







HADOOP3.x安装
| hdp01 | hdp02 | hdp03 |
|---|---|---|
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| NameNode | NameNode | NameNode |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
| mysql | ||
| hiveserver2 | hiveserver2 |
一,JDK下载安装教程
1.配置阿里云镜像源
yum install -y wget
mkdir /etc/yum.repos.d/bak
mv /etc/yum.repos.d/CentOS-* /etc/yum.repos.d/bak
cd /etc/yum.repos.d/
wget http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
下载JDK1.8
所有节点都要配置JDK环境
yum install -y java-1.8.0-openjdk.x86_64
java -version

配置java环境变量,这里不配置后面启动hdfs服务会报错找不到JAVA_HOME
vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.372.b07-1.el7_9.x86_64/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin

部署前准备
关闭selinux
setenforce 0
永久关闭
vi /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled,然后保存退出
关闭防火墙
systemctl stop firewalld.service
systemctl enabled firewalld.service
关闭Swap
https://blog.csdn.net/wanghailan1818/article/details/120969107
二,配置免密
先配置好 /etc/hosts
1.脚本免密方式
免密脚本下载:https://blog.csdn.net/wn_96/article/details/126231663
上面是我自己写的一个免密脚本,也有教程,使用也很简单
2.手动免密方式
echo "n"|ssh-keygen -t rsa -N '' -f /root/.ssh/id_rsa -q
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
#$hostname 是主机名,这里自身和其他节点都要做免密
ssh-copy-id -i /root/.ssh/id_rsa.pub $hostname

三,HADOOP3.X安装流程:**
hadoop3.3.1下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
cd /data/
tar -xf hadoop-3.3.1.tar.gz
修改 core-site.xml 和 hdfs-site.xml 配置
vim /data/hadoop-3.3.1/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 把多个 Namenode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/bigdata/data</value>
</property>
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
vim /data/hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- namenode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- datanode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- Journalnode 数据存储目录 -->
<property>
<name>dfs.Journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 namenode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- namenode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hdp01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hdp02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hdp03:8020</value>
</property>
<!-- namenode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hdp01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hdp02:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hdp03:9870</value>
</property>
<!-- 指定 namenode 元数据在 Journalnode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp01:8485;hdp02:8485;hdp03:8485/mycluster</value>
</property>
<!-- 访问代理类: client 用于确定哪个 namenode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
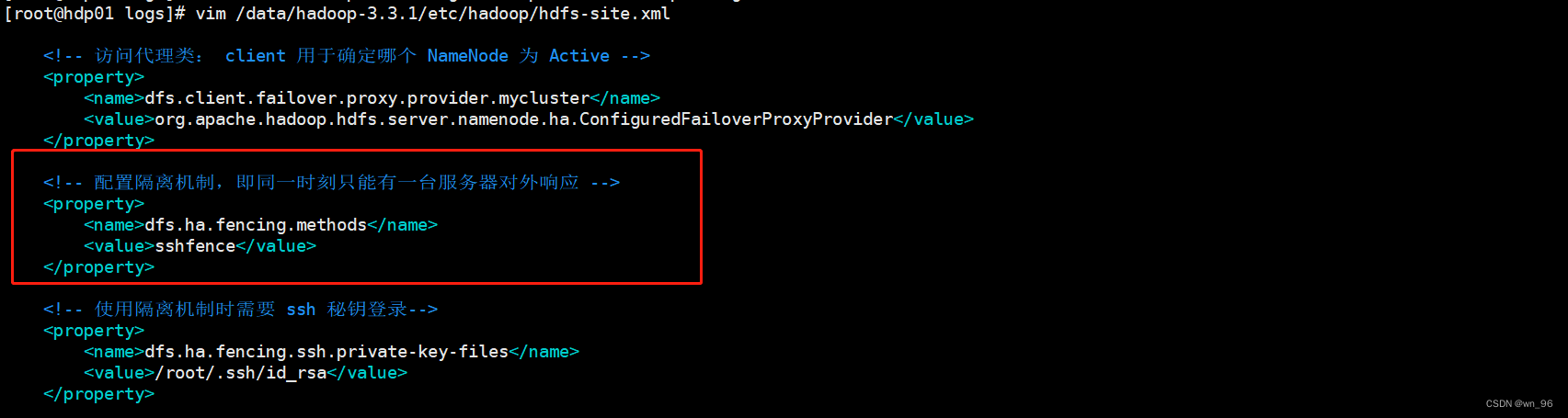
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 如果是通过公网IP访问需要配置 -->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only cofig in clients</description>
</property>
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
配置hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/data/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
刷新配置文件
source /etc/profile
启动所有节点 journalnode
hdfs --daemon start journalnode
初始化 &&启动 NameNode
在hdp01(主)节点上上执行:
hdfs namenode -format
hdfs --daemon start namenode

在其他(复)节点上执行:
1.同步主节点元数据信息
hdfs namenode -bootstrapStandby

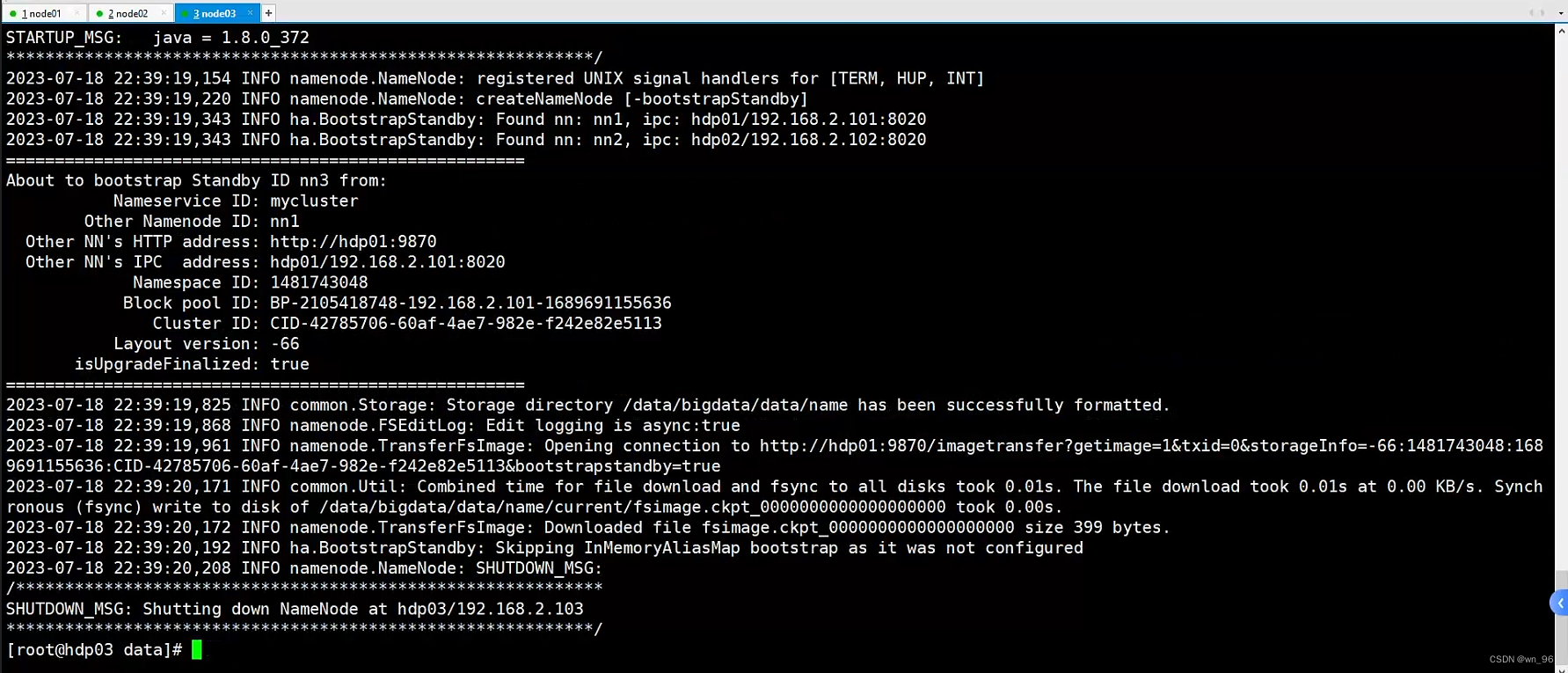
2.启动复节点 NN
hdfs --daemon start namenode
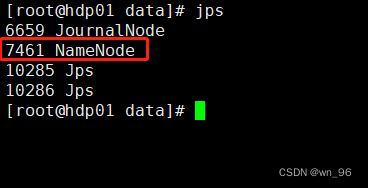
http://hdp01:9870
http://hdp02:9870
http://hdp03:9870
如果是云主机搭建时需要把云主机的9870端口开放,非云主机略过此步骤
下面时腾讯云主机例子:


