









文章目录
前言
学习记录:2023年11月15日
李宏毅的机器学习教程||百度Aistdio学习平台;
一、机器学习介绍
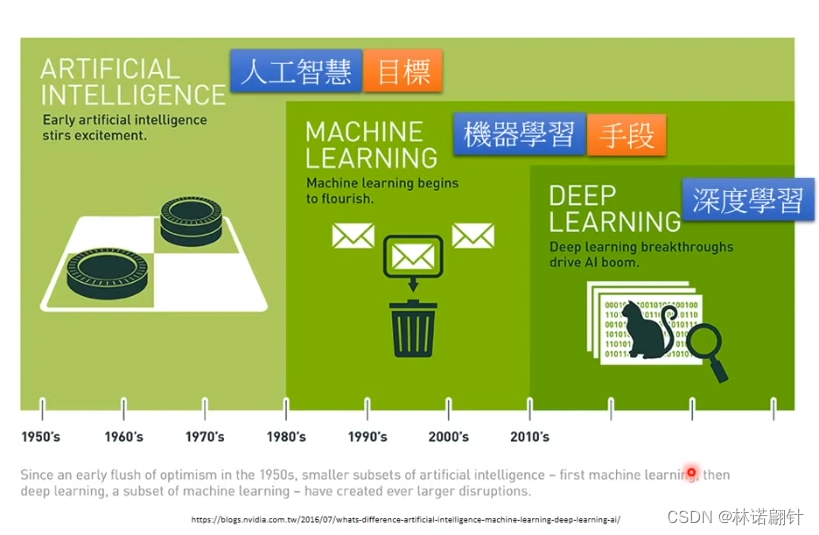
1、人工智能、机器学习和深度学习的关系
2、机器学习是什么?

3、机器学习的步骤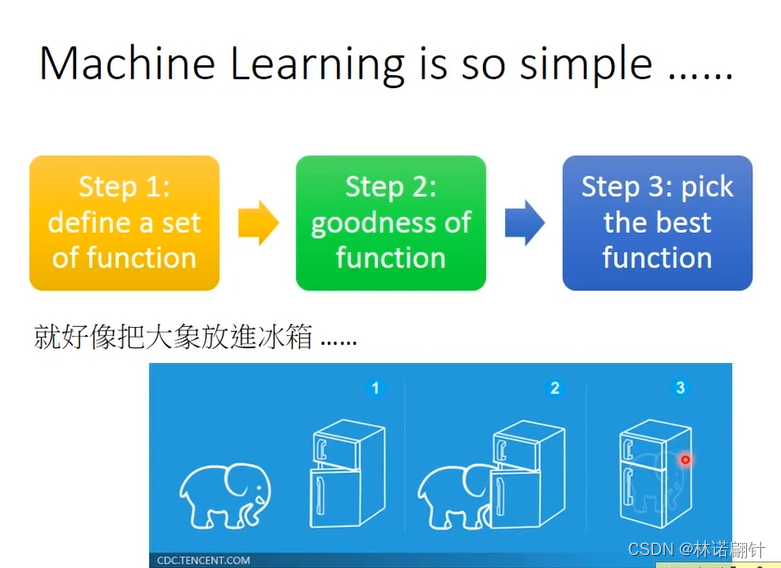
4、学习图谱(detail)
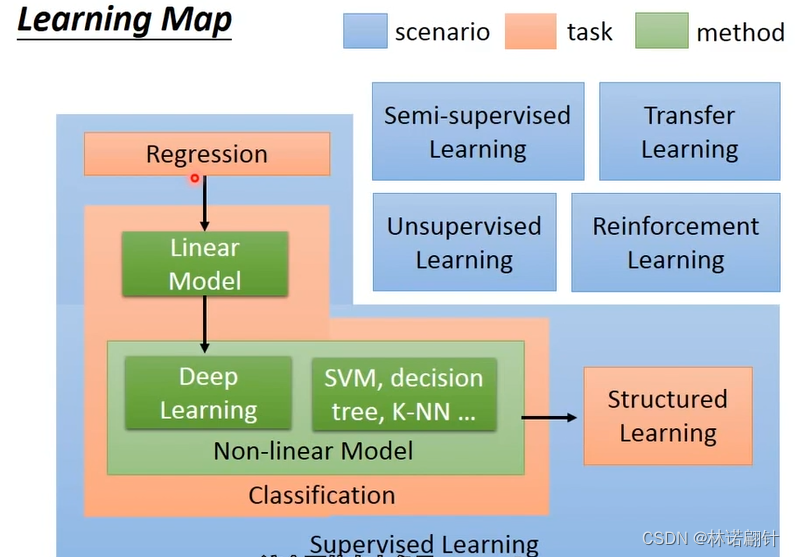
目前我们只讲到回归和分类的问题,但是事实上还有Structured Learning,这是一个很大的板块需要我们去探索,Gan作为一个代表;
