







文章目录
2022年初的笔记了,"虫之初"一节基本摘抄来自参考文献1,推荐看一下参考文献1,写的很全且很有趣。
什么是爬虫
什么是爬虫?
爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站去溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
最大的爬虫,就是搜索引擎。
你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
虫之初,性本善?
是的没错,爬虫也分善恶。
像谷歌这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供大家查阅,各个被扫的网站大都很开心。这种就被定义为「善意爬虫」。
但是,像抢票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次。铁总并不觉得很开心。这种就被定义为「恶意爬虫」。(注意,抢票的你觉得开心没用,被扫描的网站觉得不开心,它就是恶意的。)
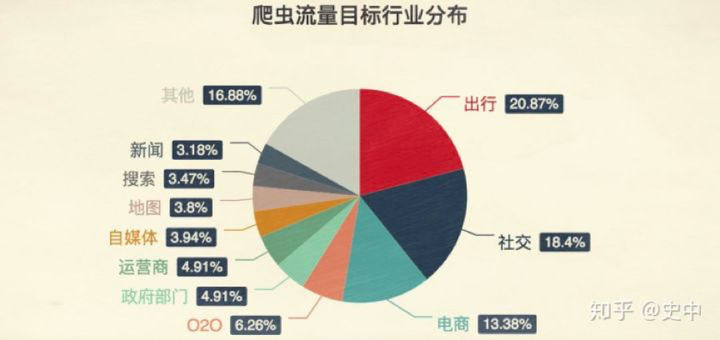
上图(来自参考文献1)显示的就是各行各业被爬虫骚扰的比例,注意,这张图显示的是全世界。
出行
国内爬出行行业的爬虫中,有90%的流量都是冲着12306去的,毕竟铁路就这一家。
你还记得当年 12306 上线王珞丹和白百何的「史上最坑图片验证码」么?
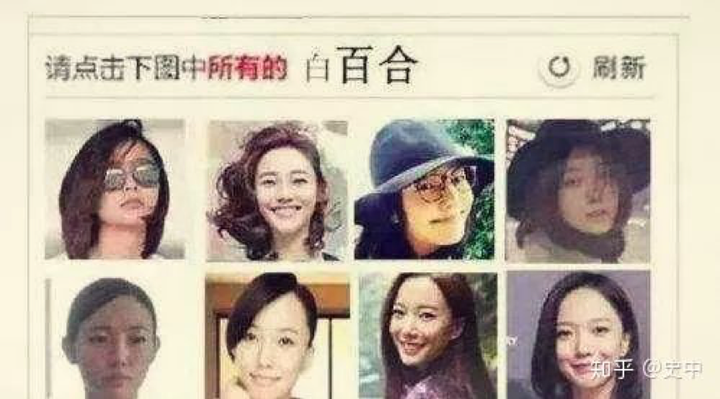
这些东西不是为了故意难为老老实实卖票的人的,而恰恰是为了阻止爬虫(也就是抢票软件)的点击。刚才说了,爬虫只会简单地机械点击,它不认识白百何,所以很大一部分爬虫就被挡在了门外。
当然,所谓道高一尺魔高一丈,并不是所有爬虫都会被白百何挡在门外。
有一种东西叫做打码平台,平台雇用了很多人手,手工来识别验证码。抢票软件如果遇到了之前没见过的图片验证码,系统就会自动把这些验证码传回来,由他们手工做好标记,然后再把结果传回去。总共的过程用不了几秒时间。
当然,这样的打码平台还有记忆功能。等回头时间长了,12306里的图片基本都能被标记完一遍了,防御手段被攻破,那12306在爬虫面前,自然是任君采撷。
所以你知道每年过年之前,12306 被点成什么样了吗?公开数据是这么说的:「最高峰时 1 天内页面浏览量达 813.4 亿次,1 小时最高点击量 59.3 亿次,平均每秒 164.8 万次。」这还是加上验证码防护之后的数据。可想而知被拦截在外面的爬虫还有多少。
同样的,航空的境遇也没好到哪儿去。
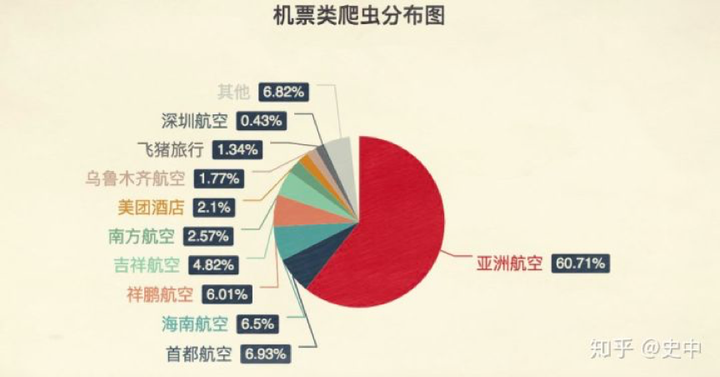
上图为航空类爬虫的分布比例。
以亚洲航空为例。这是一家马来西亚的廉价航空公司,航线基本都是从中国各地飞往东南亚的旅游胜地,飞机上连矿泉水都得自费买,堪称贫民度假首选。
亚航经常放出一些特别便宜的票。初衷是为了吸引游客,但是对黄牛党来说,这就是商机。
据说,他们是这么玩的:
技术宅黄牛党们利用爬虫,不断刷新亚航的票务接口,一旦出现便宜的票,不管三七二十一先拍下来再说。
