










Spark中的Pregel—Bagel
*作者:王连平
如有转载,请注明文章出处:http://blog.csdn.net/wlp001007/article/details/50925325*
最近在学习Spark源码,看到Bagel 的部分,联想到自己之前学习的两个Pregel开源平台,在这里想对比和总结一下,但本文的最重要的部分还是堆Bagel的一个源码解析和走读。
首先,简单介绍一下Pregel的背景,Pregel是google公司提出来的一个图计算模型,该模型是基于BSP计算框架设计的,主要是针对图(graph)数据进行计算,具体的关于Pregel的其他细节,自己去问度娘。
其次,聊一下针对pregel的几个开源实现。其实,自从google提出这个图计算模型以后,引起了很多研究者的兴趣,比较典型的开源框架就是Hama和Giraph。先来说说Hama吧,Hama的背景在这也不再介绍,要说的是,Hama实现了BSP模型和Pregel两个计算模型,因为Pregel是基于BSP之上的,值得提出的是,整个Hama的整个框架都是重新建立的,这里想讲的就是Hama从底层master、worker的管理开始做起,再到任务的划分(包括数据分区)、任务分发以及任务的管理,当然还有上层的worker之间的信息传递和同步问题。简单的说,就是Hama几乎所有的东西都是自己创建的。那么下面,要讲的就是Giraph,Giraph这个开源平台其实很聪明,在Hadoop的mapreduce框架很火的那段日子里,有一帮人思考了这样一个问题,能不能借助Hadoop的MapReduce来实现Pregel计算框架呢?于是Giraph诞生了,它很巧妙的借用了Hadoop平台的优势,但是它相比Hama来讲,不足的地方就是Giraph没有实现BSP的计算模型,只是专注于图的处理,即Pregel。Giraph实际上是一个复杂的特殊的Hadoop Job,特殊性表现在,这个Job没Reduce过程,只有Map过程,复杂性表现在,只是通过一个Map过程就实现了复杂的Pregel模型,要知道,在这个Map中,要做的事情很多,确定Master/worker、通过ZooKeeper实现同步、以及节点之间的通信等等。换个角度来讲,Giraph实际上是借用了Hadoop的一些功能,HDFS就不提了,先天性的优势,最主要的就是借助了Hadoop的作业划分和任务提交的工作。
说了这么多了,终于该我们今天的主角上场了,Spark中的Pregel-----Bagel。Spark是现在很火的一个据说“无所不能”的基于内存的计算框架,这么火的东西当然要来研究一下了。在切入正题之前我们还得来做一个事情,就是再传统的Pregel框架中,要实现一个SSSP,我们要做的有以下几件事:
1. 实现Vertex类,最主要的是实现compute方法;
2. 如果有必要定制自己的Message类,用来传递消息;
3. 同样,如果有必要实现Combiner和Aggregator来优化自己的应用;
4. 根据自己的输入的数据格式定制解析类。
接下来,我们要从这几方面来研究一下Bagel的源码,Bagel是一个轻量级的Pregel实现,代码量也非常少。我觉得我们可以从一个例子入手逐渐深入,那就从官方的WikipediaPageRank这个例子入手。
这个例子的代码结构如下:
主类是 WikipediaPageRank,但是还有很多附属的类和函数,这些内容都放在PageRankUtils.scala这个源文件中。
首先贴出来的是它的源码:
object WikipediaPageRank {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println(
"Usage: WikipediaPageRank <inputFile> <threshold> <numPartitions> <usePartitioner>")
System.exit(-1)
}
val sparkConf = new SparkConf()
sparkConf.setAppName("WikipediaPageRank")
sparkConf.registerKryoClasses(Array(classOf[PRVertex], classOf[PRMessage]))
val inputFile = args(0)
val threshold = args(1).toDouble
val numPartitions = args(2).toInt
val usePartitioner = args(3).toBoolean
sparkConf.setAppName("WikipediaPageRank")
val sc = new SparkContext(sparkConf)
// Parse the Wikipedia page data into a graph
val input = sc.textFile(inputFile)
println("Counting vertices...")
val numVertices = input.count()
println("Done counting vertices.")
println("Parsing input file...")
var vertices = input.map(line => {
val fields = line.split("\t")
val (title, body) = (fields(1), fields(3).replace("\\n", "\n"))
val links =
if (body == "\\N") {
NodeSeq.Empty
} else {
try {
XML.loadString(body) \\ "link" \ "target"
} catch {
case e: org.xml.sax.SAXParseException =>
System.err.println("Article \"" + title + "\" has malformed XML in body:\n" + body)
NodeSeq.Empty
}
}
val outEdges = links.map(link => new String(link.text)).toArray
val id = new String(title)
(id, new PRVertex(1.0 / numVertices, outEdges))
})
if (usePartitioner) {
vertices = vertices.partitionBy(new HashPartitioner(sc.defaultParallelism)).cache()
} else {
vertices = vertices.cache()
}
println("Done parsing input file.")