再次访问就可以了
我这里是本地搭建过一版,发现本地资源根本不够用又买的的云主机,如果只是搭建练习用本地VM就好了
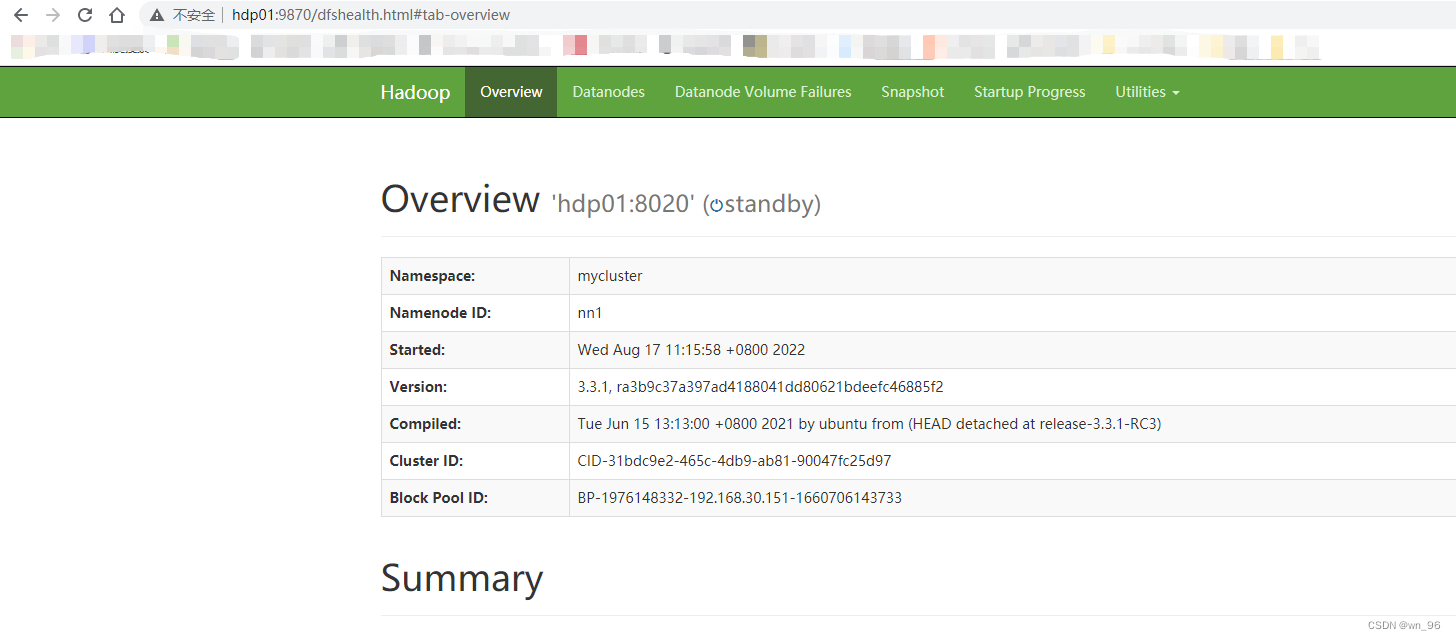
所有节点启动DataNode
添加worker信息
#所有节点都修改
vim /data/hadoop-3.3.1/etc/hadoop/workers
启动datanode
hdfs --daemon start datanode

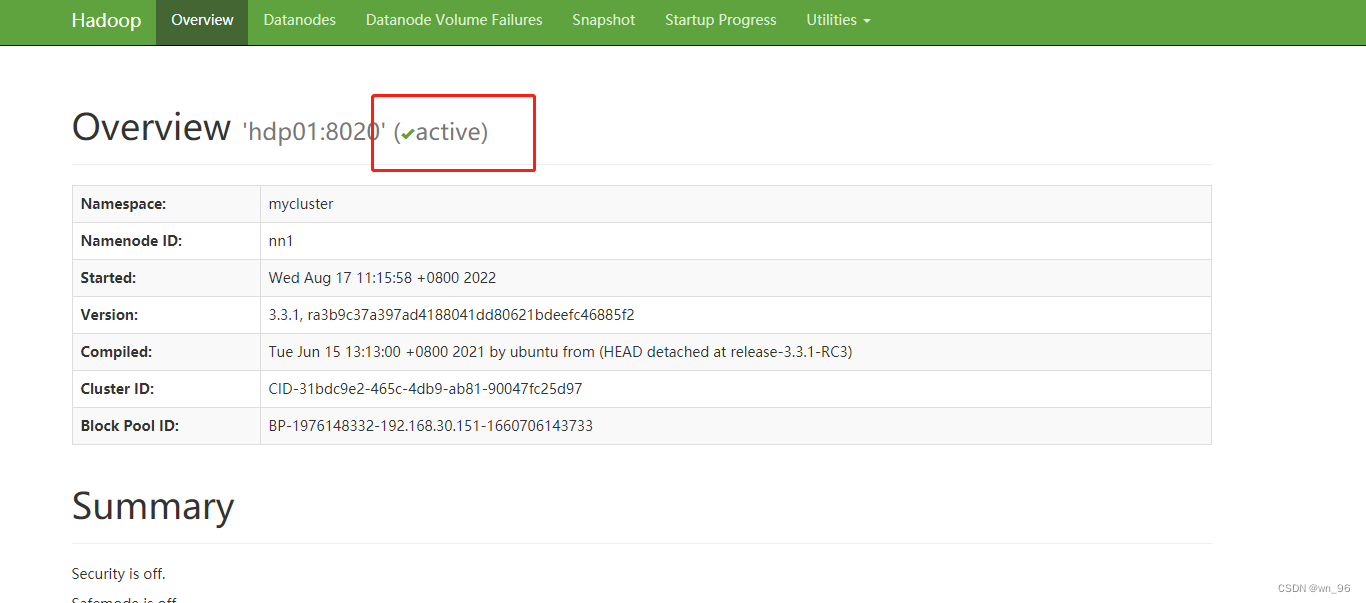
将hdp01节点所在NameNode转换为active
hdfs haadmin -transitionToActive nn1
hdfs haadmin -getServiceState nn1