二、回归(Regression)
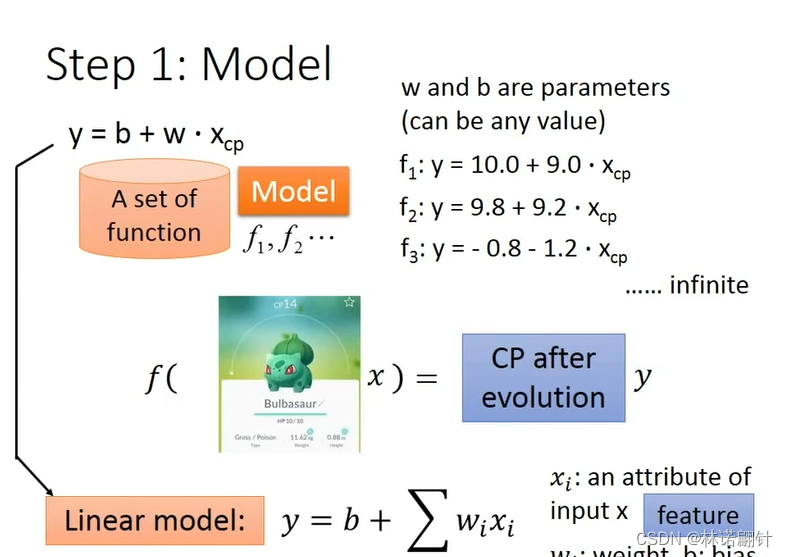

损失函数L:衡量一组参数的好坏,即衡量w,b的好坏
input:a function,output:how bad it is
L(f) = L(w,b)
example:
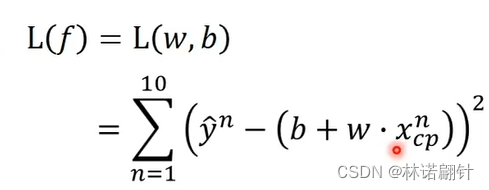
解释:计算10只宠物的误差的平方之和,这是估测误差
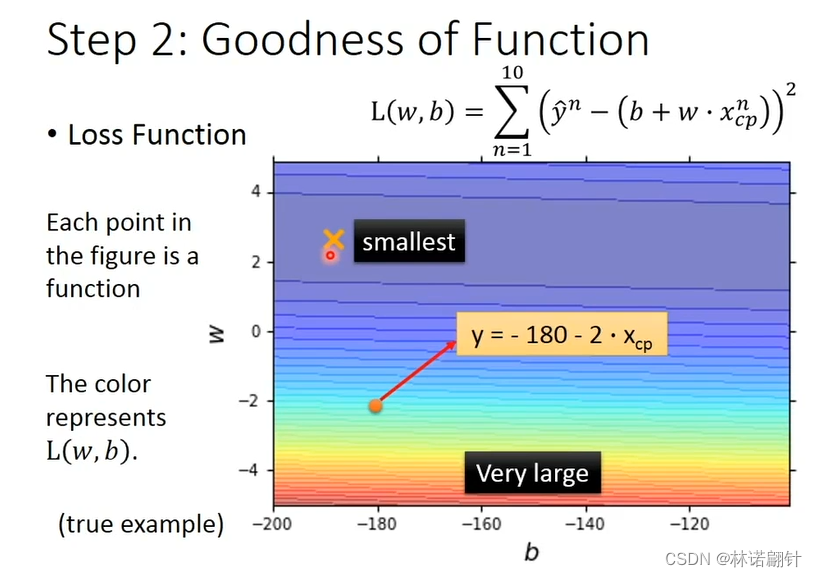

我们可以通过线性代数的方法来解决求解这个函数;但我们直接通过梯度下降(gradient descent)进行求解。