// Do the computation
val epsilon = 0.01 / numVertices
val messages = sc.parallelize(Array[(String, PRMessage)]())
val utils = new PageRankUtils
val result =
Bagel.run(
sc, vertices, messages, combiner = new PRCombiner(),
numPartitions = numPartitions)(
utils.computeWithCombiner(numVertices, epsilon))
// Print the result
System.err.println("Articles with PageRank >= " + threshold + ":")
val top =
result
.filter { case (id, vertex) => vertex.value >= threshold }
.map { case (id, vertex) => "%s\t%s\n".format(id, vertex.value) }
.collect().mkString
println(top)
sc.stop()
}
} 代码的前半部分,很容易看懂,除了设置一些环境变量外,还干了一个很重要的事就是解析源文件中的数据,创建名为 vertices的RDD,那么我们就先从这个地方说起,来看看这个RDD到底是什么。从代码可以看到这个RDD的类型是[(id, new PRVertex(1.0 / numVertices, outEdges))],也就是说,他是一个key/value集合,由源码可知,他的key是顶点的ID,value是一个PRVertex类型的元素,PRVertex类型又是个什么鬼?联想Hama和Giraph中的实现方式,难道它就是传说中的Vertex类?从它的构造函数上看,它肯定存了定点的值和边的信息,下面来看一下PRVertex的源码:
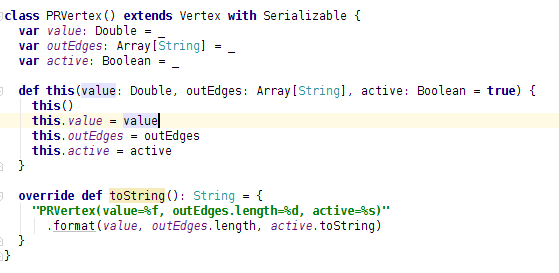
该源码中大家可以看到,存储的是定点的值、边ID和状态。大家到这里会想到,再Hama中Edge也是一个类并且边上除了targetID还有边上的值,在这里说一下,Spark中没有那么规范(死板),这里的边的类型你可以自己随便定义,这个类中是将它定义为String类型。同时大家可能也会惊奇,这个PRVertex类中连自己的ID都没有记录,是的,确实是,实际上你也可以记录下来,我们先往接着前面的往下看,为什么vertices是上面这个类型呢?后边会讲到。再往下看你会看到很重要的一行代码:

这行代码就是整个程序开始的核心,大家看到了Bagel这个类,那么主角将要来临,这个类是整个Spark版Pregel的逻辑核心。先来看看Bagel这个类都包含哪些函数吧,如下图所示:
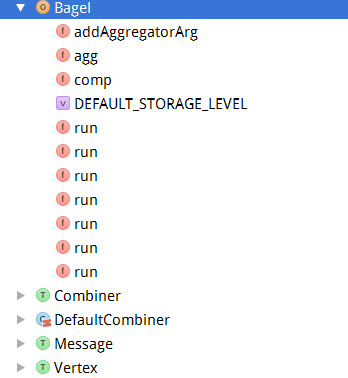
从上图可以看到这个Bagel对象,包含了很多函数,最醒目的就是run方法,还有三个接口和一个类,如果有必要这些都是用户来实现的,具体的细节大家看源码就行了,在这里会讲涉及到的几个方法或者类讲一下。下面要讲一下整个逻辑过程,也就是run这个方法,该类中这么多run方法,肯定是重载,也就是给我们用户留下了很多选择。
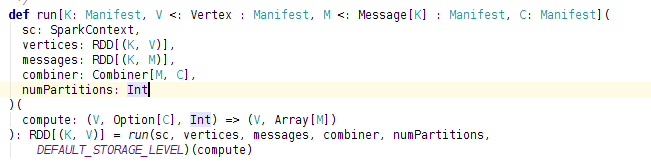
如上图所示,这是该例子中直接调用的run方法,可以发现,具体参数已经很清晰,其中K是ID的类型,V是Vertex类型,M是消息类型。该函数直接调用了下一个run函数,那么这个函数的作用是增加了一个默认的storage_level,其实这几个run函数之间是逐级调用,逐渐增加参数,如果用户提供了,就用用户的,如果用户没有提供,就增加默认的,这些参数包括storage_level、combiner、aggregator以及partitioner等。最后最后一个被调用的run方法就是核心的run函数了。下面贴出来该函数的代码:
def run[K: Manifest, V <: Vertex : Manifest, M <: Message[K] : Manifest,
C: Manifest, A: Manifest](
sc: SparkContext,
vertices: RDD[(K, V)],
messages: RDD[(K, M)],
combiner: Combiner[M, C],
aggregator: Option[Aggregator[V, A]],
partitioner: Partitioner,
numPartitions: Int,
storageLevel: StorageLevel = DEFAULT_STORAGE_LEVEL
)(
compute: (V, Option[C], Option[A], Int) => (V, Array[M])
): RDD[(K, V)] = {
val splits = if (numPartitions != 0) numPartitions else sc.defaultParallelism //分区数目
var superstep = 0 //迭代数目