四,安装ZOOKEEPER步骤
下载路径:http://archive.apache.org/dist/zookeeper/
cd /data
tar -xf zookeeper-3.4.9.tar.gz
mv zookeeper-3.4.9 zookeeper
修改配置文件
mv /data/zookeeper/conf/zoo_sample.cfg /data/zookeeper/conf/zoo.cfg
vim /data/zookeeper/conf/zoo.cfg
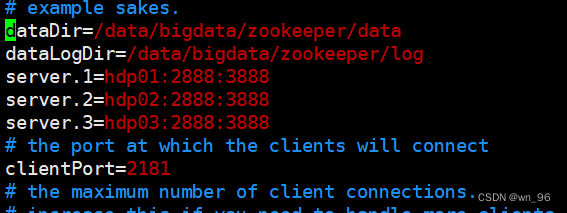
修改或添加内容:
dataDir=/data/bigdata/zookeeper/data
dataLogDir=/data/bigdata/zookeeper/log
# server.serverid=host:tickpot:electionport
server.1=hdp01:2888:3888
server.2=hdp02:2888:3888
server.3=hdp03:2888:3888
#server:固定
#serverid:每个服务器的指定ID
#host:主机名或者IP
#tickpot:心跳通信端口
#electionport:选举端口
vim /data/zookeeper/conf/log4j.properties
修改内容:
zookeeper.root.logger=INFO, ROLLINGFILE
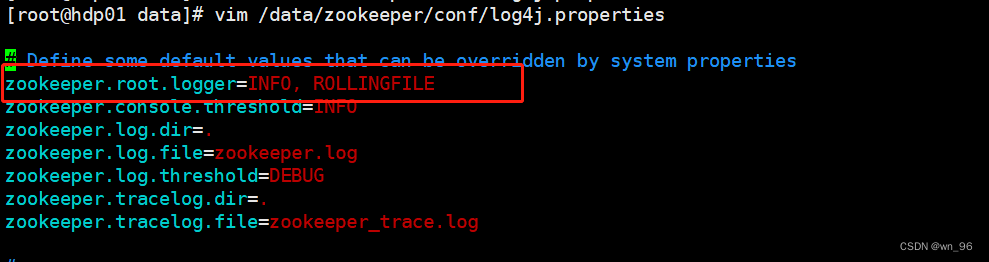
vim /data/zookeeper/bin/zkEnv.sh
修改内容:
ZOO_LOG_DIR 对应 /data/zookeeper/conf/zoo.cfg 下的 dataLogDir
ZOO_LOG4J_PROP 对应 /data/zookeeper/conf/log4j.properties 下的 ZOO_LOG4J_PROP
ZOO_LOG_DIR="/data/bigdata/zookeeper/log"
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
分发配置好的安装包&&创建日志和数据目录
ssh hdp01 mkdir -p /data/bigdata/zookeeper/data
ssh hdp01 mkdir -p /data/bigdata/zookeeper/log
ssh hdp02 mkdir -p /data/bigdata/zookeeper/data
ssh hdp02 mkdir -p /data/bigdata/zookeeper/log
ssh hdp03 mkdir -p /data/bigdata/zookeeper/data
ssh hdp03 mkdir -p /data/bigdata/zookeeper/log
scp -r /data/zookeeper hdp02:/data
scp -r /data/zookeeper hdp03:/data
创建myid
#myid在每个节点上的数字是不同的,例如hdp01是1,hdp02是2,hdp03是3
#hdp01节点上运行:
cd /data/bigdata/zookeeper/data
echo 1 > myid
#hdp02节点上运行:
cd /data/bigdata/zookeeper/data
echo 2 > myid
#hdp03节点上运行:
cd /data/bigdata/zookeeper/data
echo 3 > myid
配置环境变量
vim /etc/profile
export ZOOKEEPER=/data/zookeeper
export PATH=$PATH:$ZOOKEEPER/bin

启动所有节点ZK服务
所有节点执行:
/data/zookeeper/bin/zkServer.sh start
/data/zookeeper/bin/zkServer.sh status
两个follower一个leader正常

