






Superset部署
大纲
1、启动EC2
启动一台Amazon Linux EC2并安装启动docker环境,需要机型为t.xlarge及以上,EBS盘20GB以上。
sudo yum update -y
# install python3 gcc
sudo yum install -y python3 libpq-dev python3-dev
sudo yum install -y gcc gcc-c++
# add following into ~/.bashrc
echo "export PATH=/usr/local/bin:$PATH" >> ~/.bashrc
echo "alias python=python3" >> ~/.bashrc
echo "alias pip=pip3" >> ~/.bashrc
source ~/.bashrc
python --version
# install docker
sudo yum -y install docker
sudo usermod -a -G docker ec2-user
sudo systemctl start docker
sudo systemctl status docker
sudo systemctl enable docker
sudo chmod 666 /var/run/docker.sock
docker ps
# install docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
docker-compose --version
1.2、下载Superset Docker文件
sudo yum install -y git curl
git clone https://github.com/apache/incubator-superset/
1.3、修改Dockerffile
cd incubator-superset
vi Dockerfile
在末尾添加
RUN pip install PyAthenaJDBC \ #这个是athena连接
&& pip install PyAthena \ #这个是athena连接
&& pip install psycopg2 \
&& pip install sqlalchemy-redshift # 这个是redshift连接
构建
docker-compose build
docker-compose up
1.4、配置管理员
需要配置管理员用户权限,在docker/docker-init.sh中默认创建用户admin(密码也是admin)但权限并没有更新,通过以下命令更新权限
#进入docker
docker-compose exec superset bash
superset init
1.5、结果展示
配置成功后,Superset默认使用8088端口,使用http://<EC2 公有IP>:8088访问,默认用户名和密码均为admin 可在Dockerfile、docker中命令、管理页面更改
1.6、检查数据库驱动
查看数据库驱动是否安装成功

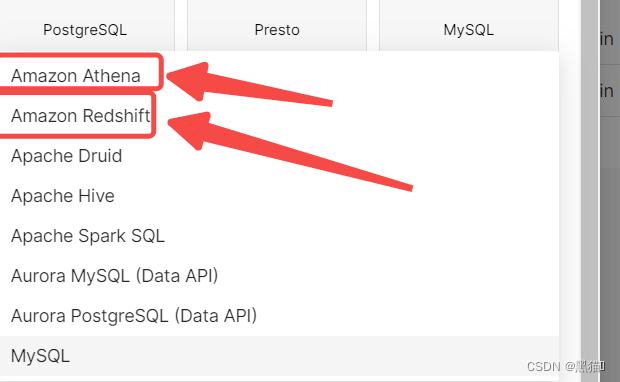 若没有
若没有
#进入docker
docker-compose exec superset bash
#安装 athena 和redshift驱动
pip install PyAthenaJDBC \
&& pip install PyAthena \
&& pip install psycopg2 \
&& pip install sqlalchemy-redshift
1.7 、常见错误处理
build中如果出现error
ERROR: Couldn't connect to Docker daemon at http+docker://localunixsocket - is it running?
原因:
1、docker 没有启动
sudo systemctl start docker
2、用户不再docker用户组里面
sudo gpasswd -a ${USER} docker
如果是第二个,请退出shell 再次登陆
2、Glue(可选参考)
3、IAM与安全组
部署Superset的EC2附加的IAM角色需要有 Athena查询和Glue Catalog的权限,为方便起见可以赋予AthenaFullAccess和GlueFullAccess。但实际情况请按照最小权限原则来保障安全。
3.1、使用 athena
如果在 Amazon Athena 中运行查询时,出现 “Access Denied”(拒绝访问)错误
Your query has the following errors:Access denied when writing output to url: s3://my-athena-result-bucket/Unsaved/2021/05/07/example_query_ID.csv . Please ensure you are allowed to access the S3 bucket. If you are encrypting query results with KMS key, please ensure you are allowed to access your KMS key
向 IAM 用户授予所需的权限。以下 IAM 策略允许源数据存储桶和查询结果存储桶的最低权限:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::【数据源的s3名称】"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::【数据源的s3名称】/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:AbortMultipartUpload",
"s3:PutObject",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::【存储Athena查询结果的s3名称】",
"arn:aws:s3:::【存储Athena查询结果的s3名称】/*"
]
}
]
}
请务必在此示例策略中替换【】中的内容
3.2、使用RedShift或RDS
此处以RedShift集群为例
I、查看redshift集群VPC安全组

