







简介
之前提过,Hash索引在进行数据检索的时候,效率非常高,通常只需要O(1)的复杂度,就可以找到数据。但是它的应用场景很窄,缺点很明显,
- 只能满足
=、<>和in查询,无法使用范围查询, - Hash索引是无法排序的,它的数据可以理解是随机存储的,因此,在使用Hash索引时,遇到order by还需要对数据重新排序。
- 对于联合索引,Hash值是将所有索引键合并后一起计算出来的,这意味着无法利用部分索引键来进行查询。
但是Hash索引的方式对查询真的是很快,这么好的思路白白浪费了未免有些暴殄天物,所以MySQL提供了一种自适应Hash索引(Adaptive Hash Index),以Hash索引的思想,来给B+树索引提速。。
什么情况下使用自适应Hash索引
如果某个数据经常被访问,当满足一定条件的时候,就会将这个数据页的地址存放到hash表中。这样下次查询的时候,就可以直接找到这个页面。
因此,自适应Hash索引只保存热数据,即经常被使用到的数据,并非全表数据,所以数据量不会太多,一般会直接放到缓冲池里。
InnoDB中的自适应Hash相当于"索引的索引",它存储的其实是B+树索引中的页面的地址。
如图:

可以看到,采用自适应Hash索引的目的是更加快速的定位到叶子节点。以上图为例,通过左边找到数据页的速度,明显比通过右边找到数据页的速度要快得多。
自适应Hash索引的原理也很简单,就是简单的hash算法。即通过Hash函数将索引值映射到一个Hash表中,如图:
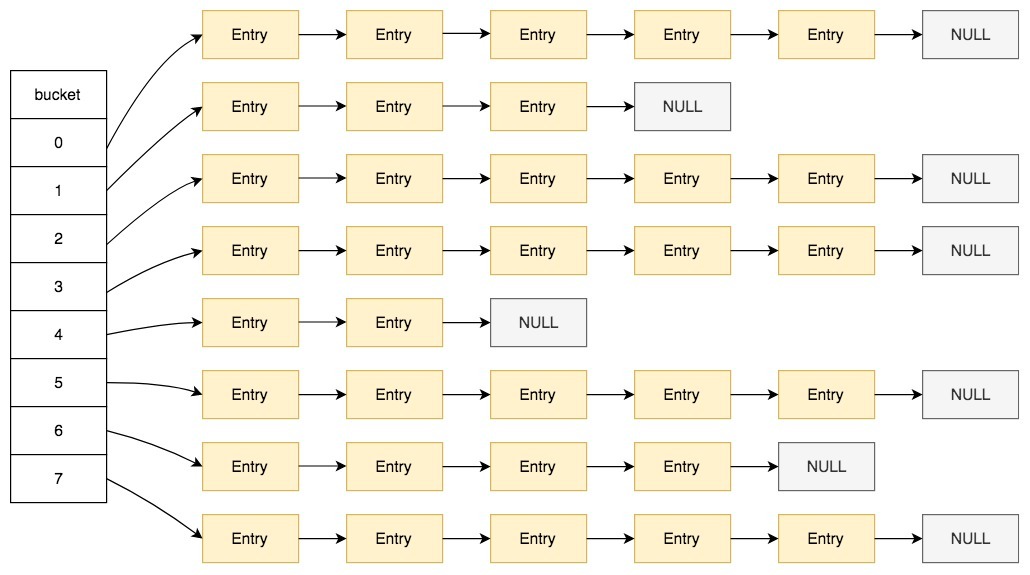
典型的数组加链表的形式,不同的桶里分别放着一个链表,定位到桶之后,再遍历链表就可以。
我们可以通过以下命令来查看MySQL是否开启了自适应Hash:
mysql> show variables like '%adaptive_hash_index';
需要注意,InnoDB本身不支持Hash索引,但是提供自适应Hash索引,不需要用户操作,存储引擎会自动完成。
自适应Hash是InnoDB的三大关键特性,其他两大特性是插入缓冲和二次写。简单了解下就行。















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