附赠内容 zk批量启动脚本
友情链接:https://blog.csdn.net/lzb348110175/article/details/97627483
# zk服务start/stop/restart/status一键式脚本
#!/bin/bash
# zk所在服务器地址(根据个人地址修改)
server=("hdp01" "hdp02" "hdp03")
# zk安装路径地址
zkPath="/data/zookeeper"
# zk启动
function zk_start(){
echo "start zkServer..."
for i in ${server[@]};
do
echo "===============${i}==============="
ssh ${i} "source /etc/profile;${zkPath}/bin/zkServer.sh start"
done
}
# zk关闭
function zk_stop(){
echo "stop zkServer..."
for i in ${server[@]};
do
echo "===============${i}==============="
ssh ${i} "source /etc/profile;${zkPath}/bin/zkServer.sh stop"
done
}
# 查看zk状态
function zk_status(){
echo "zkServer status..."
for i in ${server[@]};
do
echo "===============${i}==============="
ssh ${i} "source /etc/profile;${zkPath}/bin/zkServer.sh status"
done
}
case $1 in
"start")
zk_start
;;
"stop")
zk_stop
;;
"restart")
zk_stop
sleep 2
zk_start
;;
"status")
zk_status
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
五,HA-NameNode
停止 hdfs 集群
/data/hadoop-3.3.1/sbin/stop-dfs.sh
如果启动时遇到用户启动错误时
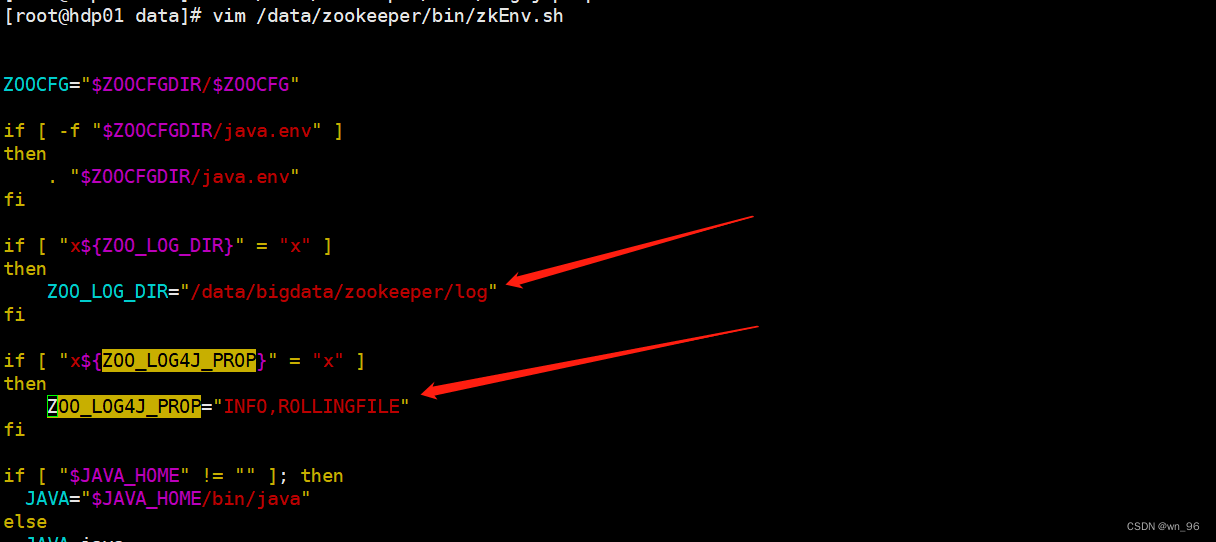
vim /data/hadoop-3.3.1/etc/hadoo/hadoop-env.sh
添加内容:
export JAVA_HOME=/data/jdk1.8
export HADOOP_HOME=/data/hadoop-3.3.1
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
export HADOOP_PID_DIR=${HADOOP_HOME}/pid
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
重启ZK
所有节点执行:
/data/zookeeper/bin/zkServer.sh stop
/data/zookeeper/bin/zkServer.sh start
初始化 HA 在 Zookeeper 中状态
随便一个节点执行就行:
hdfs zkfc -formatZK
启动HDFS服务
start-dfs.sh
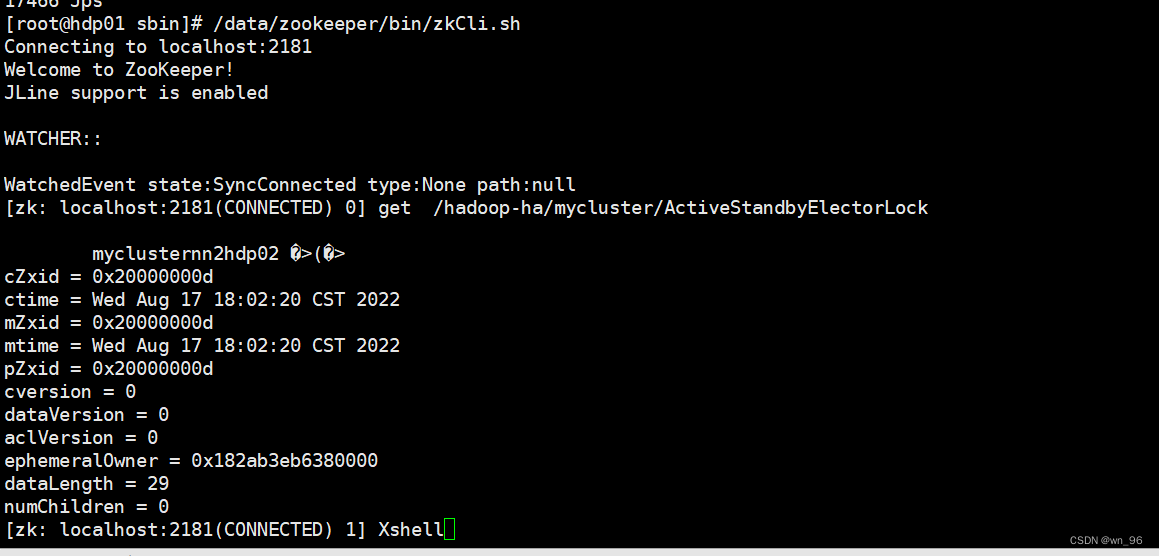
在ZK中查看NN注册状态
/data/zookeeper/bin/zkCli.sh
get /hadoop-ha/mycluster/ActiveStandbyElectorLock
测试NameNode HA
查看哪个节点的NN是active
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -getServiceState nn3
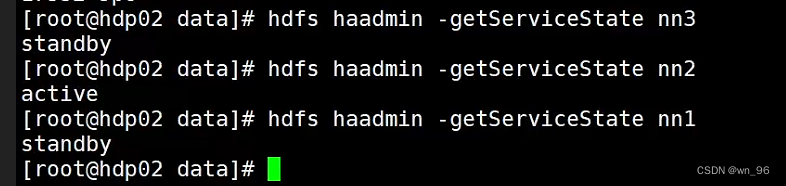
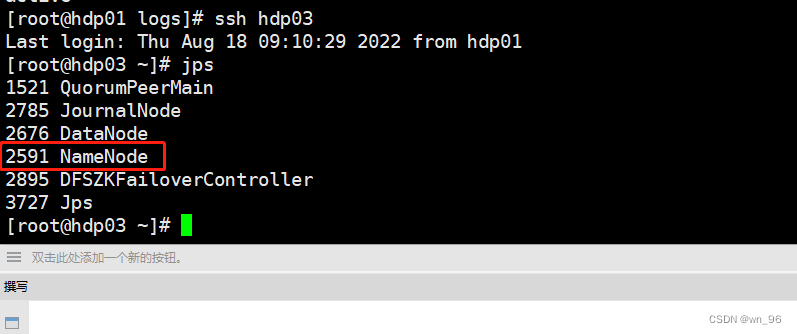
kill active的 NN进程
#上方看到的是nn3为active而我们在hdfs-site.xml中对应hdp03的就是nn3
ssh hdp03
kill `jps |grep NameNode |awk -F ' ' '{print $1}'`