II、进入superset所在EC2实例安全组
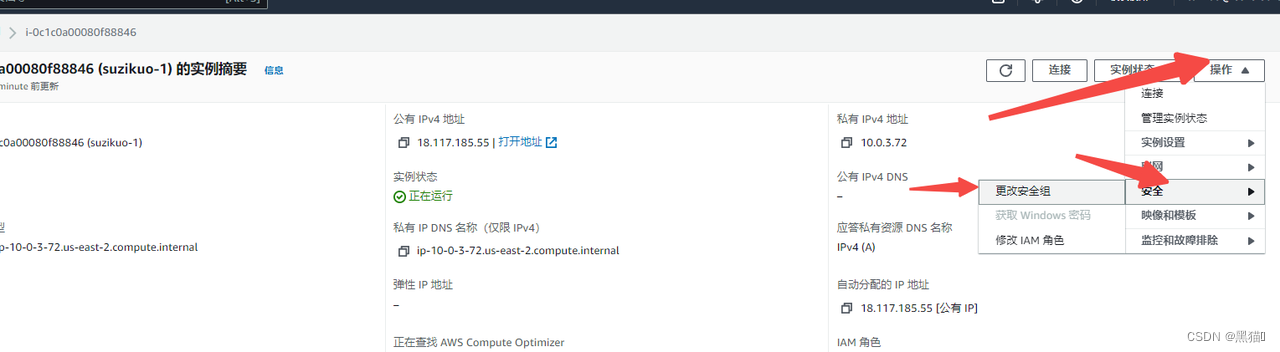
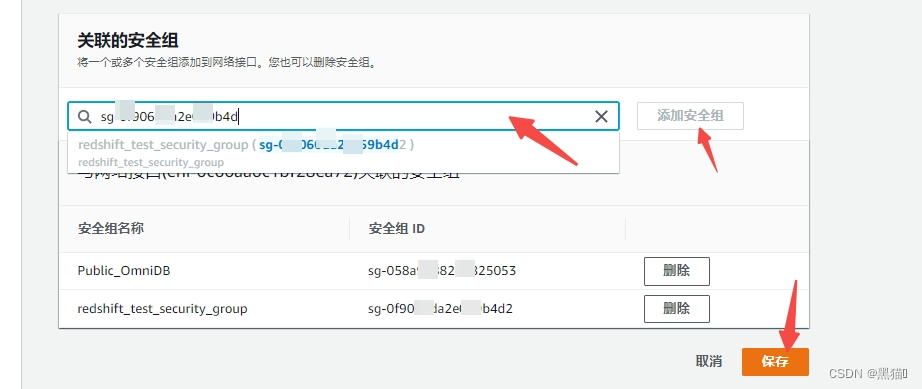
III、添加入站规则
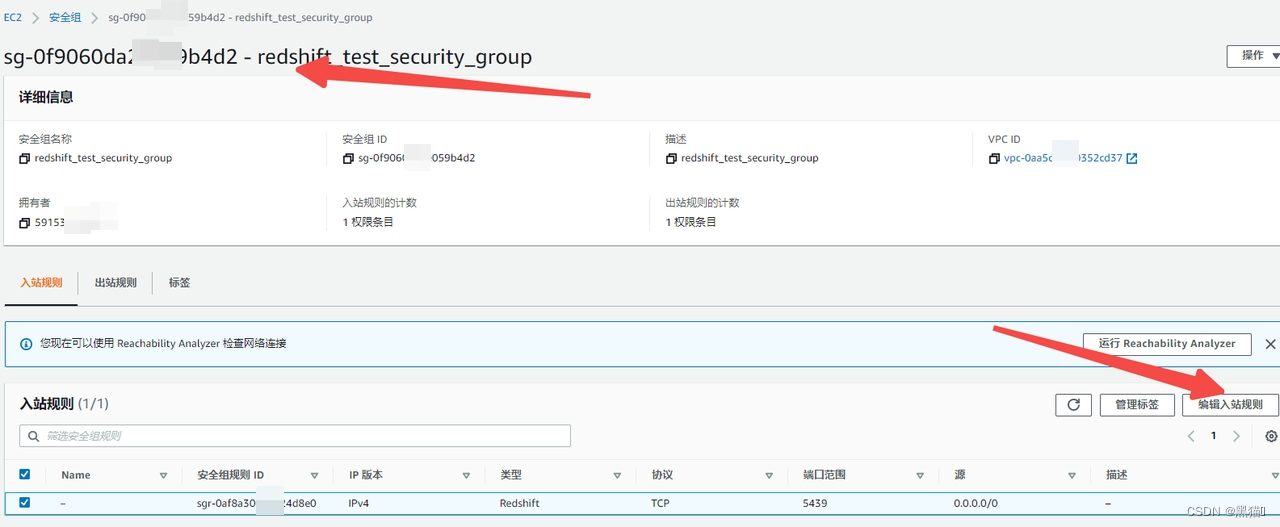

4、SUPERSET配置数据源并创建DASHBOARD
此处提供了Athena与RedShift的连接教程,其他JDBC语法请看官方文档
4.1、连接Athena
awsathena+rest://@athena.{region}.amazonaws.com.cn/<Glue数据库表>?s3_staging_dir=<用来存储查询结果的S3地址>

