






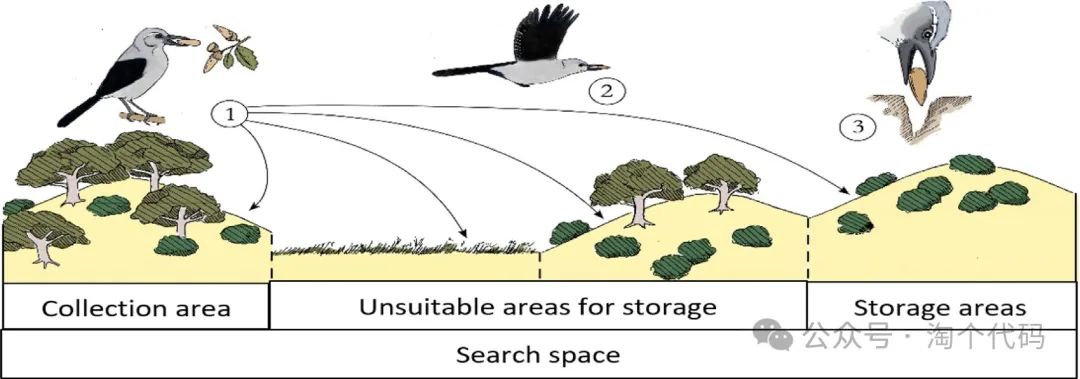
星雀优化算法(Nutcracker Optimization Algorithm,NOA)是一种受自然启发的群智能优化算法,星雀在不同的时期表现出两种不同的行为。第一种行为发生在夏季和秋季,代表星雀寻找种子并随后存储在适当的缓存中。在冬季和春季,另一种基于空间记忆策略的行为被认为是以各种物体或标记为参考点,搜索以不同角度标记的隐藏缓存。
该成果于2023年发表在计算机一区SCI期刊Knowledge-Based Systems上。

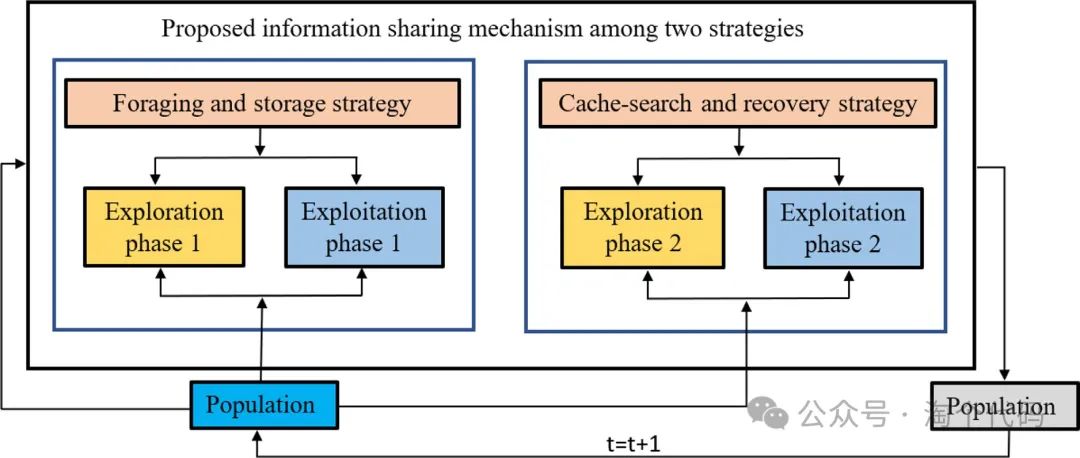
在提出的NOA算法中,基于上述两个主要行为来模拟星雀的行为。两种主要策略是(i)觅食和储存策略;(ii)缓存搜索和恢复策略。下图示出了所提出的NOA的框架。NOA有一个非常简单的结构,由两个主要策略组成,代表在两个不同时期发生的两种不同行为。第一种策略代表了星雀寻找饲料然后将其存储在适当缓存中的行为。相比之下,第二种策略代表了星雀搜索和检索存储位置的行为。
1、算法原理
(1)觅食阶段(探索阶段1)
在这个阶段,每一个星雀开始检查锥体的初始位置,其中包含的种子。如果星雀找到好的种子,它就会把它们带到储藏区,埋在一个贮藏处。如果星雀找不到好的种子,它就会在松树或其他树木的另一个位置寻找另一个圆果。这种行为可以使用位置更新策略进行数学建模,如下所示:
其中Xt+1 i是当前世代t中第i个星雀的新位置; Xt i,j是当前世代中第i个星雀的第j个位置; Uj和Lj是向量,包括优化问题中第j维的上界和下界; γ是根据Levy飞行生成的随机数; Xt best,j是现在获得的最佳解的第j维; A、C和B是从种群中随机选择的三个不同的指数,以便于探索高质量的食物来源; τ1、τ2、r和r1是[0,1]范围内的随机真实的数; Xt m,j是迭代t中当前种群所有解的第j维的平均值; μ是基于正态分布(τ4)、levy-飞行(τ5)和在0和1(τ3)之间随机生成的数字,如以下等式所示:
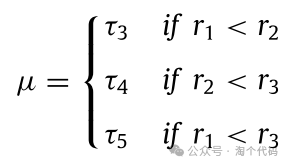
其中r2和r3是[0,1]范围内的随机真实的数。
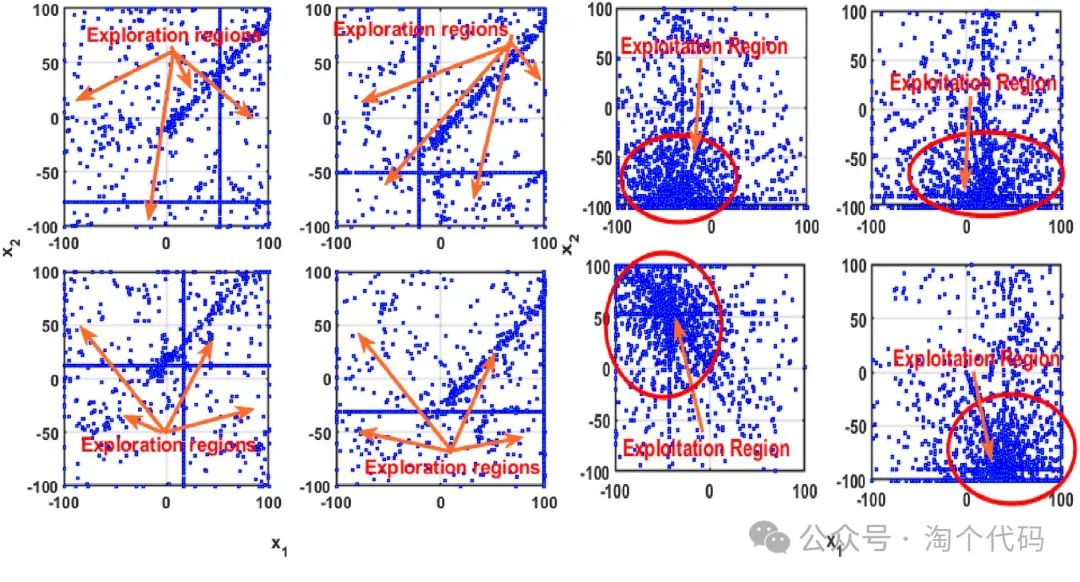
在下图中描绘了该探索阶段的四个独立运行,以显示它能够探索搜索空间内的区域多远。从该图中可以清楚地看出,在整个优化过程中,搜索空间的大部分被在觅食阶段下生成的解覆盖,以确认该阶段与稍后进行的实际实验中所认可的一样有效。
 (2)储存阶段:(开发阶段1)
(2)储存阶段:(开发阶段1)
星雀开始是将在前一阶段,即探索阶段1中获得的食物运输到临时存储位置。这个阶段被称为“开发阶段1”,在这个阶段,星雀会利用松树种子作物并储存它们。这种行为可以用数学表示如下:
其中,X t+1(new)i是当前迭代t中星雀的存储区域中的新位置,λ是根据Lévy flight生成的数,τ3是0和1之间的随机数。l是从1到0线性减小以使NOA的开采行为多样化的因子。
根据以下公式应用搜寻阶段和该高速缓存之间的交换,以通过优化过程来维持探索和利用操作符之间的平衡:
其中φ是0到1之间的随机数,Pa1表示基于当前一代从1到0线性递减的概率值。在第一种提出的策略中,探索和开发过程的流程图下图所示,并在算法1中列出。