通过zookeeper查看active的NN节点
zkCli.sh
get /hadoop-ha/mycluster/ActiveStandbyElectorLock
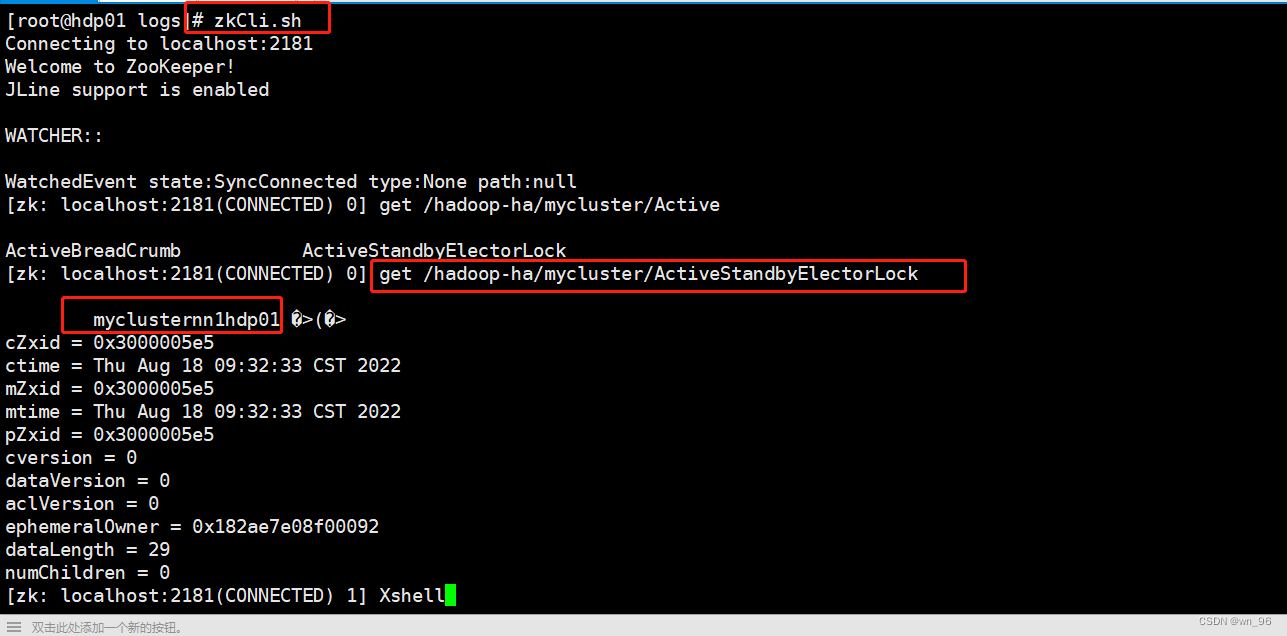
nn1已经变为active

