal{F}_\theta
Fθ,该模型由输入/中间/输出块组成,ControlNet 采用类似的架构
F
θ
′
\mathcal{F}_{\theta'}
Fθ′,其中输入/中间块的参数从
θ
\theta
θ 继承,而输出块由初始化为零的
1
×
1
1 \times 1
1×1 卷积层组成。ControlNet 以扩散时间步
t
t
t、文本提示
c
text
c_{\text{text}}
ctext、控制图像
c
f
c_f
cf(如深度图)、以及带噪潜变量
z
t
z_t
zt 作为输入,并将输出特征合并到主干模型
F
θ
\mathcal{F}_\theta
Fθ 以最终生成图像。
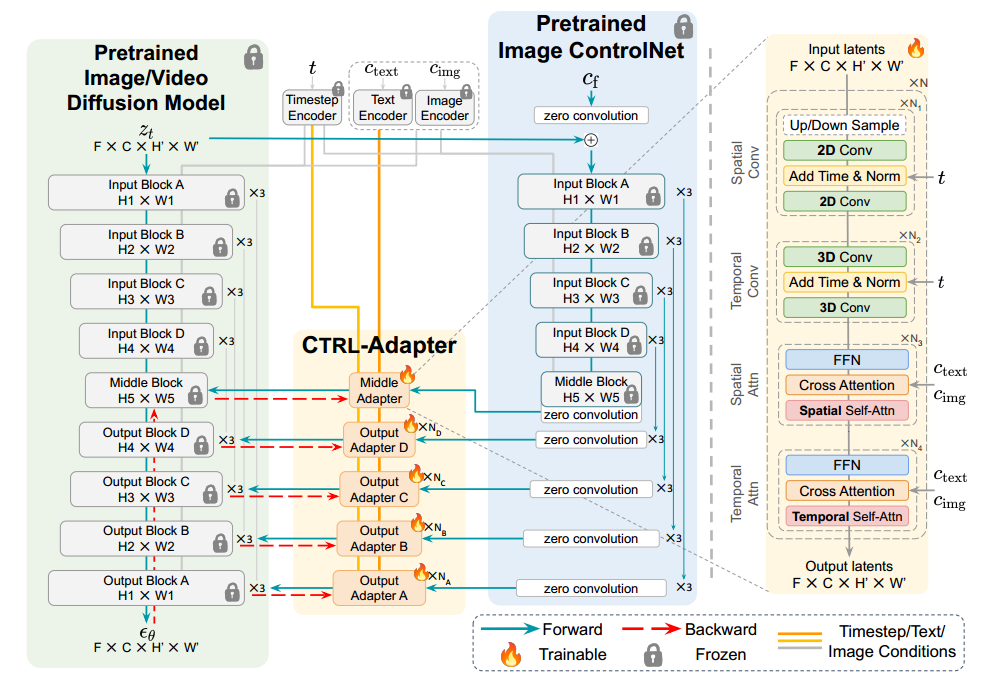
图 3:左图:CTRL-Adapter(橙色部分)用于复用预训练的图像 ControlNets(蓝色部分),并适配到新的图像/视频扩散模型(绿色部分)。 右图:CTRL-Adapter 的架构细节。在图像扩散主干网络中,跳过时间卷积和注意力层。
2.2 CTRL-ADAPTER
我们提出 CTRL-Adapter,一种新颖的框架,能够高效复用现有的图像 ControlNets(SDv1.5),用于新的扩散模型的空间控制。我们主要描述在视频生成环境中的方法细节,因为 CTRL-Adapter 可以通过将图像视为单帧视频,灵活地适配到图像扩散模型。
高效适配预训练 ControlNets。
如图 3(左)所示,我们训练一个适配模块(橙色部分)将预训练 ControlNet(蓝色部分)的中间/输出块映射到目标视频扩散模型(绿色部分)的对应中间/输出块。如果目标主干模型的输出块数量不同,CTRL-Adapter 会将 ControlNet 特征映射到处理最接近的潜变量高度和宽度的输出块。我们保持 ControlNet 和目标视频扩散模型中的所有参数冻结。因此,训练一个 CTRL-Adapter 的效率远高于训练一个全新的视频 ControlNet。
CTRL-Adapter 结构。
如图 3(右)所示,每个 CTRL-Adapter 模块由四个部分组成:空间卷积、时间卷积、空间注意力、时间注意力。我们默认将
N
1
,
.