(3)缓存搜索阶段:(探索阶段2)
当冬天来临时,树木光秃秃的,是时候从隐藏模式切换到探索和搜索模式了。星雀开始寻找它们的贮藏物。我们称这个阶段为第二次探索。星雀使用空间记忆策略来定位它们的贮藏物。将这些对象定义为参考点(rp)。在NOA中,种群的每个缓存/星雀的两个rp可以使用以下矩阵定义:
其中,→RPt i,1和→RPt i,2表示当前第t代第i个星雀的缓存位置X∈ti的rp(对象)。
星雀可以恢复隐藏的缓存具有很高的准确性。第一个RP是通过更新相邻区域内的当前位置来找到星雀周围隐藏的缓存来生成的。生成第一个RP的数学公式为:
第二个RP是通过在问题的搜索空间内更新当前解来生成的,第二个RP按下式计算:
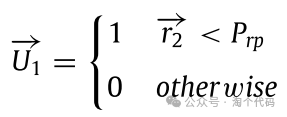
式中,k为RP指标;→RPt i,k为当前迭代t中第i个星雀的缓存位置,U和L分别是d维问题的上界和下界;α从1线性减小到0;τ3是第二个RP在[0,1]范围内的随机数;θ是在[0,π]范围内的随机值;Prp是用于确定在搜索空间内全局探索其他区域的百分比的概率。
(4)恢复阶段:(开发阶段2)
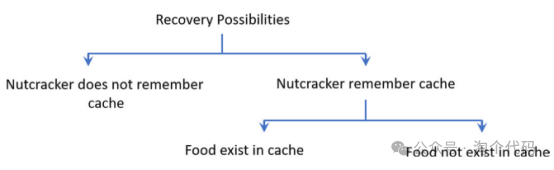
下图描绘了星雀在寻找它的缓存时可能遇到的可能性。第一个主要的可能性是,星雀可以使用第一个RP记住他的缓存的位置。图所示的两种可能性是:第一种是该食物存在,第二种是该食物不存在。这种行为可以根据下面的方程进行数学建模
其中,Xt+ 1i为第i个星雀在迭代(t+1)时的新位置,Xt ij为当前迭代t中第i个星雀的当前维度,Xt best为迭代t中最佳位置,→RPt i,1为当前迭代t中第i个星雀当前位置/缓存的第一个RP;r1, r2, τ3和τ4是0到1之间的随机数,C是从总体中随机选择的解的索引。
第二种策略的探索和开发过程伪代码算法如下列出。

(5)所提出方法的实现
NOA是基于两个主要策略设计的。第一种是觅食和存储策略,第二种是缓存搜索和恢复策略。每种策略都模拟了一段时间内星雀的行为。这两种策略对NOA同样重要,被选择的概率相同。与其他基于种群的优化算法类似,NOA中的种群初始化为
式中,t为生成索引;I为人口指数;U - j和Lj分别是一个d维问题的上下界;→RM为区间[0,1]内的随机向量。每个星雀都代表了解决问题的可行方案。
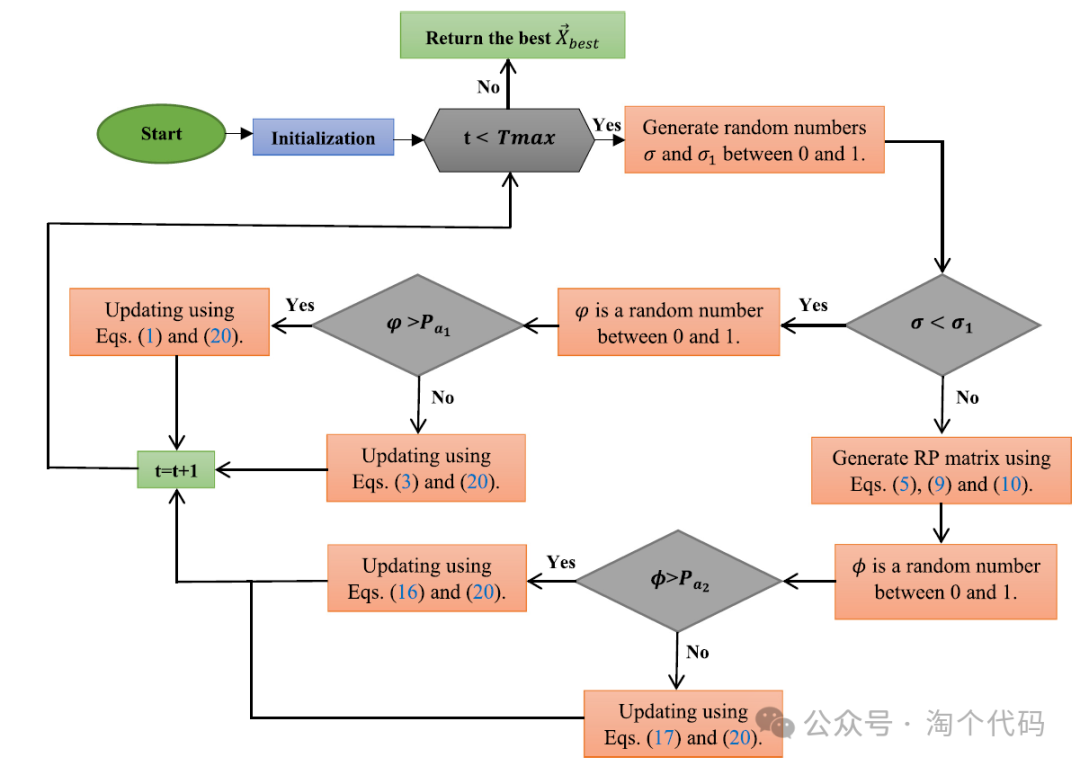
最后,NOA伪代码和流程图分别如下图所示。
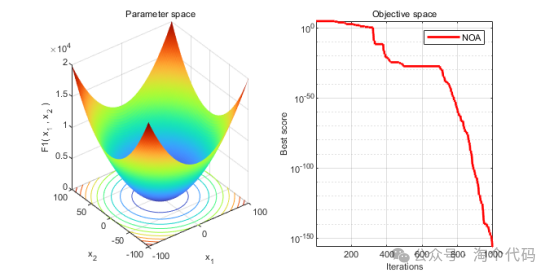
3、结果展示
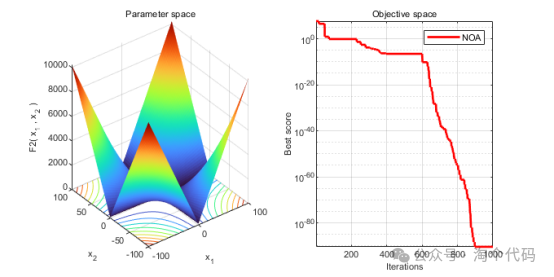
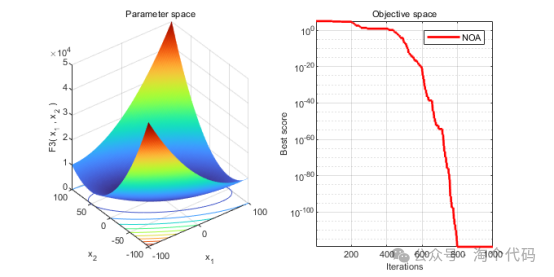
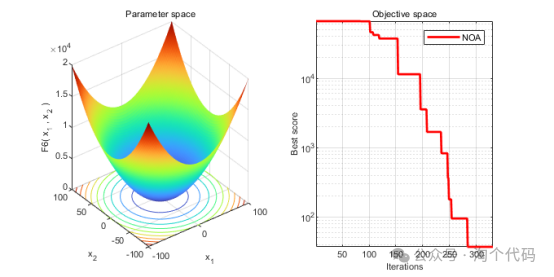
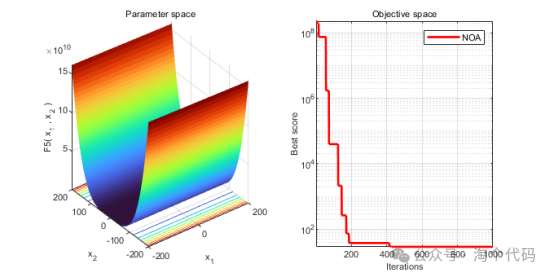
4、MATLAB核心代码
function [Best_score,Best_NC,Convergence_curve]=NOA(SearchAgents_no,Max_iter,ub,lb,dim,fobj)