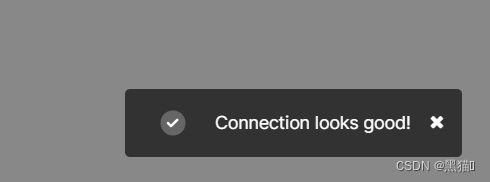
Test connection
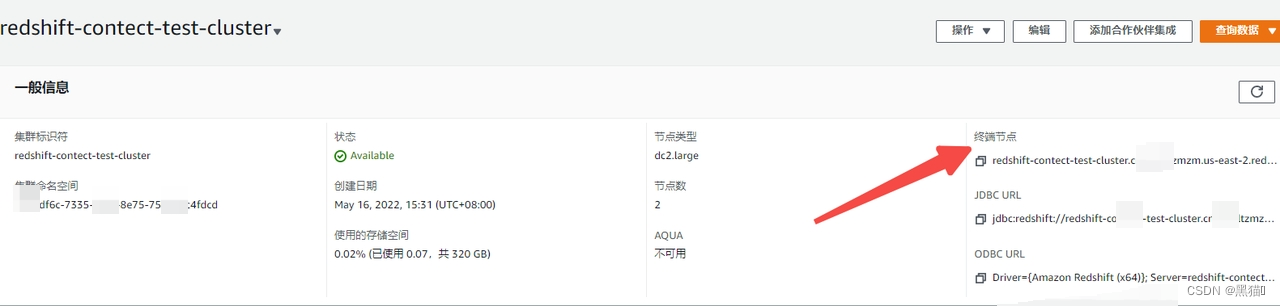
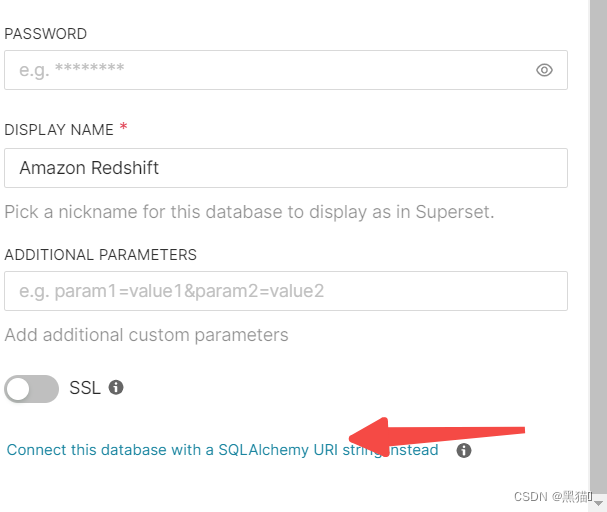
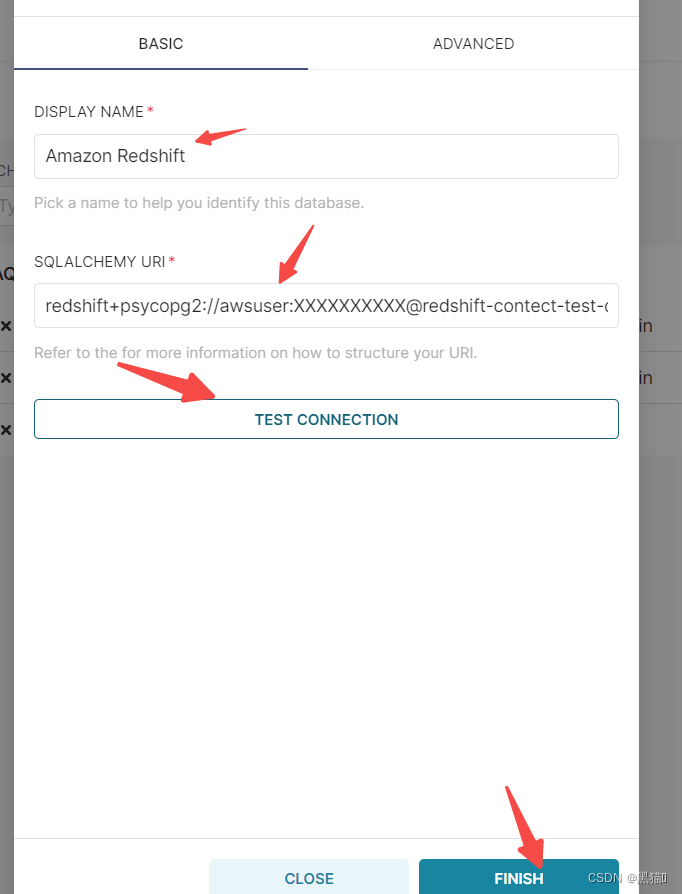
4.2、连接redshift
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:<port>/<Database Name>
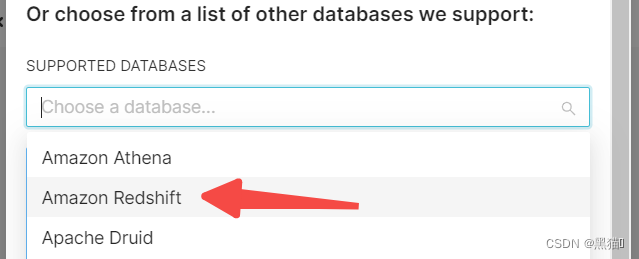
创建连接















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