亚航有规定,你拍下来半小时(具体时间记不清了)不付款票就自动回到票池,继续卖。但是黄牛党们在爬虫脚本里写好了精确的时间,到了半小时,一毫秒都不多,他又把票拍下来,如此循环。直到有人从黄牛党这里定了这个票,黄牛党就接着利用程序,在亚航系统里放弃这张票,然后 0.00001 秒之后,就帮你用你的名字预定了这张票。
社交
社交的爬虫重灾区,就是微博
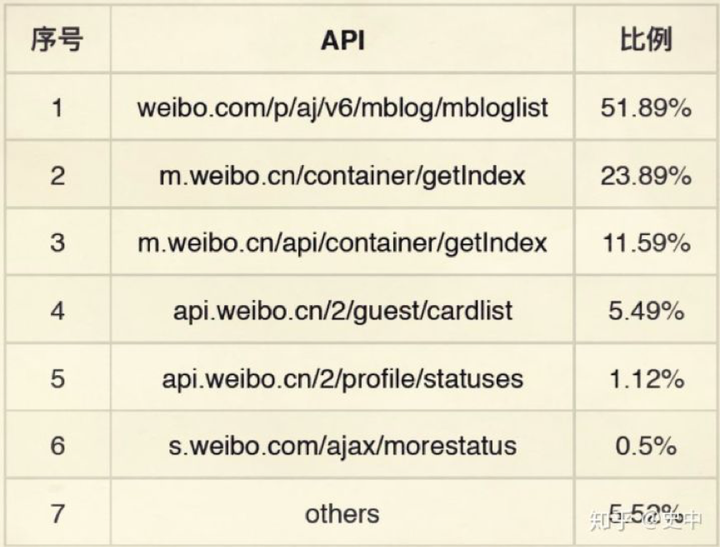
以上是爬虫经常光顾的微博地址。
这里的代码其实指向了微博的一个接口。它可以用来获取某个人的微博列表、微博的状态、索引等等等等。
获得这些,能搞出什么骚操作呢?
你想想看,如果我能随心所欲地指挥一帮机器人,打开某人的微博,然后刷到某一条,然后疯狂关注、点赞或者留言,这不就是标准的僵尸粉上班儿的流程么。。。
僵尸粉只是爬虫的常规操作,还有更加花哨的场景,甚至能躺着挣钱:
-
我是一个路人甲,我的微博没人关注,我用大量的爬虫,给自己做了十万人的僵尸粉,一群僵尸在我的微博下面点赞评论,不亦乐乎。
-
我去找一个保险公司,跟他说:你看我有这么多粉丝,你在我这投广告吧。我帮你发一条你们APP的注册链接,每有一个人通过我的链接注册了你们app,你就给我一毛钱。广告主说,不错,就这么办。
-
我发出注册链接,然后没人点。。。
-
不慌,我让十万爬虫继续前赴后继地点击注册链接,然后自动去完成注册动作。
-
我躺在床上,数着赚来的一万块钱。
电商
电商在爬虫的骚扰排名中,排名第三。
有几种东西叫作「比价平台」「聚合电商」和「返利平台」。他们大体都是一个原理:
你搜索一样商品,这类聚合平台就会自动把各个电商的商品都放在你面前供你选择。如淘宝、京东。
这就是爬虫的功劳。它们去各个电商的网站上把商品的图片和价格都扒下来,然后在自己这里展示。
比如说我找了一个比价平台,叫做慢慢买,然后搜索了iPhone12的比价:

可能身为消费者的我们会感觉不错,不过对电商平台来讲,被放在一起比价,京东和天猫肯定是拒绝的。
但是,机器爬虫模拟的是人的点击,电商很难阻止这类事情发生。他们甚至都不能向 12306 学习。你想想看,如果你每点开一个商品详情,淘宝都让你先分辨一次白百何和王珞丹,我不信你还有心情继续买下去。
当然,电商对抗爬虫有另外的方法,那就是「web 应用防火墙」,简称 WAF。
当然,这些聚合平台花了大力气和大资金来维持爬虫,不是做好事帮淘宝京东卖货的,他们也是有盈利手段的:
- 假设淘宝上有好几家店铺都卖iPhone,但是用户在我这里搜索的时候,我是有权利决定谁的店铺排在前面,谁的排在后面,就看谁给钱多呗。这一套,百度都玩烂了。另外,店铺跟淘宝可不是一致行动人,淘宝不希望自己的内容被聚合平台抓取,但是每个店铺可是很乐意多一个渠道帮他们卖货的;
- 页面独立广告;
搜索引擎
你可能了解,搜索引擎决定哪个网页排名靠前,(除了看给搜索引擎交了多少钱之外)主要一个指标就是看哪个搜索结果被人点击的次数更多。
既然这样,那么我就派出爬虫,搜索某个特定的「关键词」,然后在结果里拼命地点击某个链接,那么这个网站在搜索引擎的权重里自然就会上升。这个过程就叫作 SEO(搜索引擎优化)。