lb=ones(1,dim).*(lb); % Lower limit for variables
ub=ones(1,dim).*(ub); % Upper limit for variables
%% 初始参数定义
Best_NC=zeros(1,dim); % A vector to include the best-so-far Nutcracker(Solution) 最佳星鸦
Best_score=inf; % A Scalar variable to include the best-so-far score 最佳适应度
LFit=inf*(ones(SearchAgents_no,1)); % A vector to include the local-best position for each Nutcracker 种群 适应度
RP=zeros(2,dim); %% 2-D matrix to include two reference points of each Nutcracker 参考点
Convergence_curve=zeros(1,Max_iter);
%% 控制参数
Alpha=0.05; %% The percent of attempts at avoiding local optima
Pa2=0.2; %% The probability of exchanging between the cache-search stage and the recovery stage
Prb=0.2; % The percentage of exploration other regions within the search space.
%% 种群初始化
Positions=initialization(SearchAgents_no,dim,ub,lb); %Initialize the positions of search agents
Lbest=Positions; %% Set the local best for each Nutcracker as its current position at the beginning.
t=0; %% Function evaluation counter
for i=1:SearchAgents_no
NC_Fit(i)=fobj(Positions(i,:));
LFit(i)=NC_Fit(i); %% Set the local best score for the ith Nutcracker as its current score.
% Update the best-so-far solution
if NC_Fit(i)<Best_score % Change this to > for maximization problem
Best_score=NC_Fit(i); % Update the best-so-far score
Best_NC=Positions(i,:); % Update te best-so-far solution
end
end
%% 迭代
while t<Max_iter
RL=0.05*levy(SearchAgents_no,dim,1.5); %Levy random number vector 对应公众号文章中的勘探1中的y
