







import requests
response = requests.get("https://movie.douban.com/top250")
print(response)
写入上面的代码
我们看到
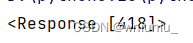
这个说明错误,说明这个网址对应的服务器不想服务于爬虫程序,我们需要伪装成浏览器去访问
改成下面的代码
import requests
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
response = requests.get("https://movie.douban.com/top250",headers = headers)
print(response)
















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











