







Logistic Regression
Logistic regression sometimes called the logistic model or logit model, analyzes the relationship between multiple independent variables and a categorical dependent variable and estimates the probability of occurence of an event by fitting data to a logistic curve. There are two models of an logistic regression, binary logistic regression and multinominal logistic regression. Binary logistic regression is typically used when the dependent variable is dischotomous and the independent variables are either continuous or categorial. When the dependent varible is not dichotomous and is comprised of more than two categories, a multinomial logistic regression can be employed.[1]
Definition
An explanation of logistic regression can begin with an explanation of the standard logistic function. The logistic function is useful because it can take an input with any value from negative to positive infinity, whereas the output always takes values between zero and one and hence is interpretable as a probability. The logistic function
σ(t)
is defined as follows:[2]
A graph of the logistic function on the t-interval (-6,6) is shown as below:
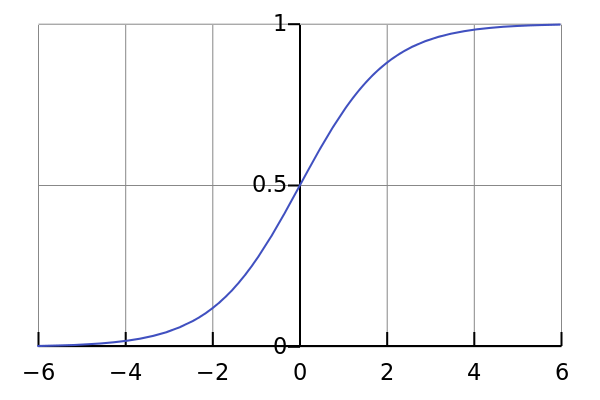 [from wikipedia]
[from wikipedia]
In linear regresion
When using logistic regresion, we want the output values between 0 and 1,so
so we can define the cost function of logistic regression:
we can simplify the objective function as:
then the objective function of logistic regression can be defined as below:
Equivalent to
since when y=1
when y=0
so
Since
so
then
then
then
#!/usr/bin/env python
# -*- coding: utf-8 -*-
################################
##Author: Vincent.Y
################################
import numpy as np
def sigmoid(X):
return 1.0/(1.0+np.exp(-X))
class LogisticRegression(object):
"""
solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’,'sgd'}
sgd support only
alpha:float
L1
lam: float
L2
max_iter:int
iteration of for the solvers to converge
"""
def __init__(self,solver="sgd",alpha=0,lam=1,lr=0.2,max_iter=200,bias=False):
self.solver=solver
self.coef_=None
self.bias=bias
self.lam=lam
self.alpha=alpha
if self.solver=='sgd':
self.lr=lr
self.max_iter=max_iter
def gradient_descent(self,X,y):
m=len(y)
for i in xrange(0,self.max_iter):
pred=sigmoid(X.dot(self.coef_))
for j in xrange(0,X.shape[1]):
tmp=X[:,j]
errors = np.mean((pred - y) * tmp) + 2*self.lam*(self.coef_[j] if j< X.shape[1] else 0) + self.alpha*(0 if self.coef_[j]==0 else 1)
self.coef_[j]=self.coef_[j] - self.lr * errors
return self.coef_
def fit(self,X,y):
if self.bias:
X = np.hstack([X,np.ones((X.shape[0],1))])
if self.solver=="ls":
G = self.lam * np.eye(X.shape[1])
G[-1, -1] = 0 # Don't regularize bias
self.coef_=np.dot(np.linalg.inv(np.dot(X.T, X) + np.dot(G.T, G)),np.dot(X.T, y))
else:
self.coef_=np.zeros(X.shape[1])
self.coef_=self.gradient_descent(X,y)
def predict_proba(self,X):
if self.bias:
X = np.hstack([X,np.ones((X.shape[0],1))])
return sigmoid(X.dot(self.coef_))
def predict(self,X):
if self.bias:
X = np.hstack([X,np.ones((X.shape[0],1))])
return np.array([ 1 if i>0.5 else 0 for i in sigmoid(X.dot(self.coef_))])
if __name__=="__main__":
x=np.array([1,2,3])
x=x.reshape(-1,1)
y=np.array([0,0,1])
model=LogisticRegression(bias=True,solver='sgd',max_iter=100,lam=0)
model.fit(x,y)
print model.coef_
print model.predict(x)[1]http://synapse.koreamed.org/Synapse/Data/PDFData/0006JKAN/jkan-43-154.pdf
[2]https://en.wikipedia.org/wiki/Logistic_regression
[3]https://github.com/muyinanhai/ml-learn















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









