






学前教育优化算法(Preschool Education Optimization Algorithm,PEOA)是一种受学前教育过程中孩童的活动行为启发而提出的元启发式优化算法。学前教育在儿童的早期发展中起着至关重要的作用,并为他们未来的学习旅程奠定基础。作为幼儿学习者发展背后的指导力量,幼儿教师使儿童能够踏上自己的求知欲,自我发现和个人成就的终身旅程。学前教育中这些智能交互的数学建模是PEOA设计的基本灵感。PEOA的数学模型可分为三个阶段:(1)幼儿教师教育影响力的逐步增长;(2)教师引导下的个体知识发展;(3)个体知识和自我意识的增长。

该成果于2023年发表在Nature子刊“Scientific Reports”上。PEOA方法目前被引3次。

1、算法原理
(1)初始化
提出的PEOA方法是一种基于种群的技术,可以根据其成员的搜索能力为基于重复的过程中的优化问题提供合适的解决方案。PEOA种群由社区的成员组成,因此这些成员在搜索空间中的位置为问题的决策变量提供了值。每个群体成员都是问题的候选解,从数学的角度来看,可以用向量表示。由这些向量组成的PEOA种群可以根据下式使用矩阵表示。
式中X(t)为PEOA种群矩阵,→X i(t)为第i个PEOA成员,xi,j(t)为第j个变量的值,由第i个PEOA成员决定,N为PEOA种群成员的数量,m为问题变量的数量,t∈{1,2,…, T}是迭代计数器(即实际人口的数量),T是迭代的总次数。算法开始时,使用下式随机生成PEOA种群在搜索空间中的初始位置。
其中r是区间[0,1]内均匀分布的随机数,LBJ和ubj分别是第j个问题变量的下界和上界。
由于每个PEOA成员都是问题变量的候选解,因此可以根据每个PEOA成员的建议值计算问题的目标函数。因此,问题的目标函数的计算值可以根据下式用向量表示。
式中→F (t)为目标函数向量,Fi(t)为基于第i个PEOA成员的目标函数值。
通过对目标函数计算值的比较,将目标函数中提供最优值的成员称为最优总体成员→X best(t)。考虑到在PEOA的每次迭代中,种群成员在搜索空间中的位置都会更新,因此计算目标函数的新值。基于目标函数评估的新值,在每次迭代中也应该更新最佳成员。
搜索空间中PEOA人口的更新过程分为三个阶段:(i)幼儿教师教育影响力的逐步增长阶段,(ii)教师引导下的个体知识发展阶段,(iii)个体知识和自我意识的增长阶段。
(2)幼儿教师教育影响力的逐渐增长(开发阶段)
很明显,教师的角色随着孩子的年龄而显著变化,因此取决于学校的教育水平。在教育过程的开始,在幼儿园,也就是在孩子0 - 2岁的时候,教师的主要作用是养育,教育作用是微不足道的。在2 - 5岁的幼儿阶段,即幼儿园阶段,教育角色逐渐超过照顾角色,在幼儿园阶段,即5 - 6岁的幼儿阶段,幼儿教师的教学影响水平与随后的小学教育阶段几乎处于同一水平。
在PEOA的设计中,最好的成员是幼儿教师。因为在学前教育中,教师的影响力随着时间的推移而增加。为了模拟这一阶段的PEOA,首先,根据教师的影响,使用下式计算每个PEOA成员的新位置。然后,如果目标函数的值在新位置上得到改善,则根据下式,这个新位置取代相应成员的先前位置。
式中 为基于PEOA第一阶段的第i个PEOA成员的新计算位置, 为其第j维,K(t):= Xbest(t)为幼师(即幼儿园教师),t为迭代计数器,T为迭代总数。
(3)第二阶段:教师指导下的个人知识发展(探索阶段)
在PEOA的这一阶段,人口成员根据建模儿童的活动进行更新,因为儿童试图模仿工作并接受教师的经验,以比他们的同学更成功。为了模拟PEOA的这一阶段,首先使用下式在跟随幼儿园教师的基础上计算群体中每个成员的新位置。这一过程导致群体成员位置的大幅度变化,这对问题空间的不同区域的探索和全局搜索有积极的影响。根据下式,如果对群体中每个成员计算的新位置提高了目标函数的值,则可以接受。
式中, 为根据PEOA第二阶段计算出的第i个PEOA成员的新位置, 为其第j维,→rand为区间[0,1]内均匀分布得出的m维的随机向量,→rand2是由集合{1,2}中的均匀分布生成的m维的随机向量。
(4)第三阶段:个人知识和自我意识的增长(开发阶段)
除了幼儿园老师的影响外,每个孩子都试图通过不同的方式来提高自我意识,例如玩游戏,分析可能性,期望等。
在PEOA的第三阶段,人口成员更新的基础上建模儿童的努力,提高自我意识。为了模拟PEOA的这一阶段,首先,使用下式在群体的每个成员附近随机生成新的位置。这个过程会导致种群成员位置的微小变化,这在增加PEOA局部搜索和利用能力方面发挥了重要作用,可以在发现的解决方案周围找到更好的解决方案。根据下式,如果它改善了目标函数的值,则为群体的每个成员所建议的计算位置是可接受的。
式中, 为根据PEOA第三阶段计算出的第i个PEOA成员的新位置, 为其第j维,→rand为区间[0,1]内均匀分布得出的m维的随机向量。
在基于第一到第三阶段更新了所有PEOA成员之后,完成了PEOA的第一次迭代。在完成每次迭代之后,问题的最佳候选解决方案将被更新。然后,根据计算出的种群成员位置的新值及其对应的目标函数,算法进入下一次迭代。在算法迭代过程中找到的最佳候选解作为问题的解。算法1给出了PEOA实现过程中不同步骤的伪代码。
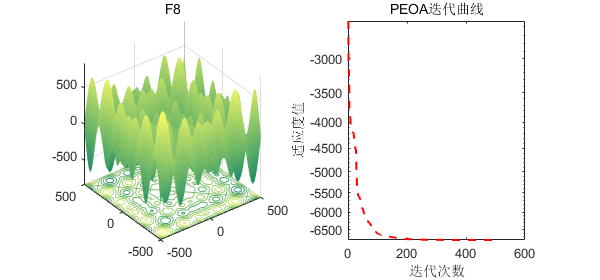
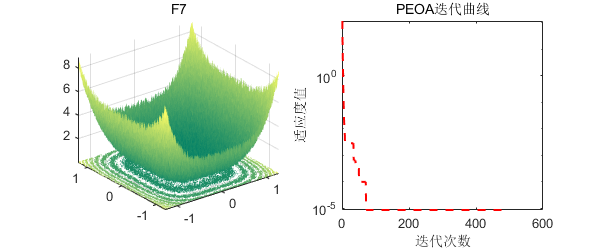
2、结果展示
3、MATLAB核心代码
%% 淘个代码 %%
% 微信公众号搜索:淘个代码,获取更多代码
% 学前教育优化算法(Preschool Education Optimization Algorithm,PEOA)
function[Best_score,Best_pos,PEOA_curve]=PEOA(SearchAgents,T,lowerbound,upperbound,dimension,fitness)
lowerbound=ones(1,dimension).*(lowerbound); % Lower limit for variables
upperbound=ones(1,dimension).*(upperbound); % Upper limit for variables
%%
for i=1:dimension
X(:,i) = lowerbound(i)+rand(SearchAgents,1).*(upperbound(i) - lowerbound(i)); % Initial population