NN状态如果没有自动切换,并且ZKFC日志报了这个错查看hdfs-site.xml配置
vim /data/hadoop-3.3.1/logs/hadoop-root-zkfc-hdp01.log
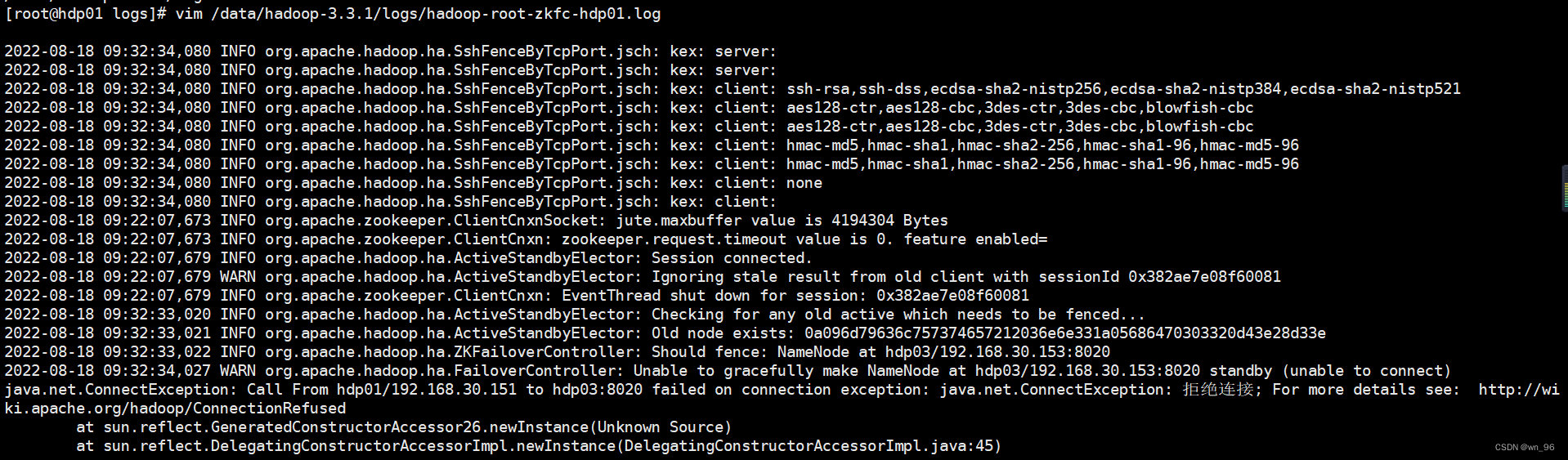
所有节点都要检查
vim /data/hadoop-3.3.1/etc/hadoop/hdfs-site.xml
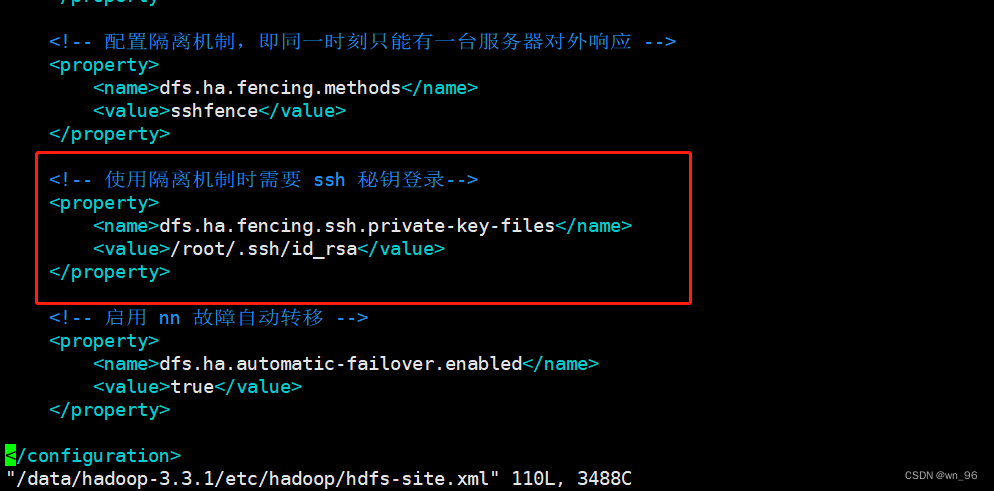
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
切换时需要依赖到psmisc,我们这里通过yum安装 所有节点
yum install -y psmisc
如果还是无法切换成功检查 ssh免密 ,包括自身免密,hdfs-site.xml中也要指定私钥
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
六,HA-YARN
修改配置
vim /data/hadoop-3.3.1/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp01</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hdp01:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hdp01:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hdp01:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hdp01:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp02</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hdp02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hdp02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hdp02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hdp02:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_HOME,ZOOKEEPER,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property><!-- 执行一个mr的job时 的最大最小空间 -->
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2000</value>
</property>
<property><!-- NodeManager给ResourceManager 能给的最多内存-->
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2000</value>
</property>
<property>
<!--physical物理内存的使用检查,如果为true,那么一旦超过前面的最大值,就会直接杀死该进程-->
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!--virtual物理内存的使用检查-->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value> <!-- true就是 启动日志服务器 -->
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hdp01:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
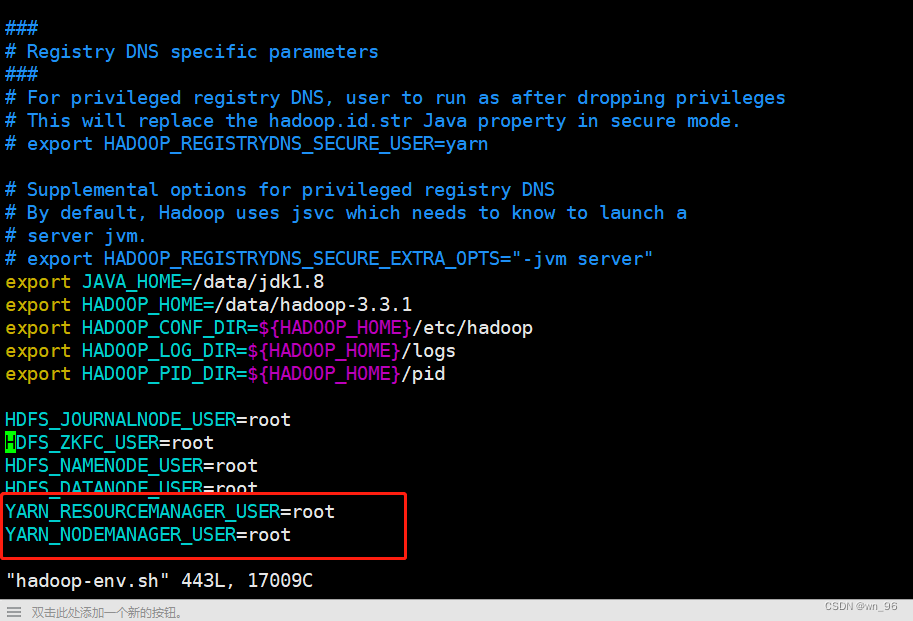
所RM和NM节点都改掉
vim /data/hadoop-3.3.1/etc/hadoop/hadoop-env.sh
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
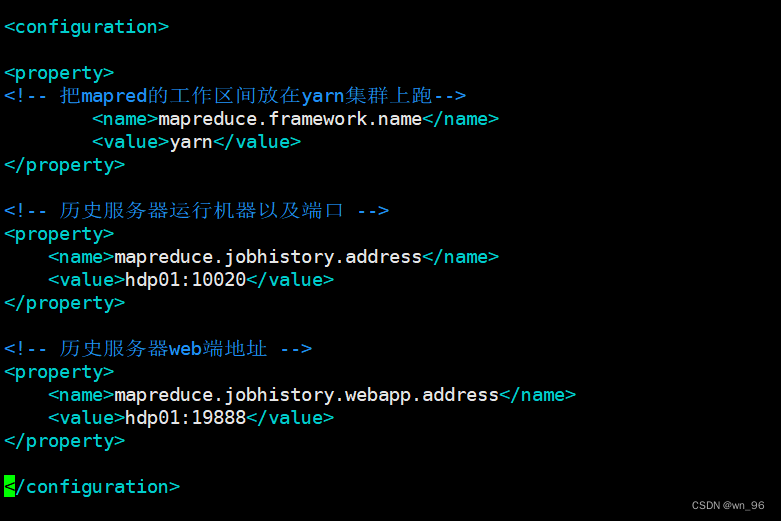
vim /data/hadoop-3.3.1/etc/hadoop/mapred-site.xml
<configuration>
<property>
<!-- 把mapred的工作区间放在yarn集群上跑-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器运行机器以及端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp01:19888</value>
</property>
</configuration>
下发配置
scp -r /data/hadoop-3.3.1/etc/hadoop/yarn-site.xml hdp02:/data/hadoop-3.3.1/etc/hadoop/yarn-site.xml
scp -r /data/hadoop-3.3.1/etc/hadoop/yarn-site.xml hdp03:/data/hadoop-3.3.1/etc/hadoop/yarn-site.xml
scp -r /data/hadoop-3.3.1/etc/hadoop/mapred-site.xml hdp02:/data/hadoop-3.3.1/etc/hadoop/mapred-site.xml
scp -r /data/hadoop-3.3.1/etc/hadoop/mapred-site.xml hdp03:/data/hadoop-3.3.1/etc/hadoop/mapred-site.xml
启动 yarn
start-yarn.sh
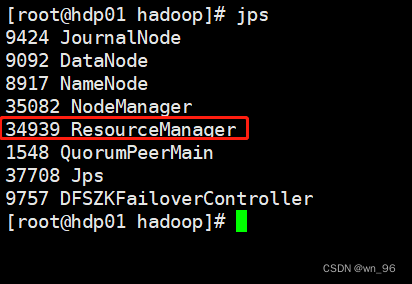
查看rm的active是哪个节点
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
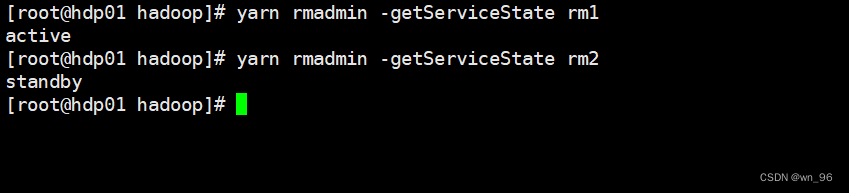
http://hdp01:8088/cluster/scheduler

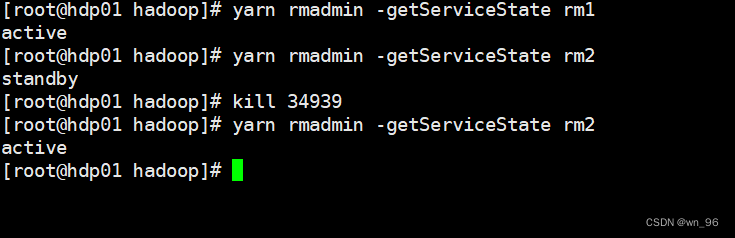
测试HA-Yarn
kill 了 rm1的 RM进程查看 rm2已经变为active
七,报错:
HDFS执行命令时出现报错但不影响操作:
2022-08-18 15:23:40,180 INFO retry.RetryInvocationHandler: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error

