







java基础之集合框架–HashMap深入理解及应用
接着上一篇写,在分析之前,先想想几个问题,方便后面理解
1.HashMap的底层结构是什么,画出来;
2.再用HashMap的时候会考虑他的容量吗?它的默认容量是多少,加如超过了你初始化的容量会发生什么?
3.HashMap key是否可以为null;
4.自己实现一个简单的HashMap(HashMap的实现原理)
HashMap底层结构
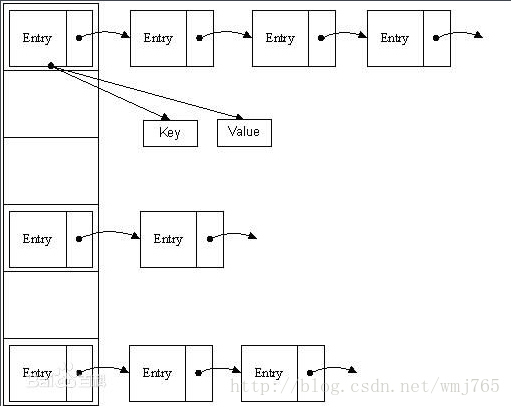
上图即为hashMap的底层存储结构图,可以看出,其实就是一个类似数组+链表来存储的,数组默认长度为16;那么数组中如何来存储key,value对象呢?来看下hashMap的源码,我直接拿jdk 1.8的源码来
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
//存放key value值得数组
transient Node<K,V>[] table;
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//存放key Value及下个元素的标识next
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}其实存放key,value就放在这个Node里面,Node会在第一次初始化赋值,它为一个静态的内部类,实现了Map.Entry内部接口;
当map.put元素的时候,hashMap会根据hashcode值来计算出一个index,来存放此对象;若下一个对象算出的index值与第一个index值相同,则将原始的next标记为下一个对象,这样就形成了单项有序的链表;
再来看一下HashMap的put怎么实现的:
/**
* Implements Map.put and related methods
*
* @param hash key的hash值
* @param key
* @param value the value to put
* @param onlyIfAbsent 判断是否为重复的key,若true,则改变value值,默认为false
* @param evict 是否为初始化map,默认true
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//赋值tab,判断table是否为空
if ((tab = table) == null || (n = tab.length) == 0)
//若为空,则赋值n为0
n = (tab = resize()).length;
//(n - 1) & hash计算index,若tab空,则新赋值,并将next设为null;
if ((p = tab[i = (n - 1) & hash]) == null)
//为此index赋值
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//若Index处有值,则将此处值得next赋给新值
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//若key已经存在,则将此key处的值替换
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//计算大于威胁容量
resize();
afterNodeInsertion(evict);
return null;
}上面代码我加了写注释,简单点说,就是put新值的时候,先存储起来,放在一个Node里面,index是0,在次put的时候,先计算index值,(n - 1) & hash;若index相同,则将值放在next里,若不相同,则将值放在新的index里;
get值得时候同理,先计算index值,然后再根据index值来看有没有这个key,没有在看next里有没有;
if (++size > threshold)//计算大于威胁容量
resize();下面说下这段代码的意义,即我们讨论的map容量与扩容问题。threshold参数的意义为威胁容量,当我们的size大于威胁容量的时候,map就会扩容处理;当默认容量为16时,威胁容量为12,若map得size大于12时,则会进入risize方法,并对容量及威胁容量都进行双倍扩容处理;关键代码
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//newCap双倍扩容
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 双倍扩容
}HashMap暂时就分析到这,上面几个问题的答案也就都出来了,还有好多细节方面的知识,包括怎么计算算出index值中的参数;值得我们深入研究下并借鉴。















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