var verts = vertices //存放顶点的RDD
var msgs = messages //存放消息的RDD
var noActivity = false //标志
var lastRDD: RDD[(K, (V, Array[M]))] = null
do {
logInfo("Starting superstep " + superstep + ".")
val startTime = System.currentTimeMillis //获得本次迭代步的开始时间
val aggregated = agg(verts, aggregator) //进行聚集,类似于MapReduce中的Aggregator
val combinedMsgs = msgs.combineByKey( //对消息进行合并
combiner.createCombiner _, combiner.mergeMsg _, combiner.mergeCombiners _, partitioner)
val grouped = combinedMsgs.groupWith(verts) //这一步骤是关键,将合并后的消息和定点RDD进 行JOIN,获得的类型是RDD[(K, (Iterable[C], Iterable[V])),也就是说,通过该步骤获得一个新的RDD该是消息和顶点的对应,依次为顶点ID、消息集合、顶点(集合),虽然是个集合其实这里实际上只有一个元素。
val superstep_ = superstep // Create a read-only copy of superstep for capture in closure
val (processed, numMsgs, numActiveVerts) = //这一步是关键,大家看到了这里调用了一个新的函数,这个函数下面再讲,此处的作用就是开始真正的计算了。
comp[K, V, M, C](sc, grouped, compute(_, _, aggregated, superstep_), storageLevel)
if (lastRDD != null) {
lastRDD.unpersist(false)
}
lastRDD = processed
val timeTaken = System.currentTimeMillis - startTime
logInfo("Superstep %d took %d s".format(superstep, timeTaken / 1000))
verts = processed.mapValues { case (vert, msgs) => vert }
msgs = processed.flatMap {
case (id, (vert, msgs)) => msgs.map(m => (m.targetId, m))
}
superstep += 1
noActivity = numMsgs == 0 && numActiveVerts == 0
} while (!noActivity)
verts
} 具体的参数不再介绍, 你会发现一个do-while循环,没错,这应该是进行模拟循环迭代的过程,也就是模拟BSP的过程。
下面具体来看一下如何计算的,我们知道,再Pregel中,每个超级不都会对所有active的定点执行用户定义的compute方法,那么Bagel中是如何实现的呢?看一下comp这个函数:
private def comp[K: Manifest, V <: Vertex, M <: Message[K], C](
sc: SparkContext,
grouped: RDD[(K, (Iterable[C], Iterable[V]))],
compute: (V, Option[C]) => (V, Array[M]),
storageLevel: StorageLevel
): (RDD[(K, (V, Array[M]))], Int, Int) = {
var numMsgs = sc.accumulator(0)
var numActiveVerts = sc.accumulator(0)
val processed = grouped.mapValues(x => (x._1.iterator, x._2.iterator))
.flatMapValues {
case (_, vs) if !vs.hasNext => None //如果找不到消息对应的定点就什么也不做
case (c, vs) => { //对消息做处理
val (newVert, newMsgs) =
compute(vs.next, //调用处理函数,这个函数就是用户自己实现的一个函数,下文会讲到
c.hasNext match {
case true => Some(c.next)
case false => None
}
)
numMsgs += newMsgs.size
if (newVert.active) {
numActiveVerts += 1
}
Some((newVert, newMsgs))
}
}.persist(storageLevel)
// Force evaluation of processed RDD for accurate performance measurements
