







 本文探讨了深度伪造(Deepfakes)技术在人工智能领域的现状、典型算法及存在的问题。研究发现,随着深度生成模型的进步,高视觉质量的Deepfake检测变得更具挑战性。文章介绍了基于帧推理的检测框架FInfer,该框架通过预测未来帧的面部表征,提高了检测性能。同时,指出了现有检测方法存在的问题,如对高视觉质量视频的敏感度降低和跨数据集检测的不稳定性。未来的研究热点包括开发大规模人脸取证数据集、提高检测效率以及提供可解释的理论分析。
本文探讨了深度伪造(Deepfakes)技术在人工智能领域的现状、典型算法及存在的问题。研究发现,随着深度生成模型的进步,高视觉质量的Deepfake检测变得更具挑战性。文章介绍了基于帧推理的检测框架FInfer,该框架通过预测未来帧的面部表征,提高了检测性能。同时,指出了现有检测方法存在的问题,如对高视觉质量视频的敏感度降低和跨数据集检测的不稳定性。未来的研究热点包括开发大规模人脸取证数据集、提高检测效率以及提供可解释的理论分析。
一、研究现状
由于Deepfake其潜在的安全威胁,它已经引起了学术界和工业界的研究兴趣。为了减轻这种风险,人们提出了许多对策。现有的Deepfake检测方法在处理视觉质量较低的Deepfake媒体时,可以通过明显的视觉伪影来区分。然而,随着深度生成模型的发展,Deepfake媒体的真实感得到了显著的提高,对现有的检测模型提出了严峻的挑战。在本文中,我们提出了一个基于框架推理的检测框架(FInfer)来解决高视觉质量的Deepfake检测问题。具体来说,我们首先学习当前和未来帧的面部的引用表示。然后,利用当前帧的面部表征,利用自回归模型预测未来帧的面部表征。最后,设计了一种表示预测损失来最大化真实视频和假视频的鉴别能力。我们通过信息论分析证明了我们的FInfer框架的有效性。熵和互信息分析表明,在真实视频中预测表征和参考表征之间的相关性高于高视觉质量的Deepfake视频。大量的实验表明,我们的方法在高视觉质量Deepfake视频的数据集内检测性能、检测效率和跨数据集检测性能方面都很有前景。
由于机器学习的最新发展,操纵和制作图像和视频的技术已经达到了一个新的复杂水平。这一趋势的前沿是所谓的深度造假(Deep Fakes),它是通过将使用深度神经网络合成的人脸插入到原始图像/视频中而产生的。深度造假与通过数字社交网络分享的其他形式的虚假信息一起,已经成为一个严重的问题,对社会产生了负面影响。因此,迫切需要有效的方法来揭露深度造假。迄今为止,深度造假的检测方法依赖于合成算法固有的伪影或不一致性,例如,缺乏逼真的眨眼和不匹配的颜色配置文件。基于神经网络的分类方法也被用于直接识别Deep Fakes中的真实图像。在这项工作中,我们提出了一种检测深度造假的新方法。我们的方法是基于深度神经网络人脸合成模型的内在局限性,而深度神经网络人脸合成模型是深度伪造生产管道的核心组件。具体来说,这些算法创建了不同的人的面部,但保留了原始人物的面部表情。然而,这两张脸的面部标志不匹配,这些标志是人类面部上与眼睛和嘴尖等重要结构相对应的位置,由于神经网络合成算法并不能保证原始人脸与合成人脸具有一致的面部标志。
二、典型算法:
接下来要介绍的三种算法是:基于用不一致的头部姿势暴露深度假,基于双分支循环网络的视频深度造假分离,基于帧推理的高视觉质量视频深度虚假检测。我们将之前所述的方法分别记作算法①②③,下面进行依次介绍。
深度造假是在原图的基础上将部分图像进行高质量的替换,同时在边缘位置进行平滑操作从而达到深度造假的效果。在利用头部姿势的不一致来进行深度造假的算法中,其算法根本是利用经过Deepfake之后人的头部姿势会因为改动而产生一定的变化,根据此来进行识别,在大量样本和场景的实验中证实有效[1]。
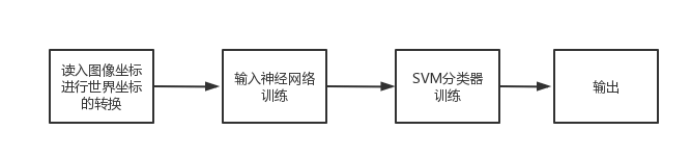
基于双分支循环网络的视频造假识别算法的原理是:双分支结构:一个分支传播原始信息,而另一个分支抑制面部内容,但使用拉普拉斯高斯(LoG)作为瓶颈层来放大多波段频率。为了更好地隔离被操纵的人脸,我们推导了一个新的代价函数,与常规分类不同,它压缩了自然人脸的可变性,并在特征空间中推开了不现实的人脸样本。[2]
