






截止到本期,一共发了11篇关于机器学习预测全家桶Python代码的文章。参考往期文章如下:
2.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!最强模板!
3.机器学习预测全家桶-Python,新增CEEMDAN结合代码,大大提升预测精度!
4.机器学习预测全家桶-Python,新增VMD结合代码,大大提升预测精度!
5.Python机器学习预测+回归全家桶,再添数十种回归模型!这次千万别再错过了!
6.Python机器学习预测+回归全家桶,新增TCN,BiTCN,TCN-GRU,BiTCN-BiGRU等组合模型预测
7.调用最新mealpy库,实现215个优化算法优化CNN-BiLSTM-Attention,电力负荷预测
8.Transformer实现风电功率预测,python预测全家桶
9.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)时间序列预测
10.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)回归预测
11.接着更!seq2seq、wavenet、bert、informer、RNN时间预测模型
从推出python预测全家桶以来,即便很多案例注释已经写的很清楚了,但是后台经常收到数据替换不友好,小白学起来还是费劲等等的留言,这也怪我,是我写的不够简单明了!本期对python全家桶来一个重大更新, 彻底解决小白替换数据困难,模型切换繁琐,网络参数修改复杂的问题。
本期更新内容如下:
1.模型函数化,文件目录更简单明了,集合了40余种常见或新颖的模型。文件夹如下:

是不是一目了然了!原先的预测全家桶,打开之后一堆主文件,导致小白拿到手后,不知道哪个能运行哪个不能运行,现在好了,作者将所有的模型写成了函数,这样真的很方便小伙伴对各个模型进行调用,代码也更易理解了!
目前集合的模型大致如下:
CNN_BiLSTM、CNN_BiLSTM_Attention、Bagging、BiGRU、
BiGRU_Attention、BiLSTM、BiLSTM_Attention、BiTCN_BiGRU、
BiTCN_GRU、BiTCN_LSTM、BP、CART、CNN_BiGRU_Attention、
CNN_BiGRU、CNN_GRU_Attention、CNN_GRU、CNN_LSTM_Attention、
CNN_LSTM、ELM、GradientBoost、GRU、GRU_Attention、LSTM、
LSTM_Attention、RandomForest、RBF、SVR、TCN、TCN_RNN、TCN_LSTM、
TCN_GRU、TCN_BiGRU、XGBOOST、Transformer、BiLSTM_KAN、
GRU_KAN、LSTM_KAN、Transformer_KAN、 seq2seq、RNN、
wavenet、bert、informer另外还包括一些双分解预测,智能优化算法结合模型的代码,这里就不再一一列出。
除此之外,在这里透露一下最近要出一期调用智能优化算法meaply库,实现对所有模型一键调用的代码,这样可以一下子采用上百种算法结合这些模型进行优化了,代码初步框架已经写好,就差调试与测试了,可以浅浅期待一下!
2. 主函数十分简单即可切换模型,预留了各模型接口参数,方便小白一键更改。主函数代码如下:
if __name__ == '__main__':
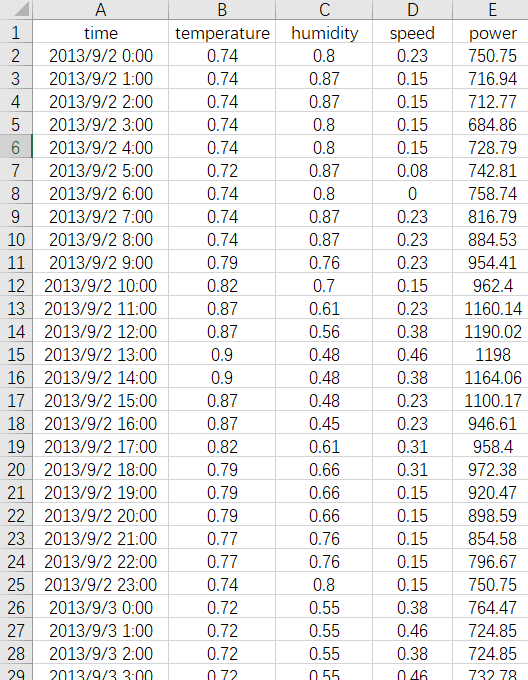
dataset = pd.read_excel("风电场功率预测.xlsx") #这里修改你的数据!