end
for i =1:SearchAgents
L=X(i,:);
fit(i)=fitness(L);
end
%%
X_old=X;
F_old=fit;
for t=1:T
%% update the best member
[best , blocation]=min(fit);
if t==1
xbest=X(blocation,:); % Optimal location
fbest=best; % The optimization objective function
elseif best<fbest
fbest=best;
xbest=X(blocation,:);
end
[worst , wlocation]=max(fit);
RE_index=0.5;
if fbest<0
RE_index=1/RE_index;
end
if RE_index*mean(fit)<= fbest
for i=1:dimension
X(:,i) = lowerbound(i)+rand(SearchAgents,1).*(upperbound(i) -lowerbound(i)); % Initial population
end
X(SearchAgents,:)=xbest;
for i =1:SearchAgents
L=X(i,:);
fit(i)=fitness(L); % Fitness evaluation
end
end
%%
%%
K_t=xbest;
for i=1:SearchAgents
if rem (t,2)==0
RAND1=rand(1,dimension);
RAND2=rand(1,dimension);
else
RAND1=rand(1,1);
RAND2=rand(1,1);
end
%%
%% Phase 1: The gradual growth of the preschool teacher's educational influence
I=round(1+rand(1,1));
X_P1(i,:)=(1-(t/T)).*X(i,:)+(t/T).*(K_t);%Eq(4)
X_P1(i,:) = max(X_P1(i,:),lowerbound);X_P1(i,:) = min(X_P1(i,:),upperbound);
% update position based on Eq (5)
L=X_P1(i,:);
F_P1(i)=fitness(L);
if(F_P1(i)<fit(i))
X(i,:) = X_P1(i,:);
fit(i) = F_P1(i);
end
%% END Phase 1: The gradual growth of the preschool teacher's educational influence
%%
%% Phase 2: Individual knowledge development guided by the teacher (exploration)
I=round(1+rand(1,1));
X_P2(i,:)=X(i,:)+RAND2.*(K_t-I.*X(i,:));%Eq(6)
X_P2(i,:) = max(X_P2(i,:),lowerbound);X_P2(i,:) = min(X_P2(i,:),upperbound);
% update position based on Eq (7)
L=X_P2(i,:);
F_P2(i)=fitness(L);
if(F_P2(i)<fit(i))
X(i,:) = X_P2(i,:);
fit(i) = F_P2(i);
end
%% END Phase 2: Individual knowledge development guided by the teacher (exploration)
%%
% Phase 3: Individual increase of knowledge and self-awareness
I=round(1+rand(1,1));
if F_old(i)<fit(i)
X_P3(i,:)=X(i,:)+rand.*(X_old(i,:)-X(i,:));%Eq(8)
else
X_P3(i,:)=X(i,:)+rand.*(X(i,:)-X_old(i,:));%Eq(8)
end
X_P3(i,:) = max(X_P3(i,:),lowerbound);X_P3(i,:) = min(X_P3(i,:),upperbound);
% update position based on Eq (9)
L=X_P3(i,:);
F_P3(i)=fitness(L);
if(F_P3(i)<fit(i))
X(i,:) = X_P3(i,:);
fit(i) = F_P3(i);
end
X_old(i,:)=X(i,:);
F_old(i)=fit(i);
%% END Phase 3: Individual increase of knowledge and self-awareness
%%
end% END for i=1:SearchAgents
best_so_far(t)=fbest;
end% END for t=1:T
Best_score=fbest;
Best_pos=xbest;
PEOA_curve=best_so_far;
end
微信公众号搜索:淘个代码,获取更多免费代码
%禁止倒卖转售,违者必究!!!!!
%唯一官方店铺:https://mbd.pub/o/author-amqYmHBs/work
%代码清单:https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu参考文献
[1]Trojovský P. A new human-based metaheuristic algorithm for solving optimization problems based on preschool education[J]. Scientific Reports, 2023, 13(1): 21472.
完整代码获取
后台回复关键词:
TGDM811
获取更多代码:

或者复制链接跳转:
https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