.
.
,
N
4
N_1, ..., N_4
N1,...,N4 和
N
N
N 设为 1。时间卷积和注意力模块能够有效融合 ControlNet 特征,使其更好地适配视频主干模型,以保持时间一致性。此外,空间/时间卷积模块结合了当前的去噪时间步
t
t
t,方法是将时间步嵌入添加到适配器特征中,而空间/时间注意力模块则通过跨注意力机制结合图像/文本条件嵌入与适配器特征。这种设计使得 CTRL-Adapter 能够根据不同的去噪阶段和生成的目标动态调整特征。此外,在适配图像扩散模型时,我们跳过时间卷积/注意力模块。更多关于四个模块的架构细节,请参见 附录 B.1,更详细的设计选择消融实验请参见 附录 E。
适配基于 DiT 的图像/视频主干网络。我们的 CTRL-Adapter 还可以将基于 U-Net 的 ControlNets 适配到基于 DiT 的图像/视频生成主干网络。我们观察到的一个重要现象是,ControlNets 的 U-Net 结构和 DiT 块的空间特征编码在结构上存在差异(见图 22)。具体来说,U-Net 结构的特征表示遵循从粗到细的层次模式,例如:较早的层输出较小的空间特征图,并控制高层次语义信息(如物体存在与否),而较晚的层输出更大的特征图,并控制低层次细节(如纹理)。相比之下,所有 DiT 块处理的特征图大小相同。这表明,直接将 ControlNet 的多级输出块映射到 DiT 可能并非最优方案。因此,我们选择将 ControlNet 中最大的特征图(即 block A)映射到 DiT 块,并通过零卷积(zero-convolutions)进行通道维度匹配。为了提高 DiT 结构的计算效率(如 Latte Ma et al., 2024b),我们仅在部分 DiT 层(如 2, 4, 6, …, 28 层)插入 CTRL-Adapter(见图 16 (a))。更多关于 CTRL-Adapter 在 DiT 结构中的设计讨论,请参阅附录 B.2。
跳过 ControlNet 输入中的潜变量:稳健适配不同的噪声尺度和稀疏帧条件。尽管原始 ControlNets 将潜变量 z t z_t zt 作为输入的一部分,但我们发现在某些场景下跳过 z t z_t zt 更有利于 CTRL-Adapter 适配(见图 12)。
(1) 适配不同的噪声尺度:SDv1.5 采样的噪声 e e e 服从 N ( 0 , I ) \mathcal{N}(0, I) N(0,I),而一些最新的扩散模型(Hoogeboom et al., 2023; Esser et al., 2024; Blattmann et al., 2023)则采用更大尺度的噪声,例如 SVD(Blattmann et al., 2023)采用的噪声为 σ ∗ N ( 0 , I ) \sigma * \mathcal{N}(0, I) σ∗N(0,I),其中 σ ∼ LogNormal ( 0.7 , 1.6 ) \sigma \sim \text{LogNormal}(0.7, 1.6) σ∼LogNormal(0.7,1.6), σ ∈ [ 0 , + ∞ ] \sigma \in [0, +\infty] σ∈[0,+∞],且 E [ σ ] = 7.24 \mathbb{E}[\sigma] = 7.24 E[σ]=7.24。我们发现,将大尺度的 z t z_t zt 添加到新主干模型的图像条件 c f c_f cf 中,会削弱 c f c_f cf 的表达能力,并降低 ControlNet 输出的有效性。而跳过 z t z_t zt 使得 CTRL-Adapter 更容易适配新模型。