l=rand*(1-t/Max_iter); % Parameter in Eq. (3) 对应公众号文章中的开发1中的随机线性递减因子I
% 对应公众号文章中的寻找储藏区与找回策略中的a
if rand<rand
a=(t/Max_iter)^(2*1/t);
else
a=(1-(t/Max_iter))^(2*(t/Max_iter));
end
if rand<rand % 随机选择进行第一个阶段或者是第二个阶段 每次迭代仅运行一个阶段的搜索
% 小于就是第一个阶段——对应觅食与存储策略
mo= mean(Positions);
for i=1:SearchAgents_no
% 对应公众号文章中的勘探1中的u
if rand<rand
mu=rand;
elseif rand<rand
mu=(randn);
else
mu=(RL(1,1));
end
cv=randi(SearchAgents_no);%% An index selected randomly between 1 and SearchAgents_no
cv1=randi(SearchAgents_no); %% An index selected randomly between 1 and SearchAgents_no
Pa1=((Max_iter-t)/Max_iter);
if rand<Pa1
% 觅食阶段——勘探1
cv2=randi(SearchAgents_no);
r2=rand;
for j=1:size(Positions,2)
if t<Max_iter/2
if rand>rand
Positions(i,j)=(mo(j))+RL(i,j)*(Positions(cv,j)-Positions(cv1,j))+mu*(rand<5)*(r2*r2*ub(j)-lb(j)); % Eq. (1)
end
else
if rand>rand
Positions(i,j)=Positions(cv2,j)+mu*(Positions(cv,j)-Positions(cv1,j))+mu*(rand<Alpha)*(r2*r2*ub(j)-lb(j)); % Eq. (1)
end
end
end
else
% 存储阶段——开发1
mu=rand;
if rand<rand
r1=rand;
for j=1:size(Positions,2)
Positions(i,j)=((Positions(i,j)))+mu*abs(RL(i,j))*(Best_NC(j)-Positions(i,j))+(r1)*(Positions(cv,j)-Positions(cv1,j)); % Eq. (3)
end
elseif rand<rand
for j=1:size(Positions,2)
if rand>rand
Positions(i,j)=Best_NC(j)+mu*(Positions(cv,j)-Positions(cv1,j)); % Eq. (3)
end
end
else
for j=1:size(Positions,2)
Positions(i,j)=(Best_NC(j)*abs(l)); % Eq. (3)