# dataset=pd.read_csv("电力负荷预测数据2.csv",encoding='gb2312')
# 参数'encoding'设置为'gbk',这通常用于读取中文字符,确保文件中的中文字符能够正确读取。
# 读取的数据被存储在名为'dataset'的DataFrame变量中。
# print(dataset) # 显示dataset数据
# 单输入单步预测,就让valuess等于某一列数据,n_out = 1,n_in, num_samples, scroll_window 根据自己情况来
# 单输入多步预测,就让valuess等于某一列数据,n_out > 1,n_in, num_samples, scroll_window 根据自己情况来
# 多输入单步预测,就让valuess等于多列数据,n_out = 1,n_in, num_samples, scroll_window 根据自己情况来
# 多输入多步预测,就让valuess等于多列数据,n_out > 1,n_in, num_samples, scroll_window 根据自己情况来
## 总结一下案例,需要哪个,就把哪个案例对照着改即可!
## 开始实验!!只改下面三行即可切换案例!!
n_in = 8 # 输入前8个时刻的数据
n_out = 1 # 预测未来一个时刻的负荷
valuess = dataset.values[:, 1:] # 只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:,这时候就是多特征输入
# 确保所有数据是浮动的
valuess = valuess.astype('float32')
# 将values数组中的数据类型转换为float32。
# 这通常用于确保数据类型的一致性,特别是在准备输入到神经网络模型中时。
or_dim = valuess.shape[1] # 记录特征数据维度
scroll_window = 1 # 如果等于1,下一个数据从第二行开始取。如果等于2,下一个数据从第三行开始取
num_samples = 3000 # 可以设定从数据中取出多少个点用于本次网络的训练与测试。
# 注意这里num_samples并不是数据的行数,因为数据在整理的时候,需要多步预测1步,或者预测多步,那么最后一个样本将会占据多行,因此一般要设置少于数据的行数
train_ratio = 0.8 #训练集比例
#调用数据整理的函数,关于测函数的机理是什么,请跳转Shared_def函数中查看data_collation的注释
vp_train, vp_test, vt_train, vt_test, m_out,Ytest = data_collation(valuess, n_in, n_out, or_dim, scroll_window, num_samples,train_ratio)
# 接下来就开始调用模型并开始训练喽!
'''
参数设置和模型选择
可选模型有:把以下模型赋值给 flag变量即可!
CNN_BiLSTM、CNN_BiLSTM_Attention、Bagging、BiGRU、BiGRU_Attention、BiLSTM、BiLSTM_Attention、BiTCN_BiGRU、BiTCN_GRU、BiTCN_LSTM
BP、CART、CNN_BiGRU_Attention、CNN_BiGRU、CNN_GRU_Attention、CNN_GRU、CNN_LSTM_Attention、CNN_LSTM、ELM、GradientBoost、GRU
GRU_Attention、LSTM、LSTM_Attention、RandomForest、RBF、SVR、TCN、TCN_RNN、TCN_LSTM、TCN_GRU、TCN_BiGRU、XGBOOST、Transformer、
BiLSTM_KAN、 GRU_KAN、LSTM_KAN、Transformer_KAN、 seq2seq、RNN、wavenet、bert、informer
提示:经检测,GradientBoost、SVR只适用于单步输出,多步输出时会报错,这是官方的包所致,因此在用这两个方法时,请将n_out改为1
部分模型无法保存(只是一少部分)
'''
# 修改这里的flag即可切换不同的模型
flag = 'LSTM_KAN'
epochs = 80 #训练次数
batch_size = 12 #最小批训练大小
learning_rate = 1e-4 #学习率
fit_or_not = 1 #是否重新训练,如果要改为0,请保证至少已经训练过一次了。
# fit_or_not:,直接加载已保存的模型还是重新训练,本程序具备保存模型的功能,
# fit_or_not=1时,就重新训练模型(并保存模型到"模型保存"文件夹里),
# fit_or_not=0时,就直接加载保存好的模型进行训练(当然你得先有保存好的模型哦)
# 更多关于每个模型的参数设置,请在本页面的many_model定义中找到对应模型自己动手修改,都做好修改接口了,很方便。
#调用模型,并进行训练,训练之后,直接返回训练集的预测结果,测试集的预测结果,模型的训练过程(方便画训练损失函数曲线)。
(xunlian_predicted_data, ceshi_predicted_data) = many_model(flag,fit_or_not,epochs,batch_size,learning_rate,
vp_train, vp_test, vt_train, vt_test, m_out,n_out,n_in,or_dim)
#调用已经写好绘图函数
plot_result(valuess,ceshi_predicted_data, Ytest, n_in,n_out,flag)只要修改上述代码中的变量——flag,即可任意切换不同的模型。
关于各个模型的参数修改也简单,举例如下:
if flag == 'CNN_BiLSTM':
#更多参数请在这里设置!
#四个参数分别为:CNN滤波器个数,滤波器大小,正则化参数,BiLSTM的隐含层神经元个数
filters, kernel_size, Dropout, Hidden_size = 64,2,0.1,32
xunlian_predicted_data, ceshi_predicted_data = model.run_CNN_BiLSTM(filters, kernel_size, Dropout, Hidden_size)
if flag == 'TCN_RNN':
#四个参数分别为:TCN滤波器个数,滤波器大小,正则化参数,RNN的隐含层神经元个数
nb_filters,kernel_size,dro,RNN_units = 64,2,0.2,128
xunlian_predicted_data, ceshi_predicted_data = model.run_TCN_RNN(nb_filters,kernel_size,dro,RNN_units)这样,大家只需要找到想要修改的模型,修改相应的参数即可!
