







随机梯度下降算法
1.h为假设函数,J为代价函数
梯度下降算法是反复更新参数西塔的值

过程:
1.随机打乱所有数据,把m个训练样本重新随机排列,此为数据预处理过程。
2.用公式对西塔进行更新操作,并对样本进行逐一拟合。由于每次更新只需要对一个数据进行拟合,所以算法的速度很快。

左端为梯度下降算法,右端为随机梯度下降算法
区别:梯度下降算法每次更新都要用到所有的样本数据,速度较慢;而随机梯度下降算法每次更新只需要用到一个样本数据,梯度较快,不需要进行过多的并行计算
mini-batch梯度下降算法:采用随机梯度下降算法的思想,每次对b个数据进行更新


有点:结合梯度下降和随机梯度下降算法的特点,当有合适的向量化参数时,运算速度将比随机梯度下降算法还快
随机梯度下降算法收敛判断

1.原梯度下降算法缺点:如果要想得知该算法是否收敛,需要遍历整个训练集才行,否则就要暂停算法的运行。而梯度下降算法一般是运行一次就可通过查看cost函数来判断算法是否收敛,也可运用mini-batch函数对前一千个样本数据运用cost函数进行局部梯度下降来判断算法是否收敛。
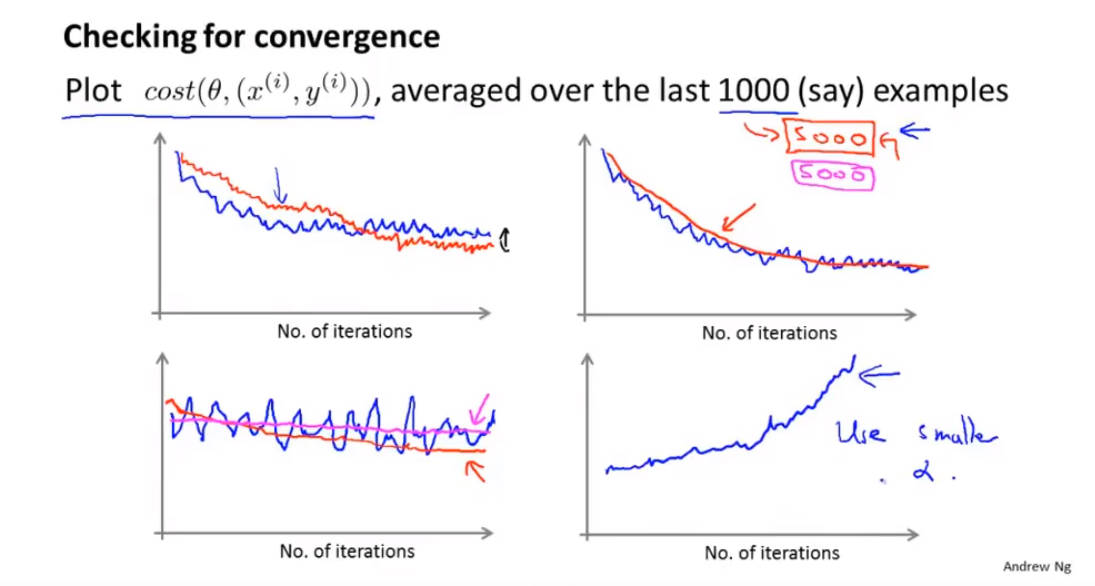
1.5000取样的曲线要比1000取样的曲线要平滑
2.如果曲线上下跳动得很明显甚至看不出下降趋势的话,可能的原因为样本数据量过小,应该适当增加样本的数据量。
3.如果代价函数曲线是往上走的,可能的原因就是a值太大,即学习梯度过大,应当使用小点的a值

代价函数一般在收敛后会在某个值附近震荡,解决办法就是让a的值如上图所示,随着迭代次数的增加,a的值会不断减小,震荡幅度就越不明显。
在线学习机制:随机梯度下降的一个变种

由于是在线算法,会有源源不断的数据量,因此每个数据一般只使用一次

MapReduce
算法机制

将工作量分给多台电脑工作后再进行汇总到一台电脑上合并运算
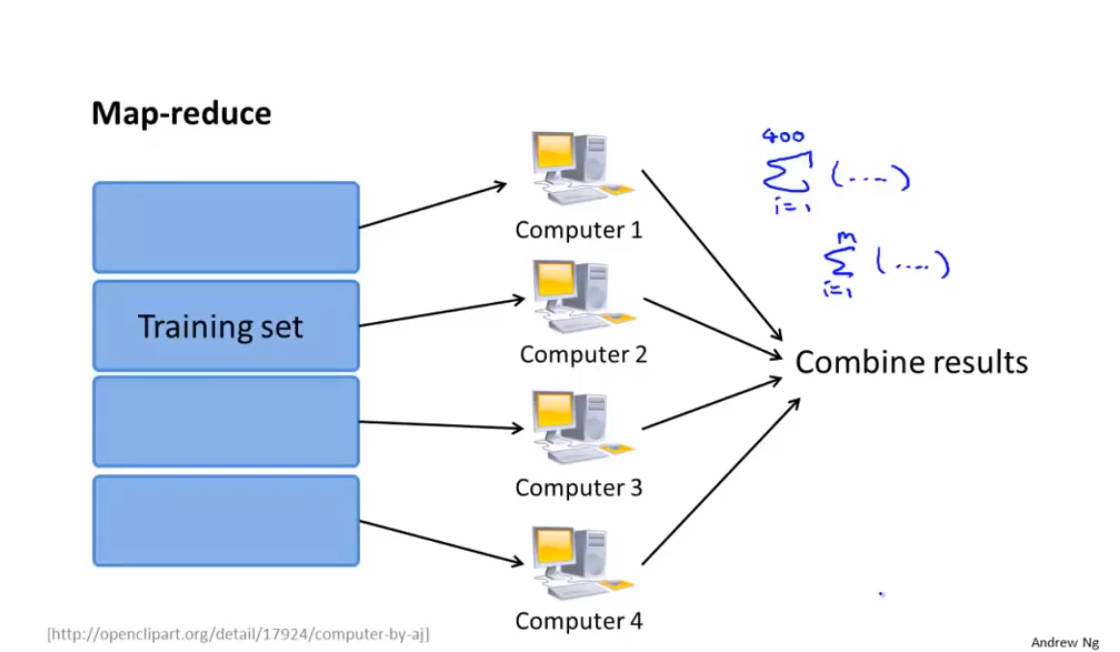
前提就是算法能能在大量数据的基础上表示成对训练集的求和

如果一台电脑拥有多个核心,也可以运行mapreduce算法,这样就不用过多考虑数据传输等问题















 8076
8076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