end
end
end
% 范围规约
if rand<rand
for j=1:size(Positions,2)
if Positions(i,j)>ub(j)
Positions(i,j)=lb(j)+rand*(ub(j)-lb(j));
elseif Positions(i,j)<lb(j)
Positions(i,j)=lb(j)+rand*(ub(j)-lb(j));
end
end
else
Positions(i,:) = min(max(Positions(i,:),lb),ub);
end
NC_Fit(i)=fobj(Positions(i,:));
% 贪婪策略更新
if NC_Fit(i)<LFit(i) % Change this to > for maximization problem
LFit(i)=NC_Fit(i); % Update the local best fitness
Lbest(i,:)=Positions(i,:); % Update the local best position
else
NC_Fit(i)=LFit(i);
Positions(i,:)=Lbest(i,:);
end
% Update the best-so-far solution
if NC_Fit(i)<Best_score % Change this to > for maximization problem
Best_score=NC_Fit(i); % Update best-so-far fitness
Best_NC=Positions(i,:); % Update best-so-far position
end
t=t+1;
if t>Max_iter
break;
end
Convergence_curve(t)=Best_score;
end
else
% 寻找储藏区与找回食物策略
% 首先计算参考点
for i=1:SearchAgents_no
ang=pi*rand;
cv=randi(SearchAgents_no);
cv1=randi(SearchAgents_no);
for j=1:size(Positions,2)
for j1=1:2
if j1==1
%% Compute the first reference point for the ith Nutcraker using Eq. (9)
if ang~=pi/2
RP(j1,j)=Positions(i,j)+ (a*cos(ang)*(Positions(cv,j)-Positions(cv1,j)));
else
RP(j1,j)=Positions(i,j)+ a*cos(ang)*(Positions(cv,j)-Positions(cv1,j))+a*RP(randi(2),j);
end
else
%% Compute the second reference point for the ith Nutcraker using Eq. (10)
if ang~=pi/2
RP(j1,j)=Positions(i,j)+ (a*cos(ang)*((ub(j)-lb(j))+lb(j)))*(rand<Prb);
else