processed.foreach(x => {}) //这步非常重要,强制spark提交任务,防止延后执行
(processed, numMsgs.value, numActiveVerts.value)
} 该函数是除了“顶点--消息”类型的RDD,返回的类型为(RDD[(K, (V, Array[M]))], Int, Int)
以此是处理过的消息,消息的数量以及激活状态下的定点的数量。这里还要提醒一点就是,在代码解析中最后那一步骤,就是强制spark提交job。大家知道,spark是一个延迟提交任务的系统,如果在你不使用最后的结果的时候spark是不会及时提交job的,换个角度说,spark会再RDD的某些特殊的action中进行隐式提交。 processed.foreach(x => {})就是进行了提交,如果不这样做,我们不会得到相应的结果,甚至整个逻辑就会出错,在这个过程中spark会无线的创建RDD并且创建他们之间的Depency,这样系统会崩溃掉。
看到这,大家应该能够明白一些,Bagel是如何进行迭代了吧,下面总结一下,再Bagel中使用Pregel框架写应用应该做哪些事情,应该注意哪些事情:
你要做的事情:
1. 你要实现一个Vertex接口,定义一下顶点该存什么。这个接口的定义在Bagel.scala这个源文件中。
2. 你要实现一个函数,该函数就是每一个超级步骤你要对每个vertex做的事情。
3. 你要实现一个message类,定义你的消息类型(实际上这中做法再Hama中也有,但是此处可能没 Hama那么灵活)
4. 如果有必要,你可以实现一个combier或者aggregator来提升性能。
你要注意的事情:
1. 最值得提的肯定要放在前面说,细心的你会发现源码中有很多类型的模版,比如V、M、C等等,这些都是类型的匹配,一定要弄清楚这些类型是什么意思。否则一会发现实现的时候很乱。下面来说一下这里面的类型,V顶点的类型,也就是你实现的Vertex类;M,消息的类型,也就是你实现的Message类;C,消息合并后的类型,也就是你通过combiner将消息合并以后的类型,如果不理解后边会再做解释。
2. 在你实现compute函数时,其实首先要注意该函数的(参数)格式是什么。其实根据Bagel的run函数的不同会出现很多格式的compute。先来看一个run中需要的compute函数的格式compute: (V, Option[C], Int) => (V, Array[M]),第一条介绍的自己对应吧,因此在实现的时候一定要注意类型的对应,特别是再有combiner函数时。联想我们的Hama和Giraph中,compute函数无非就是给了一个消息列表,然后自己再对这些消息进行处理。再Bagel中该消息列表换成了Option[C],那么这个C的类型就是我们自己定义的了。
3. 在实现combiner时,有很多注意的地方。先看一下combiner这个接口:
trait Combiner[M, C] {
def createCombiner(msg: M): C
def mergeMsg(combiner: C, msg: M): C
def mergeCombiners(a: C, b: C): C
} 如果有必要,我们可以实现自己的combiner来提速,比如说再sssp中,我们可以在combiner中将众多的消息转换成一个最小的值,那么此时C就是一个具体的值;如果我们不想设置combiner而是想直接拿到消息列表,我们可以不定义Combiner,但此时需要注意的是,你需要讲C的类型设置为Array[M](主要是再compute实现中),这是因为我们即使自己没有设置combiner,Bagel会为我们设置一个默认的,即:
class DefaultCombiner[M: Manifest] extends Combiner[M, Array[M]] with Serializable {
def createCombiner(msg: M): Array[M] =
Array(msg)
def mergeMsg(combiner: Array[M], msg: M): Array[M] =
combiner :+ msg
def mergeCombiners(a: Array[M], b: Array[M]): Array[M] =
a ++ b
} 该Combiner其实就是简单的将消息进行堆积,堆积成一个Array[M]的类型。那么我们在写compute函数时就将其中的C设置成Array[M]就可以了。
总结:
Bagel是spark版本的Pregel,用了很少的代码,而且利用了Spark很多的RDD优势,比如在Hama中,你会明显的发现有sendmessage这些操作,但是在spark中消失了,消息的传递无非就是消息RDD和顶点RDD之间的一个Cogroup操作,本质上也是数据的传输。在学习Bagel的同时,一直比较着Hama和Giraph,产生了很多的想法,文章中也做了很多的对比,这些都是自己的观点,肯定有些不对的地方,希望大家能多多指教。















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