(2) 适配稀疏帧条件:当图像条件 c f c_f cf 仅适用于部分视频帧(即,大多数帧 f j f_j fj 没有 c f c_f cf)时,ControlNet 可能依赖 z t z_t zt 来提供缺失的信息,并在训练过程中忽略 c f c_f cf。跳过 z t z_t zt 使得 CTRL-Adapter 在训练过程中能够更高效地处理稀疏帧条件(见表 10)。当潜变量跳过(latent-skipping)时,ControlNet 的输入仅为 c f c_f cf,即 F θ ( c f ) \mathcal{F}_\theta(c_f) Fθ(cf),而不是 F θ ( c f + z t ) \mathcal{F}_\theta(c_f + z_t) Fθ(cf+zt)。
正则化
逆时间步采样:稳健适配离散与连续扩散时间步采样器。SDv1.5 采样的时间步 t t t 从 { 0 , 1 , . . . , 1000 } \{0, 1, ..., 1000\} {0,1,...,1000} 的离散分布中均匀采样,而一些最新的扩散模型(Esser et al., 2024; Ma et al., 2024a; Rombach et al., 2021)则采用从 LogNormal 分布采样的时间步,例如 SVD(Blattmann et al., 2023)采样的时间步来自一个 LogNormal 分布。由于离散时间步和连续时间步之间的差异,我们无法直接将相同的时间步分配给视频扩散模型和 ControlNet。因此,我们提出逆时间步采样(Inverse Timestep Sampling),该方法在离散和连续时间步分布之间建立映射(见 PyTorch 代码 算法 1,Ansel et al., 2024)。该算法的核心思想来自估计引理(Estimation lemma)(Ansel et al., 2024):
- 给定连续时间步分布的累积分布函数(CDF) F cont F_{\text{cont}} Fcont。
- 对于 ControlNet 训练的时间步分布
F
cNet
F_{\text{cNet}}
FcNet:
- 先从 [ 0 , 1 ] [0,1] [0,1] 之间采样一个随机值 u u u。
- 然后返回使得 F cont ( t cont ) ≥ u F_{\text{cont}}(t_{\text{cont}}) \geq u Fcont(tcont)≥u 的最小时间步 t cont ∈ [ 0 , ∞ ] t_{\text{cont}} \in [0, \infty] tcont∈[0,∞]。
- 选择满足 F cNet ( t cNet ) ≥ u F_{\text{cNet}}(t_{\text{cNet}}) \geq u FcNet(tcNet)≥u 的 t cNet ∈ { 0 , 1 , . . . , 1000 } t_{\text{cNet}} \in \{0, 1, ..., 1000\} tcNet∈{0,1,...,1000}。
此过程自然地创建了两个时间步分布之间的映射。更多细节请参见附录 B.2。
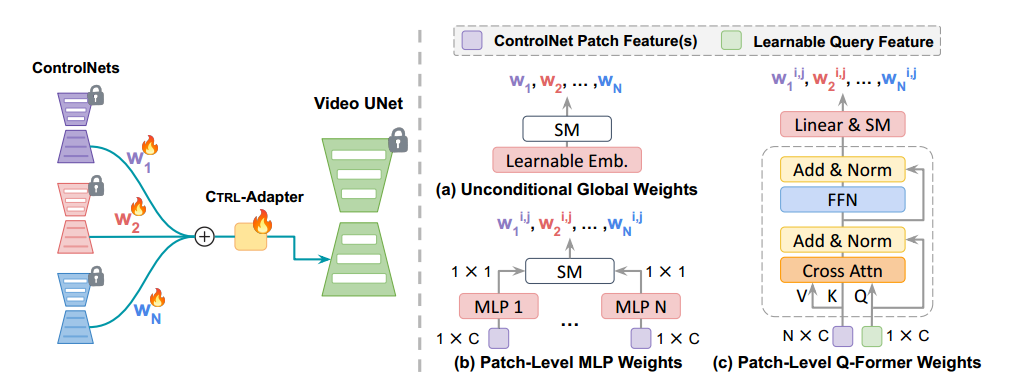
图 4:左图:通过组合多个 ControlNets 进行多条件视频生成的框架。 w 1 , w 2 , . . . , w N w_1, w_2, ..., w_N w1,w2,...,wN 表示分配给每个 ControlNet 的权重。 右图:三种 MoE 路由器变体。(a) 采用全局操作,而 (b) 和 © 在细粒度的 Patch 级别进行操作。 C C C 和 N N N 分别表示特征维度和 ControlNet 专家的数量。 w k i , j w_k^{i,j} wki,j 表示在第 k k k 个 ControlNet 的二维特征图上位置 ( i , j ) (i, j) (i,j) 处的路由器权重。SM 代表 Softmax。
2.3 MULTI-CONDITION GENERATION VIA CTRL-ADAPTER COMPOSITION