RP(j1,j)=Positions(i,j)+ (a*cos(ang)*((ub(j)-lb(j))*rand+lb(j))+a*RP(randi(2),j))*(rand<Prb);
end
end
end
end
% 参考点的范围规约
if rand<rand
for j=1:size(Positions,2)
if RP(2,j)>ub(j)
RP(2,j)=lb(j)+rand*(ub(j)-lb(j));
elseif RP(2,j)<lb(j)
RP(2,j)=lb(j)+rand*(ub(j)-lb(j));
end
end
else
RP(2,:) = min(max(RP(2,:),lb),ub);
end
if rand<rand
for j=1:size(Positions,2)
if RP(1,j)>ub(j)
RP(1,j)=lb(j)+rand*(ub(j)-lb(j));
elseif RP(1,j)<lb(j)
RP(1,j)=lb(j)+rand*(ub(j)-lb(j));
end
end
else
RP(1,:) = min(max(RP(1,:),lb),ub);
end
% 寻找储藏区阶段——勘探2
if (rand<Pa2) %% Exploitation stage 2: Recovery stage
cv=randi(SearchAgents_no);
if rand<rand
for j=1:size(Positions,2)
if rand>rand
Positions(i,j)=Positions(i,j)+rand*(Best_NC(j)-Positions(i,j))+rand*(RP(1,j)-Positions(cv,j)); %% Eq. (13)
end
end
else
for j=1:size(Positions,2)
if rand>rand
Positions(i,j)=Positions(i,j)+rand*(Best_NC(j)-Positions(i,j))+rand*(RP(2,j)-Positions(cv,j)); %% Eq. (15)
end
end
end
% 范围规约
if rand<rand
for j=1:size(Positions,2)
if Positions(i,j)>ub(j)
Positions(i,j)=lb(j)+rand*(ub(j)-lb(j));
elseif Positions(i,j)<lb(j)
Positions(i,j)=lb(j)+rand*(ub(j)-lb(j));
end
end
else
Positions(i,:) = min(max(Positions(i,:),lb),ub);
end
% Calculate objective function for each search agent
NC_Fit(i)=fobj(Positions(i,:));
% Update the local best
if NC_Fit(i)<LFit(i) % Change this to > for maximization problem
LFit(i)=NC_Fit(i);
Lbest(i,:)=Positions(i,:);
else
NC_Fit(i)=LFit(i);