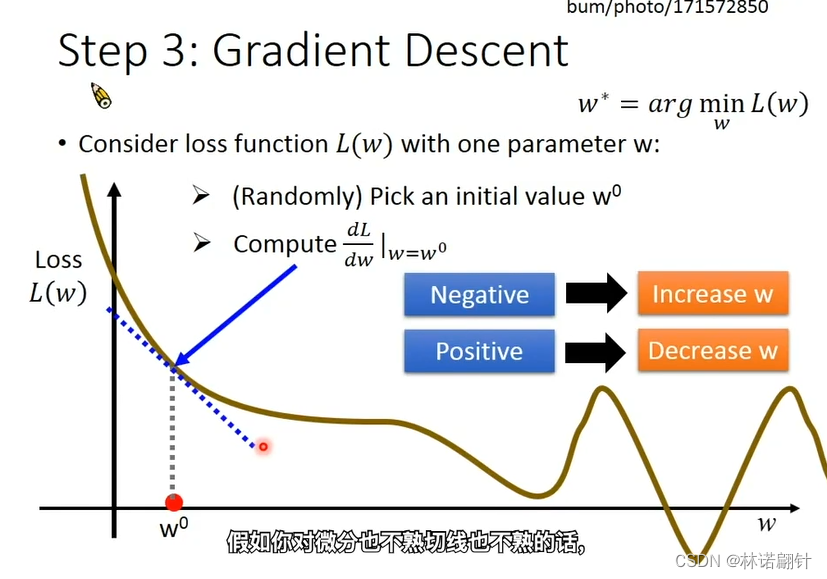
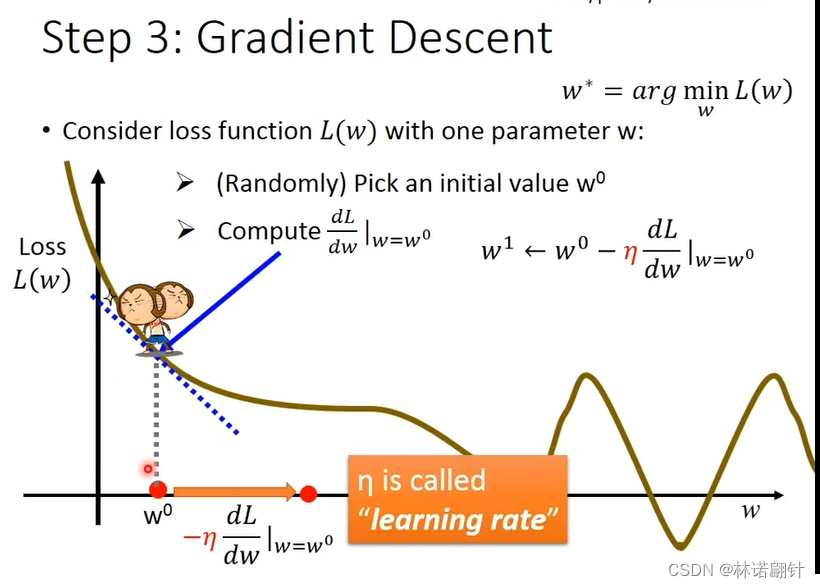
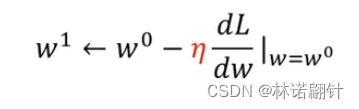
Tips:
- 如果微分值是负的,那么我们就要将w往右边移动,也就是往大方向移动;反之,往左方向移动(并且学习率的符号为负数,保证控制我们的w的步幅的方向)。
- 学习率,学习率越大,我们的步幅也就越大;反之,步幅越小。
- 所以在解决线性回归问题,我们要考虑损失函数,梯度下降,学习率这些问题,不仅是线性回归其他问题也是如此。
上面只是处理一个参数的问题,即w