作为任何一个搜索引擎,都肯定不允许外人对于自己的搜索结果动手动脚,否则就会丧失公立性。它们会通过不定期调整算法来对抗 SEO。
尤其是很多赌博、黄色网站,搜索引擎如果敢收广告费让他们排到前面,那就离倒闭不远了。所以黄赌毒网站只能利用黑色 SEO,强行把自己刷到前面。直到被搜索引擎发现,赶紧对它们「降权」处理。
政府部门

第二名,北京市预约挂号统一平台。这就是黄牛号贩子的问题。
其他的,例如法院公告、信用中国、信用安徽,为什么爬虫要爬这些信息呢?
因为有些信息,是只有政府部门才掌握的。
比如,谁被告过,哪家公司曾经被行政处罚,哪个人曾经进入了失信名单。这些信息综合起来,可以用来做一个公司或者个人的信誉记录。
总结
有人说技术有罪,有人说技术无罪。但是在《网络安全法》中,基本上没有「爬取网络公开信息被认定为违法」的条款。算是法律的灰色区域吧。
之前看过一些技术老哥在网上发帖,只要有过来问他们会不会爬虫的,不多说,问就是不会。
面向监狱编程
爬虫界一直有这么一句笑话,叫做“爬虫玩得好,牢饭吃得早”,或者有的爬虫教程干脆起名叫“快速入狱指南”。
因为爬虫进监狱的案件数不胜数,前段时间听过一个18年的例子,一个爬虫项目的CTO和程序员都被抓了,为什么呢?因为他们公司有个业务,需要经常性的访问政府居住证网站,来查询房产地址、编码等情况,手动查询太慢了,于是公司的产品们讨论决定使用爬虫软件来做自动查询,18年3月,程序被部署上线了,然后4月份就出事了。
2018年4月27日10:34-12:00左右,居住证网站的承建厂商发现自己系统宕机了,怀疑是遭到了人为攻击,但是由于日志缺失,无法定位到IP来源,所以只能作罢。结果5月2日的时候,系统再次遭到攻击,这次响应比较迅速,运维成功截获了IP地址,然后报案了。然后5.17日的时候,网警把这个公司的服务器IP给锁了,这才顺藤摸瓜把这个公司扯了出来。
后来程序员说,是因为居住证网站后来加了验证码,但是公司的爬虫程序没有做更新,导致爬虫失控,频繁请求高达每秒183次,直接把对面网站攻击瘫痪了,导致所有居住证办理等对外服务都无法正常工作,影响了近100多个派出所和受理点的系统。
最后,2018年8月,CTO和程序员被捕,法院认为,二人违反国家规定,对计算机信息系统进行干扰,造成为5万以上用户提供服务的计算机信息系统不能正常运行累计1小时以上,属于后果特别严重,应以破坏计算机信息系统罪追究其刑事责任。
最终,负责并授权程序员开发涉案爬虫的CTO是主犯,被判有期徒刑三年,而开发爬虫的程序员系从犯,判处有期徒刑一年六个月。详细可以看一下参考文献6。

关于这件事,众说纷纭,很多人都说是政府网站开发技术太差,就是垃圾网站碰上了沙雕开发。对面网站没有基本的反爬虫防火墙,而这边的技术也是憨憨的暴力强爬。

爬虫的君子协议
爬虫第一步,查看robots.txt
什么是君子协议
搜索引擎的爬虫是善意的,它们检索你的网页信息是为了服务其他用户,为此它们还定义了robots.txt文件,作为君子协议。
robots.txt其实是网站和搜索引擎之间的一种博弈产物,也叫作robots协议,是一种放在网站根目录下的文本文件。它被用来告诉搜索引擎的漫游器(即网络蜘蛛),此网站下的哪些内容是不能被搜索引擎的漫游器获取的,哪些是可以获取的。
君子协议是怎么产生的?