Positions(i,:)=Lbest(i,:);
end
% Update the best-so-far solution
if NC_Fit(i)<Best_score % Change this to > for maximization problem
Best_score=NC_Fit(i); % Update best-so-far fitness
Best_NC=Positions(i,:); % Update best-so-far position
end
t=t+1;
Convergence_curve(t)=Best_score;
if t>Max_iter
break;
end
else
% 找回食物——开发2
NC_Fit1=fobj(RP(1,:));
%%-------Evaluations-----------
NC_Fit2=fobj(RP(2,:));
%%%%%----------- Applying Eq. (17) to trade-off between the exploration behaviors---------%%%%
if NC_Fit2<NC_Fit1 && NC_Fit2<NC_Fit(i)
Positions(i,:)=RP(2,:);
NC_Fit(i)=NC_Fit2;
elseif NC_Fit1<NC_Fit2 && NC_Fit1<NC_Fit(i)
Positions(i,:)=RP(1,:);
NC_Fit(i)=NC_Fit1;
end
% Update the local best
if NC_Fit(i)<LFit(i) % Change this to > for maximization problem
LFit(i)=NC_Fit(i);
Lbest(i,:)=Positions(i,:);
else
NC_Fit(i)=LFit(i);
Positions(i,:)=Lbest(i,:);
end
t=t+1;
% Update the best-so-far solution
if NC_Fit(i)<Best_score % Change this to > for maximization problem
Best_score=NC_Fit(i);
Best_NC=Positions(i,:);
end
Convergence_curve(t)=Best_score;
if t>Max_iter
break;
end
end
end
end
end
end参考文献
[1]Abdel-Basset M, Mohamed R, Jameel M, et al. Nutcracker optimizer: A novel nature-inspired metaheuristic algorithm for global optimization and engineering design problems[J]. Knowledge-Based Systems, 2023, 262: 110248.
完整代码获取
后台回复关键词:
TGDM900

点个"赞"再走吧~















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