**解决办法:**把active NameNode Kill再起来就好了
八,HIVESERVER2-HA安装
hive下载地址:https://dlcdn.apache.org/hive/
mysql-connector-java.jar下载地址:https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.30.tar.gz
mysql8.0下载地址:wget https://dev.mysql.com/get/mysql80-community-release-el7-5.noarch.rpm
安装mysql
yum localinstall mysql80-community-release-el7-5.noarch.rpm
yum clean all
yum makecache
yum install -y mysql-community-server
systemctl start mysqld
systemctl status mysqld
systemctl enable mysqld
#查看root初始化密码
grep "password" /var/log/mysqld.log

mysql -uroot -p'取到的初始化密码'
--修改密码策略
set global validate_password.policy=LOW;
set global validate_password.mixed_case_count=0;
set global validate_password.number_count=0;
set global validate_password.special_char_count=0;
set global validate_password.length=1;
set global validate_password.check_user_name='OFF';
--这里将roo密码修改为 root
update mysql.user set host="%" where user='root';
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root';
--这里创建好库等会初始化会用到
create database hivedb;
执行以上语句时如果遇到下方报错:

按照现有的密码规则改下密码就可以操作了,这里的密码是刚刚 grep “password” /var/log/mysqld.log获得的密码随便在后边加个数字
alter user 'root'@'localhost' identified by '1ytEl&8S!5Vq2';
安装HIVE(hdp02,hdp03都要安装)
cd /data
tar xf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin hive-3.1.2
这里会有版本不适用的问题,需要用hadoop下的包替换掉hive中的
mv /data/hive-3.1.2/lib/guava-19.0.jar /data/hive-3.1.2/lib/guava-19.0.jar.bak
cp /data/hadoop-3.3.1/share/hadoop/common/lib/guava-27.0-jre.jar /data/hive-3.1.2/lib/
#mysql链接jar包,上面给了mysql-connector的包链接
cp /data/mysql-connector-java-8.0.30/mysql-connector-java-8.0.30.jar /data/hive-3.1.2/lib/
添加配置
hive-site.xml本来是没有的,自己创建一个就行下面文件的所有内容,hostname记得改成自己的
vim /data/hive-3.1.2/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!-- 修改为你自己的Mysql地址 -->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hdp03:3306/hivedb?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- 修改为你自己的Mysql账号 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 修改为你自己的Mysql密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!-- 忽略HIVE 元数据库版本的校验,如果非要校验就得进入MYSQL升级版本 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
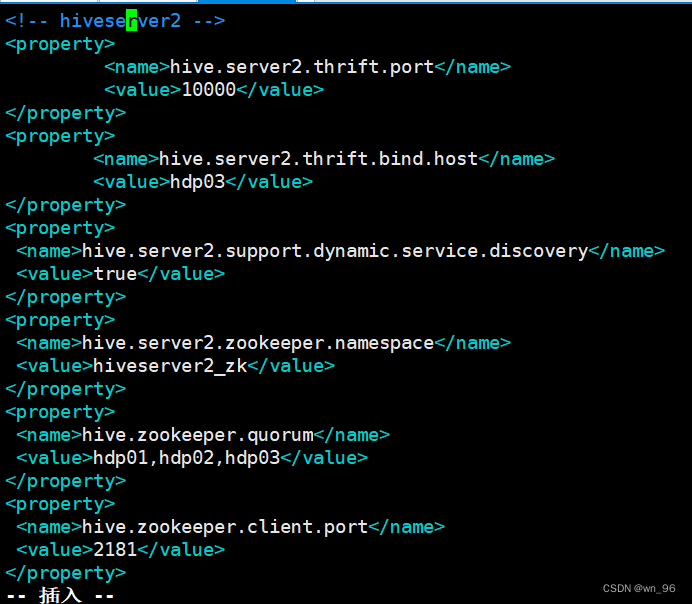
<!-- hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<!-- hdp02上配置时就写hdp02 -->
<name>hive.server2.thrift.bind.host</name>
<value>hdp03</value>
</property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>hdp01,hdp02,hdp03</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
</configuration>
vim /data/hive-3.1.2/conf/hive-env.sh
export JAVA_HOME=/data/jdk1.8
export HADOOP_HOME=/data/hadoop-3.3.1
export HIVE_CONF_DIR=/data/hive-3.1.2/conf
export HIVE_HOME=/data/hive-3.1.2
vim /etc/profile
#HIVE
export HIVE_HOME=/data/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
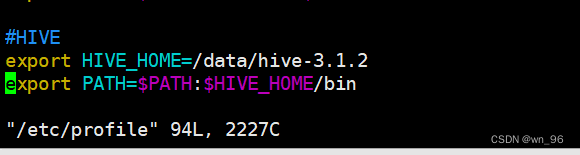
source /etc/profile
在其中一台hiveserver2上初始就行
schematool -dbType mysql -initSchema
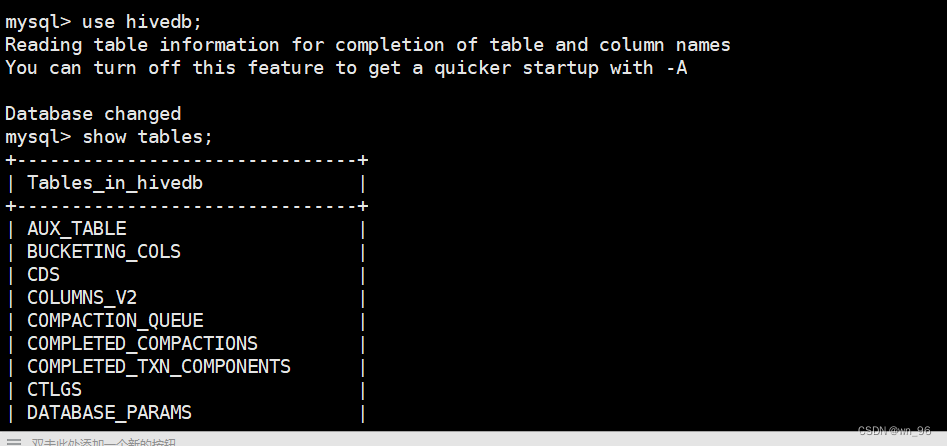
mysql -uroot -proot
use hivedb;
show tables;
hive
create database student;
create table student(id int,name string);
insert into student values(1,"addd");
select * from student;
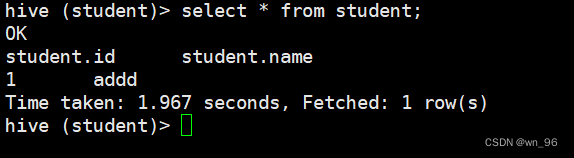
到这里说明hive数据库搭建的没没问题了
启动hivesever2
mkdir -p /data/hive-3.1.2/logs
hiveserver2 > /data/hive-3.1.2/logs/hive2.log 2>&1 &