robots协议并不是某一个公司制定的,最早在20世纪90年代就已经出现了,那时候还没有Google。真实Robots协议的起源,是在互联网从业人员的公开邮件组里面讨论并且诞生的。即便是今天,互联网领域的相关问题也仍然是在一些专门的邮件组中讨论,并产生(当然,主要是在美国)。
1994年6月30日,在经过搜索引擎人员以及被搜索引擎抓取的网站站长共同讨论后,正式发布了一份行业规范,即robots.txt协议。在此之前,相关人员一直在起草这份文档,并在世界互联网技术邮件组发布后,这一协议被几乎所有的搜索引擎采用,包括最早的altavista,infoseek,后来的google,bing,以及中国的百度,搜搜,搜狗等公司也相继采用并严格遵循。
robot,又称为spider,是搜索引擎自动获取网页信息的电脑程序的通称。robots的核心思想是要求爬虫程序不要去检索那些站长们不希望被直接搜索到的内容。
自有搜索引擎之日起,Robots协议已是一种目前为止最有效的方式,用自律维持着网站与搜索引擎之间的平衡,让两者之间的利益不致过度倾斜。
君子协议是什么内容?
robots.txt的内容格式:
- User-agent:定义爬虫的名称,比如说推特的叫做Twitterbot,百度的叫做Baiduspider,谷歌的叫做Googlebot。User-agent是*则表示针对的是所有爬虫。
- Disallow:不允许爬虫访问的地址,地址的描述符合正则表达式的规则;
- Allow:允许爬虫访问的地址
拿一个示例来看,以下节选自百度的robots协议:
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
Disallow: /baidu表示不允许百度的爬虫访问baidu目录下的所有目录和文件,这是个正则匹配的过程,可以简单的理解成:含有/baidu的URL均不能访问。
如何查看一个网站的robots协议
在浏览器的网址搜索栏里,输入网站的根域名,然后再输入/robots.txt,比如百度的robots.txt网址为:https://www.baidu.com/robots.txt,必应
其他以此类推。
淘宝网这一类购物网站基本都禁了搜索引擎:
比如说淘宝:
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
直接禁止了百度的爬虫对其的爬取,但是没有禁止其他爬虫。
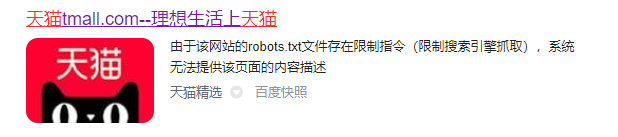
天猫就比较狠了,它是都禁了:
User-agent: *
Disallow: /
所以有时候我们会在搜索结果中看到这么个东西:
国外好多网站会这么写:
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
就是除了谷歌,其他都别想爬我
违反君子协议的案例
这种案例有很多,我个人比较感兴趣的是国内的360搜索案。
2012年8月,360综合搜索被指违反robots协议。其不仅未经授权大量抓取百度、google内容,还记录国内知名网站的后台订单、优惠码等,甚至一些用户的电子邮箱、帐号、密码也被360通过浏览器悄然记录在案。更严重的是,360连企业内网信息都抓,导致了大量企业内网信息被泄露。2012年年底,百度工程师通过一个名为“鬼节捉鬼”的测试,证明了360浏览器存在私自上传“孤岛页面”等隐私内容到360搜索的行为。
后来,百度起诉奇虎360违反Robots协议,抓取并复制百度旗下百度知道、百度百科、百度贴吧等网站的内容,涉嫌侵权,已经构成了不正当竞争,并向奇虎索赔1亿元。此案于2013年10月16日上午在北京市第一中级人民法院开庭审理。更加有趣的是,就在开庭审理的当日,360起诉百度“强制跳转”,且已被北京市高级人民法院正式受理。这一案件中,360索赔金额高达4亿元,360诉称,百度恶意阻断360搜索引擎用户的访问,拦截360用户,强迫其到百度首页进行搜索,且该等技术手段仅歧视性地对待360搜索引擎用户,这些行为不仅严重影响用户体验,且已经构成了不正当竞争,给360造成重大损失。而百度方面回应则称,这是百度针对部分网站匿名访问和违规抓取百度内容、导致网民搜索体验不完整的行为而上线的一项保护措施。
这两个案件扯得有点远,大约2年后才宣判,2014年8月7日,北京一中院做出一审判决,360赔偿百度70万元,但是驳回了百度公司的其他诉讼请求。另一个案子我在网上没找到结果。
比较有趣的是,360方面认为,360搜索这些页面内容并不涉嫌侵犯百度的权益,实际上还为百度带来了大量的用户和流量,百度应该感谢360。
robots协议完全就是一个自律条约,目前国内的现状是,基本只有大的搜索引擎会遵守,小门小户没人会在意这个。














 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