Multi-ControlNet(Zhang et al., 2023c)被提出用于超越单一条件的空间控制。然而,该方法在推理时直接以相等的权重组合不同的控制条件,而不经过训练。为了实现更有效的控制组合,我们针对以下方法进行了实验。对于每个变体,我们在每次训练步骤中随机选择 K ∈ { 1 , 2 , 3 , 4 } K \in \{1,2,3,4\} K∈{1,2,3,4} 个控制条件来训练 CTRL-Adapter 和路由器。不同变体的对比讨论见 第 4.3 节和附录 E.4。
-
(a) 无条件全局权重(Unconditional Global Weights):该变体使用无条件的全局可学习权重来替换这些固定权重,通过一个轻量级的 MoE(Shazeer et al., 2017)路由器实现。具体而言,该路由器是一个简单的线性层,输入维度为 1,输出维度等于控制条件的数量。每个输出维度代表分配给某个控制条件的权重,并满足所有权重之和等于 1 的约束。
-
(b) Patch 级 MLP 权重(Patch-Level MLP Weights):该变体将每个 ControlNet 的 patch 级特征独立转换为一个标量值,然后使用 softmax 计算各 patch 的 ControlNet 权重。具体而言,该路由器计算来自不同控制条件的特征图的加权平均值,这些特征图对应于相同的 patch,并通过一个 3 层 MLP 学习权重。输入维度等于特征图嵌入的维度,输出维度为 1,最终生成一个标量值来表示每个 patch 特征图的权重。
-
© Patch 级 Q-Former 权重(Patch-Level Q-Former Weights):该变体将所有 N N N 个 ControlNet 特征与一个 patch 相关联,并采用 Q-Former(Li et al., 2023b)的架构设计来输出专家权重。相比于变体 (b)(其每个 patch 的权重是独立计算的),变体 © 采用更整体的方法,使路由器能够同时观察整个特征图的所有 patches,然后决定每个 patch 分配的权重。
三种attention自适应权重策略,目的是更好的实现多条件控制
3 EXPERIMENTAL SETUP
ControlNets 和目标扩散模型。我们使用在 SD v1.5 上训练的 ControlNets。对于目标扩散模型,我们在两个 I2V(图像到视频)模型——I2VGen-XL(Zhang et al., 2023d)和 SVD(Blattmann et al., 2023),两个 T2V(文本到视频)模型——Latte(Ma et al., 2024b)和 Hotshot-XL(Mullan et al., 2023),以及两个 T2I(文本到图像)模型——SDXL(Podell et al., 2024)和 PixArt-α(Chen et al., 2024c)上进行实验。
训练和评估数据集。我们使用从 Panda-70M 训练集(Chen et al., 2024d)中采样的 20 万个视频,以及 LAION POP(Schuhmann & Bevan, 2023)数据集中的 30 万张图像,分别用于视频和图像 CTRL-Adapters 训练。在训练过程中,我们动态提取各种控制条件(例如深度图)以简化数据准备流程。根据先前的研究(Hu & Xu, 2023; Zhang et al., 2024),我们在 DAVIS 2017 数据集(Pont-Tuset et al., 2017)上评估视频 CTRL-Adapters,在 COCO val2017 数据集(Lin et al., 2014)上评估图像 CTRL-Adapters。详细的训练和推理设置见附录 C 和附录 D。