hiveserver的配置咱们在上面已经配置好了直接运行就行了
hdp02,hdp03都起来后,过个1分中左右去ZKcli中看下信息是否有注册成功
mkdir -p /data/hive-3.1.2/logs
hiveserver2 > /data/hive-3.1.2/logs/hiveserver2_$(date +%Y-%m-%d-%H-%M-%S).log 2>&1 &
jps
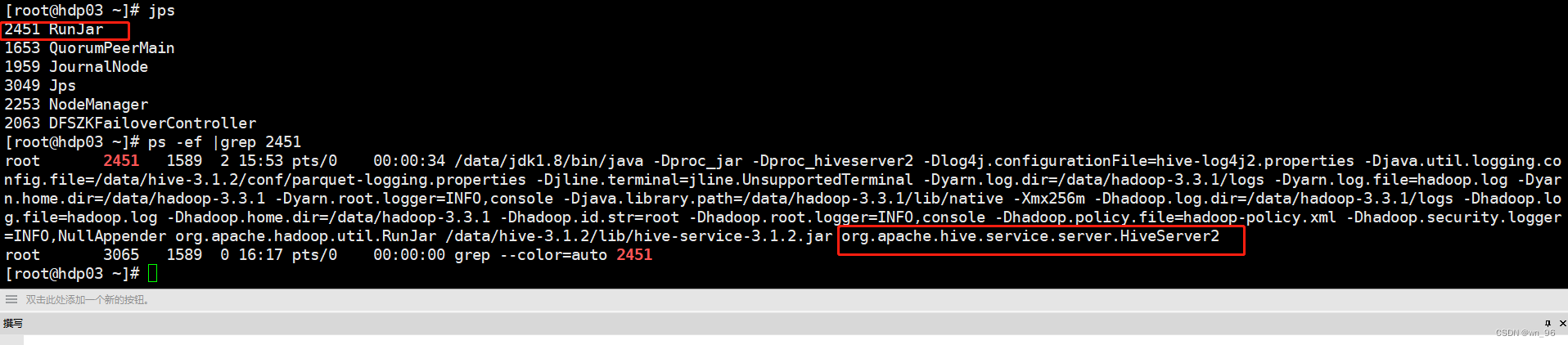
这里hiveserver2启动的比较慢需要等一会,zk中才能查到信息
zkCli.sh
ls /hiveserver2_zk
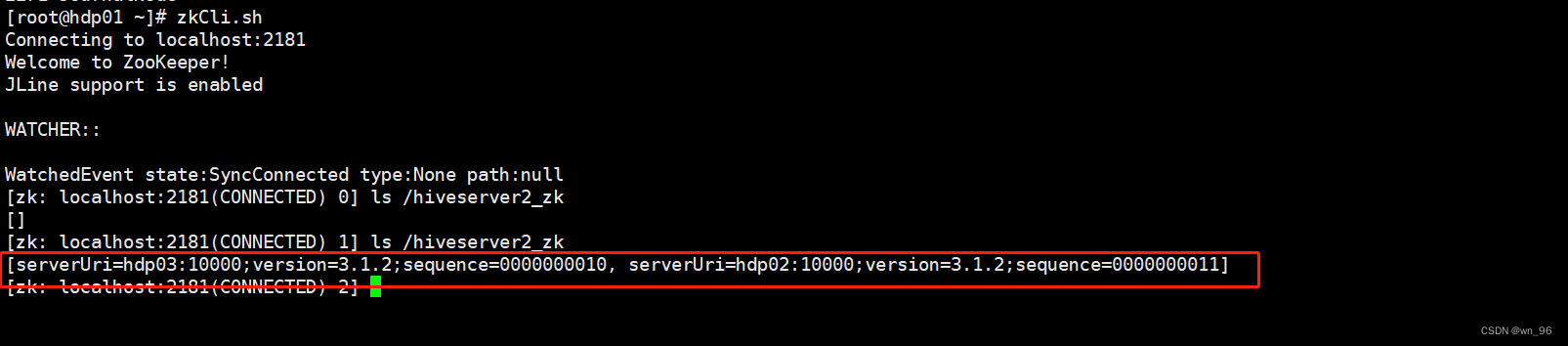
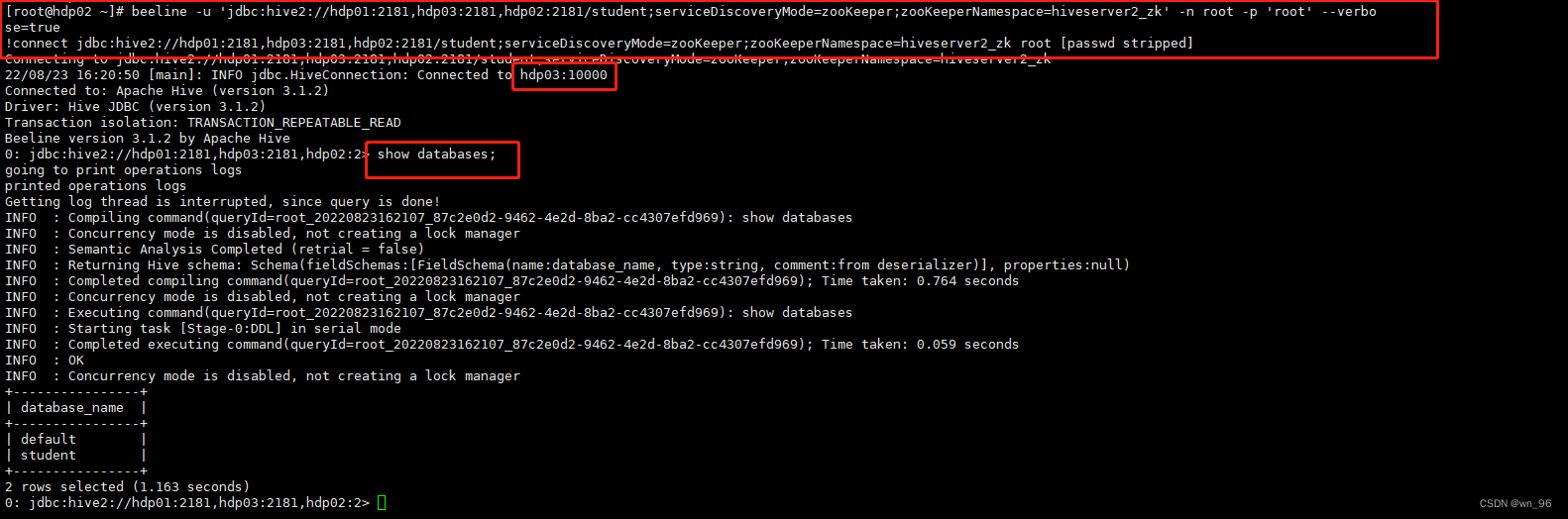
beeline通过ZK链接HIVE
beeline -u 'jdbc:hive2://hdp01:2181,hdp03:2181,hdp02:2181/student;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk' -n root -p 'root' --verbose=true
前端验证
192.169.2.102:10002
192.169.2.103:10002
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