接下来要处理w,b 两个参数的问题

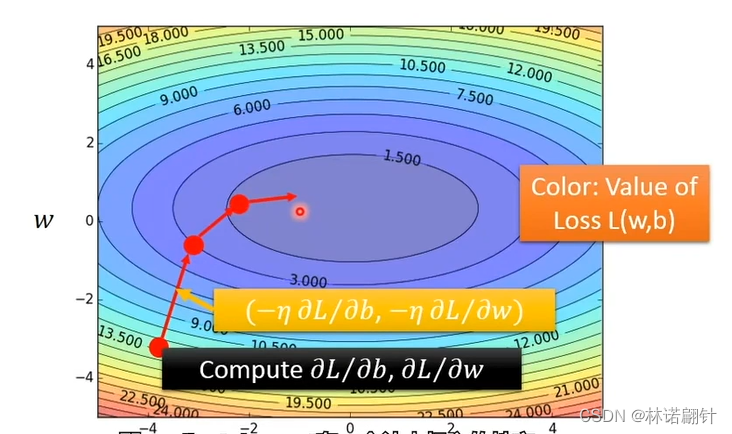
其实也就是法线的方向
过拟合和欠拟合
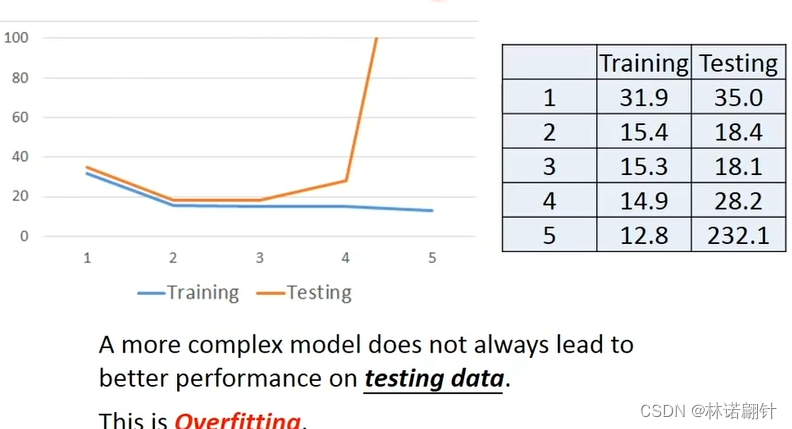
如果我们不带你选择更加复杂的模型,在训练集上取得好的效果,但是在测试集效果不行,这就叫做过拟合(Overfitting);反之,叫做欠拟合。
所以我们就要选择一个suitable的模型。

正则化

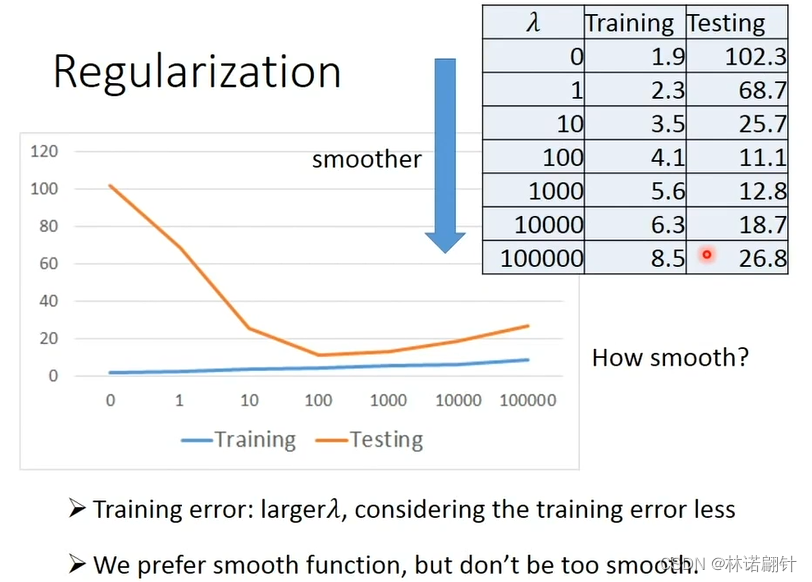
我们要调整λ来避免曲线过于平滑,过于平滑对于测试集的数据不友好;
误差从何而来呢?