评估指标。我们从视觉质量和空间控制两个方面进行评估。视觉质量方面,遵循先前研究(Qin et al., 2023; Hu & Xu, 2023),我们使用 FID(Heusel et al., 2017) 来衡量生成的图像/视频质量。对于视频数据集,根据先前的研究(Hu & Xu, 2023; Li et al., 2024),我们报告光流误差的 L2 距离(Ranjan & Black, 2017),即控制条件与生成视频之间的光流误差。对于图像数据集,遵循 Uni-ControlNet(Zhao et al., 2024),我们报告结构相似性(SSIM,Wang et al., 2004)以及生成图像和真实图像之间的均方误差(MSE)。
4 RESULTS AND ANALYSIS
4.1 VIDEO GENERATION WITH SINGLE CONDITION
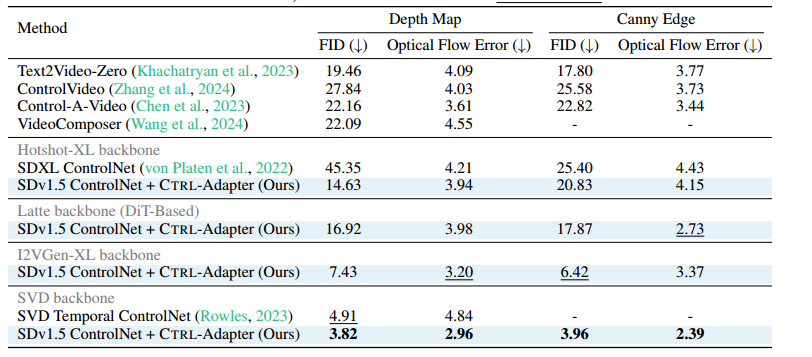
我们比较了基于 Hotshot-XL、I2VGen-XL、SVD 和 Latte 的 SDv1.5 ControlNet + CTRL-Adapter,并与以下视频控制方法进行对比:Text2Video-Zero(Khachatryan et al., 2023)、Control-A-Video(Chen et al., 2023)、ControlVideo(Zhang et al., 2024)和 VideoComposer(Wang et al., 2024)。由于 Hotshot-XL 的空间层初始化自 SDXL 并保持冻结,因此 SDXL ControlNets 可以直接兼容 Hotshot-XL,因此我们将 Hotshot-XL + SDXL ControlNet 作为基线。此外,我们还在 SVD 训练的 Temporal ControlNet(Rowles, 2023) 上进行了实验。
表 1 显示,在 深度图和 Canny 边缘检测输入条件 下,I2VGen-XL 和 SVD 上的 CTRL-Adapter 在视觉质量(FID)和空间控制(光流误差)指标方面均优于所有先前的强视频控制方法。需要注意的是,CTRL-Adapter 仅需 < 10 GPU 小时 即可超越基线方法(见 图 2)。在 附录 H.1,我们可视化了 CTRL-Adapter 与其他基线方法的比较。在 附录 F.1,我们研究了视觉质量与空间控制之间的权衡。
表 1:在 DAVIS 2017 数据集上对单一控制条件的视频生成进行评估。每列中最优的数值用 加粗 表示,次优的数值用 下划线 标记。
4.2 IMAGE GENERATION WITH SINGLE CONDITION
我们比较了 SDv1.5 ControlNet + CTRL-Adapter 与使用 SDv1.4、SDv1.5、SDXL 和 PixArt-α 作为主干网络的可控图像生成方法,包括 预训练的 SDv1.5/SDXL ControlNets(Zhang et al., 2023c; von Platen et al., 2022)、T2IAdapter(Mou et al., 2023)、GLIGEN(Li et al., 2023c)、Uni-ControlNet(Zhao et al., 2024)、X-Adapter(Ran et al., 2024)以及 PixArt-δ ControlNet(Chen et al., 2024b)。
如 表 2 所示,CTRL-Adapter 在几乎所有指标上均优于基于 SDv1.4/v1.5 的基线方法。与基于 SDXL 的基线方法相比,CTRL-Adapter 在大多数指标上优于 X-Adapter,并且在 FID/MSE(深度图输入) 上匹配 SDXL ControlNet,在 SSIM(深度图和 Canny 边缘输入) 上超越 SDXL ControlNet。需要注意的是,SDXL ControlNet 训练时间远长于 CTRL-Adapter(700 vs. 44 A100 GPU 小时),而 CTRL-Adapter 仅需不到 10 GPU 小时 即可在 SSIM(深度 ControlNet) 上超越 SDXL ControlNet(见 图 2)。