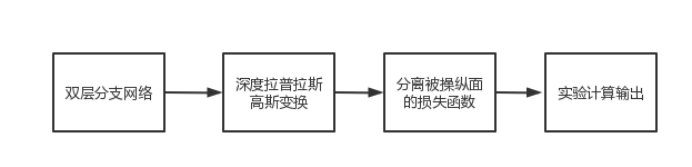
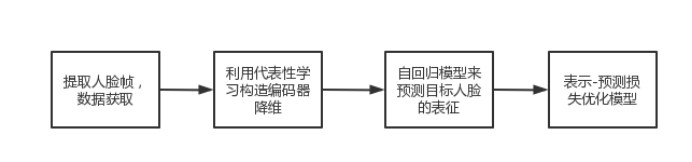
FInfer为基于帧推理的高视觉质量视频虚假探测的简称,由四个部分组成:人脸预处理、人脸代表性学习、人脸预测学习和基于相关性的学习。首先,我们从视频中提取帧并从帧中检测人脸。利用高斯-拉普拉斯金字塔块对人脸数据进行变换。其次,由于视频帧的数据维数巨大,我们利用代表性学习构造编码器,将源和参考目标面编码到低维空间。该编码器将人脸的空间特征编码到一个紧凑的潜在嵌入空间中,保证了预测的有效性。第三,我们使用自回归模型来预测目标人脸的表示。预测模型集成源人脸信息,预测目标人脸的表示形式。第四,我们利用基于相关性的学习模块,利用设计的表示-预测损失优化模型。表示预测损失允许整个模型被端到端训练。FInfer可以将损失反馈给代表学习模块和预测学习模块,这将帮助模型编码人脸表示,预测目标表示,并检测视频。[3]
三种方法的优缺点比较:方法①的思维创新新颖,标新立异,是很好的想法也有不错的效果,但是由于是刚刚提出应用范围不广,还需要时间和实践的检验。方法②是在深度学习中进行的方法的提出改进和优化,在代价函数,神经网络的设计上都有突出的贡献。对于方法③来说,基于帧推理的视频识别从另一种角度出发,算法思想和视频压缩还原的算法进行了有机结合,具有突出贡献和效果,值得推广应用。以上介绍的三种算法从某种程度上可以归类Deepfake的研究方法,从常识性的角度或者标新立异的方法,基于传统深度学习神经网络的方法和与实际图像处理相结合的方法。
三、存在问题
最近Deepfake的视频检测方法大致可以分为三类,即线索启发方法、数据驱动方法和多域融合方法。线索启发方法(Li, Chang, and Lyu 2018;Ciftci, Demir, and Yin 2020;yang, Li, and Lyu 2019;Koopman, Rodriguez, and Geradts 2018;Li和Lyu 2019)揭示了可观察到的特征,如眨眼不一致、生物信号和不现实的de36 AAAI人工智能会议(AAAI-22) 951尾巴来检测Deepfake视频。但是,在生成假视频的过程中,通过有目的的训练,可以绕过这些检测方法。数据驱动方法(Afchar et al 2018;Nguyen, Y amagishi,和Echizen 2019;Nguyen等2019;Tan and Le 2019;Rossler等人2019;赵等2021;Liu et al 2021;Xu等人2021)提取不可见的特征来有效地检测这些伪造品。这些方法没有将空间信息与其他域信息相结合,可能会忽略视频的关键特征。为此,多域融合方法(Güera和Delp 2018;Zhao, Wang, and Lu 2020;Qian等2020;Masi等2020;Hu et al 2021;Sun等人2021)跨多个域训练检测模型,如空间域、时间域和频域制造过程。虽然上述方法在检测早期数据集方面取得了良好的表现,但在最近开发的高视觉质量Deepfake视频中仍需要改进。之前的方法(Li, Chang, and Lyu 2018;Afchar等2018;Yang, Li, and Lyu 2019;Hu et al 2021)侧重于在低视觉质量视频中容易跟踪的特定特征,而这些特征在高视觉质量视频中可能会被严重削弱,导致检测性能降低。因此,我们需要一种更普遍的方式来放大假视频的篡改痕迹。
此外,上述方法的工件依赖性(Rossler et al 2019;Zhao et al 2021)在进行跨数据集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7297
7297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