误差来自于变量(variance)和 b(bias);
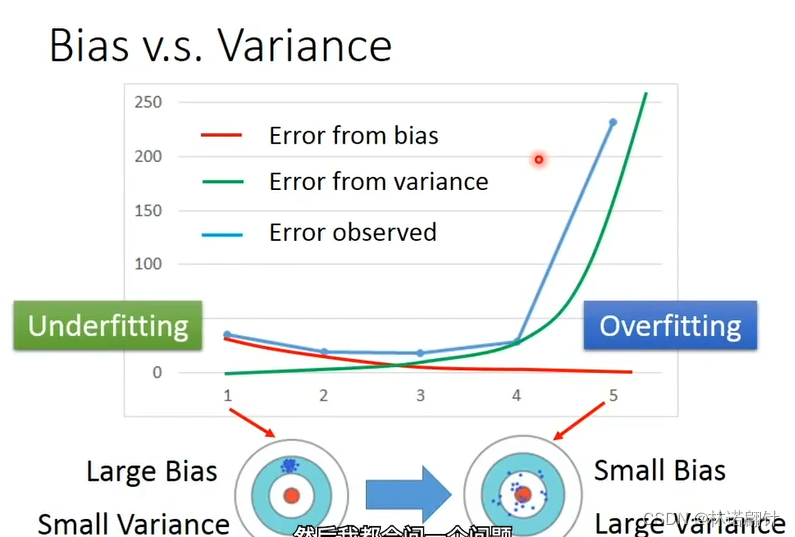
- 简单的模型:大的bias,小的variance,范围比较集中;
- 复杂的模型,小的bias,大的variance,范围比较松散;
大的bias会导致欠拟合;因为大的bias会有简单的模型,可能我训练的点都不会落在我模型的那条线上;大的variance会导致过拟合;因为大的variance,过渡模拟训练的数据集,大部分点落在线上;

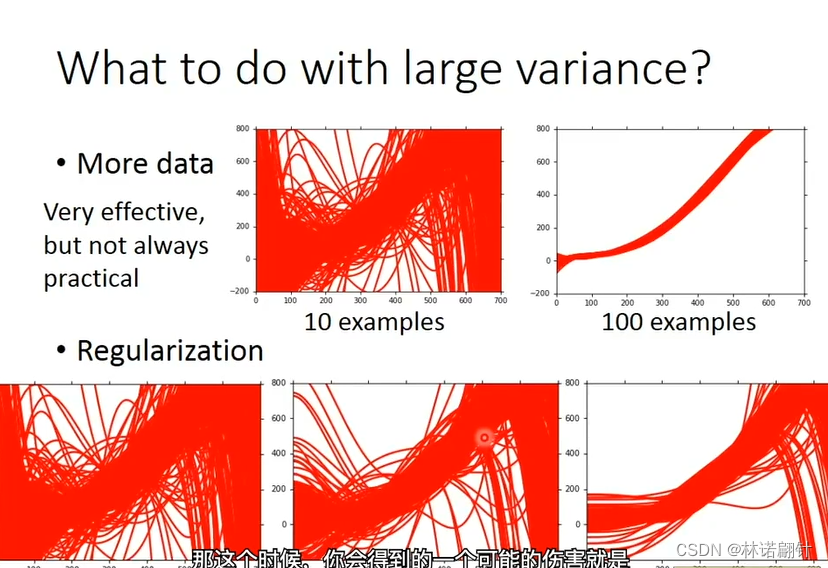
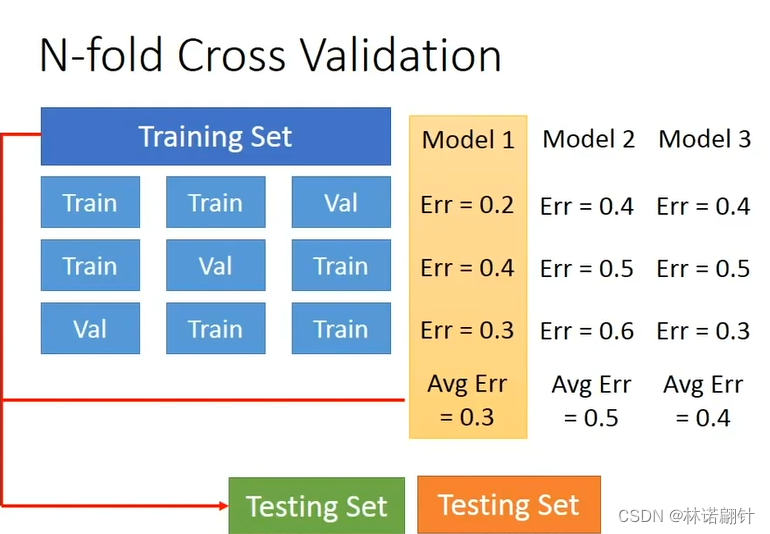