此外,当 CTRL-Adapter 应用于基于 DiT 的主干网络(即 PixArt-α) 时,在 FID 方面取得了显著提升(CTRL-Adapter:17.52 vs. PixArt-δ ControlNet:20.41(软边缘输入)),并在 SSIM 指标上取得了有竞争力的表现。在 图 5,我们可视化了 CTRL-Adapter 与其他图像控制基线方法的对比。更多可视化结果请参见 附录 H.2。
表 2:在 COCO val2017 数据集上对单一控制条件的图像生成进行评估。每列中最优的数值用 加粗 表示,次优的数值用 下划线 标记。
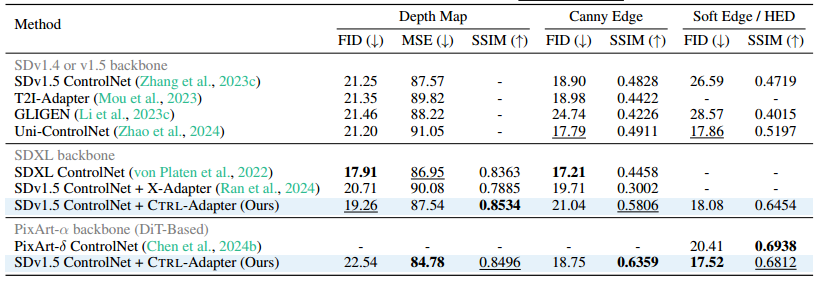

图5:具有单一条件的图像。
4.3 VIDEO GENERATION WITH MULTIPLE CONTROL CONDITIONS
如 第 2.3 节 所述,用户可以通过 CTRL-Adapter 简单地组合多个 ControlNets 的控制特征,从而实现多源控制。表 3 以两个方面展示了实验结果:
首先,Patch 级 MoE 路由器(即 图 4 中的 变体 b 和 c)始终优于等权重基线,同时也优于 无条件全局权重(即 图 4 中的 变体 a),这证明了 Patch 级细粒度控制组合的有效性。
其次,如 (b) 和 © 所示,使用更多控制条件通常会带来更好的空间控制和更高的视觉质量,相比于单一控制条件。图 28 和图 29 显示,多条件组合相比单一条件能提供更精确的控制。此外,表 9 进一步扩展了 (a),通过图像/文本/时间步嵌入进行条件控制。
表3:多条件视频生成的不同加权方法的比较(有关详细信息,请参见图4右侧)。对照源缩写为D(深度图),C(Canny Edge),N(表面正常),S(SoftEdge),SEG(语义分割图),L(Line Art)和P(人姿势)。

4.4 VIDEO GENERATION WITH SPARSE FRAMES AS CONTROL CONDITION
我们在 I2VGen-XL 作为主干网络的情况下,实验了 CTRL-Adapter 在稀疏帧控制条件下的表现。在每个训练步骤中,我们首先从 { 1 , . . . , N } \{1, ..., N\} {1,...,N} 中随机选择一个整数 k k k,其中 N N N 为输出帧的总数(例如,I2VGen-XL 的 N = 16 N = 16 N=16)。接着,我们从 N N N 帧中随机选择 k k k 个关键帧,并提取这些关键帧的深度图和用户绘制的草图作为控制条件。我们不给 ControlNet 传递潜变量 z z z,而仅提供 k k k 帧的控制信息。在 图 6 中,我们可以看到 I2VGen-XL + CTRL-Adapter 能够正确生成符合 4 个稀疏关键帧控制条件的视频,并在无控制条件的帧上进行合理插值。此外,在 附录 E.3,我们证明了跳过 ControlNet 输入中的潜变量对于提升稀疏控制能力至关重要。
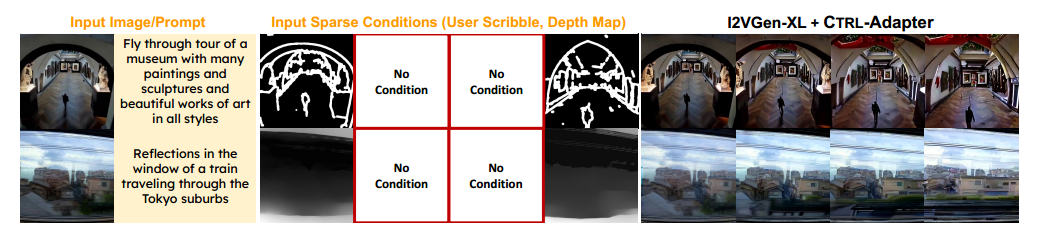
图6:从I2VGen-XL上使用CTRL-ADAPTER的稀疏帧条件的视频生成(总共生成16帧)。我们仅提供第1、6、11和16帧的控件。
4.5 ZERO-SHOT GENERALIZATION ON UNSEEN CONDITIONS
ControlNet 可以被理解为一种图像特征提取器,它将不同类型的控制信号映射到主干生成模型的统一表示空间。这引出了一个有趣的问题:
“CTRL-Adapter 是否可以学习从一个(较小)主干到另一个(较大)主干的通用特征映射?” 为了回答这个问题,我们实验了直接将 CTRL-Adapter 插入到训练过程中未见过的 ControlNets。在 图 7 中,我们观察到 在深度图上训练的 CTRL-Adapter 可以以零样本方式适配到法线图和软边缘 ControlNets。基于这一观察的不同训练策略的定量分析详见 第 4.7 节。

图 7:CTRL-Adapter 仅在深度图上训练,但能够零样本迁移到未见过的控制条件。
4.6 TRAINING EFFICIENCY
作为对 图 2 的补充,我们对比了 CTRL-Adapter 和 从零训练的 ControlNet 在不同控制条件下的训练效率,并使用相同的超参数设置以保证公平对比。图 9 显示,CTRL-Adapter 在不同的主干网络和任务中均实现了显著更快的训练速度和更高的最终性能。
此外,我们的方法在每个训练步骤的时钟时间比 ControlNet 更快:
- 深度图:CTRL-Adapter: 0.48s/step vs. ControlNet: 0.60s/step
- 分割:CTRL-Adapter: 0.57s/step vs. ControlNet: 0.68s/step
- OpenPose:CTRL-Adapter: 0.82s/step vs. ControlNet: 0.95s/step
最后,图 8 显示,CTRL-Adapter 仅需 3 分钟 即可训练出一个能够准确遵循边缘控制条件的模型,而 ControlNet 需要 20 分钟。

图 8:CTRL-Adapter 相比从零训练 ControlNet 实现了更快的收敛速度。
4.7 A UNIFIED MULTI-TASK ADAPTER V.S. INDIVIDUAL TASK-SPECIFIC ADAPTERS
在上述主要实验结果中,我们为每种控制条件分别训练了 CTRL-Adapter。一个有趣的问题是:我们能否训练一个通用的 CTRL-Adapter,使其适用于所有控制条件?
我们设计了一组实验,对比了以下两种方式:
- 训练一个单一的通用 CTRL-Adapter(适用于所有控制条件)。
- 为每种控制条件单独训练一个适配器。
具体而言,我们使用相同的训练设置,唯一的区别在于:
- 单独训练的 CTRL-Adapter:每个训练步骤仅从输入图像中提取一种控制条件(例如深度图)。
- 通用 CTRL-Adapter:每个训练步骤随机选择一种控制条件,包括 深度图、Canny 边缘、软边缘、法线图、OpenPose、线稿、分割图,每种条件被选中的概率相等。
在评估阶段,我们对 COCO val2017 数据集 中 1000 张随机选择的图像 进行评测,以比较生成图像的质量和控制质量。如 表 4 所示,通用 CTRL-Adapter 在 FID 和 SSIM 分数上达到了与单独训练的适配器相当的水平。这一结果与 第 4.5 节 观察到的 强零样本可迁移性 一致。因此,如果用户的计算资源有限,但仍需处理多个控制条件,我们建议训练一个 通用的 CTRL-Adapter。

表 4:基于 SDXL 主干训练的通用 CTRL-Adapter 在 FID/SSIM 方面与单独训练的 CTRL-Adapters 相当;评估基于 COCO val2017 数据集的 1000 个样本。
6 CONCLUSION
我们提出了 CTRL-Adapter,一个高效、强大且通用的框架,可为任何图像/视频扩散模型添加多种控制方式。训练 CTRL-Adapter 的效率远高于为新主干网络训练 ControlNet,并且在视觉质量和空间控制方面能够超越或匹配强基线方法。CTRL-Adapter 不仅提供了许多实用的能力,包括 图像/视频控制、稀疏帧控制、多条件控制,以及对未见条件的零样本适配,还能够 轻松灵活地集成到各种下游任务 中。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