交叉验证
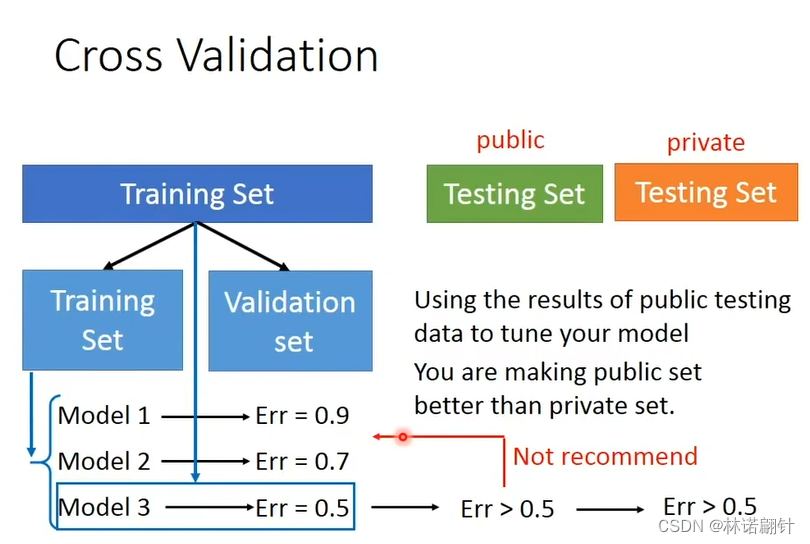
当我们训练到一个不理想的模型,在Testing Set检测之后,就不要往回去做训练了,因为这样已经把Testing Set的数据集考虑进去了。
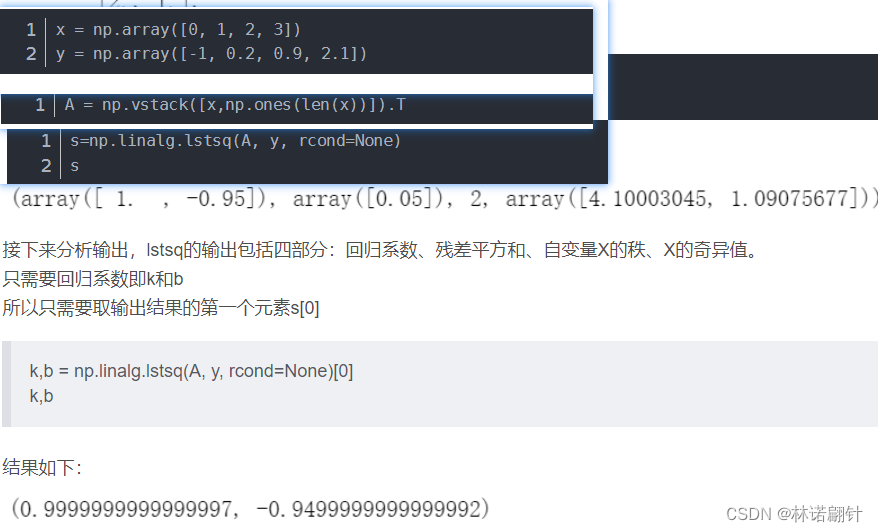
小tip:通过使用numpy下面包numpy.linalg.lstsq()求解k和b
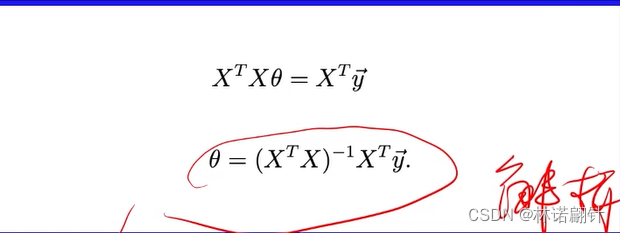

















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