3.可对预测后的模型进行保存,在代码主函数中加入了一个变量fit_or_not,选择1,则正常进行模型训练,选择0,则直接调用保存好的模型进行训练。
fit_or_not = 1 #是否重新训练,如果要改为0,请保证至少已经训练过一次了。
# fit_or_not:,直接加载已保存的模型还是重新训练,本程序具备保存模型的功能,
# fit_or_not=1时,就重新训练模型(并保存模型到"模型保存"文件夹里),
# fit_or_not=0时,就直接加载保存好的模型进行训练(当然你得先有保存好的模型哦)4. 有详细的关于数据替换的示例介绍:准备了四种案例,只要按照注释一一修改这三个参数即可!(就不信小白还不会改数据!)
'''
#案例1:单特征输入,单步预测
#请按照以下进行设置:采用前12个时刻的所有负荷数据,预测未来一个小时的负荷值。
n_in = 12 # 输入前12个时刻的数据
n_out = 1 # 预测未来一个时刻的负荷
valuess = dataset.values[:,-1:] #因为是单特征输入,那么就只输入最后一列负荷值就行了。 -1表示倒数第一列,注意看清楚,这里是 -1:
'''
'''
#采用超前多步预测的时候,由于测试样本不止一个,因此绘图的时候,不可能全部都画出来,这里就挑出来一个测试样本进行绘图。
# 案例2:单特征输入,超前多步预测
#请按照以下进行设置:采用前96个时刻的所有负荷数据,预测未来24个小时的负荷值。
n_in = 96 # 输入前96个时刻的数据
n_out = 24 # 预测未来24个时刻的负荷
valuess = dataset.values[:,-1:] #因为是单特征输入,那么就只输入最后一列负荷值就行了。 -1表示倒数第一列,注意看清楚,这里是 -1:
'''
'''
# 案例3:多特征输入,单步预测
# 请按照以下进行设置:采用前8个时刻的所有特征数据(包括已知的负荷值),预测未来一个小时的负荷值。
n_in = 8 # 输入前8个时刻的数据
n_out = 1 # 预测未来一个时刻的负荷
valuess = dataset.values[:,1:] #只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:,这时候就是多特征输入
因为这里原始数据第一列都是时间,所以才写成了1:,意思是去除了时间列
'''
'''
#采用超前多步预测的时候,由于测试样本不止一个,因此绘图的时候,不可能全部都画出来,这里就挑出来一个测试样本进行绘图。
# 案例4:多特征输入,超前多步预测(这种预测模型难度较大,因此精度不一定会好!!!)
# 请按照以下案例:采用前7天数据,预测未来一天(24个小时)的负荷值。
n_in = 24*7 # 输入前7天数据,每天有24个小时,因此这里是24*7
n_out = 24*1 # 预测未来一天的负荷值,也就是24个小时。因此这里是24,。
valuess = dataset.values[:,1:] #只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:,这时候就是多特征输入
因为这里原始数据第一列都是时间,所以才写成了1:,意思是去除了时间列
'''只要你的数据也是这种形式(第一列为时间列,2~n-1列为特征列,最后一列为预测列),完全可以按照上述参数设置,简单进行四种案列的切换。
5.对预测结果进行保存,
运行模型后,会将训练集的预测结果和测试集的预测结果保存到《预测结果保存》文件夹内,同时还会将预测结果图,损失函数曲线图都保存下来。
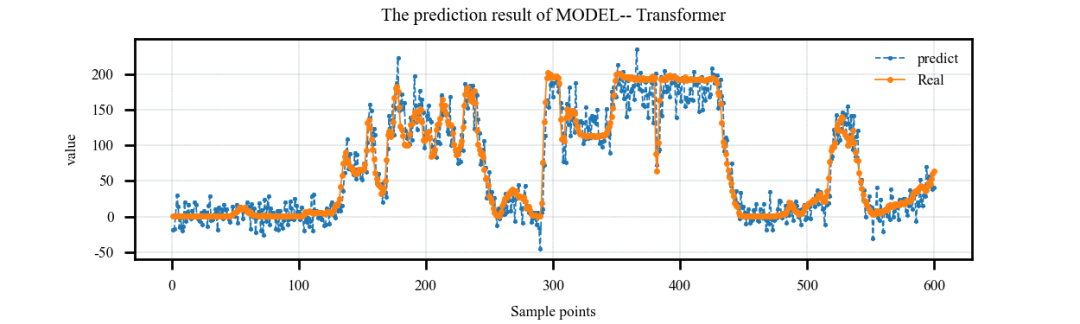
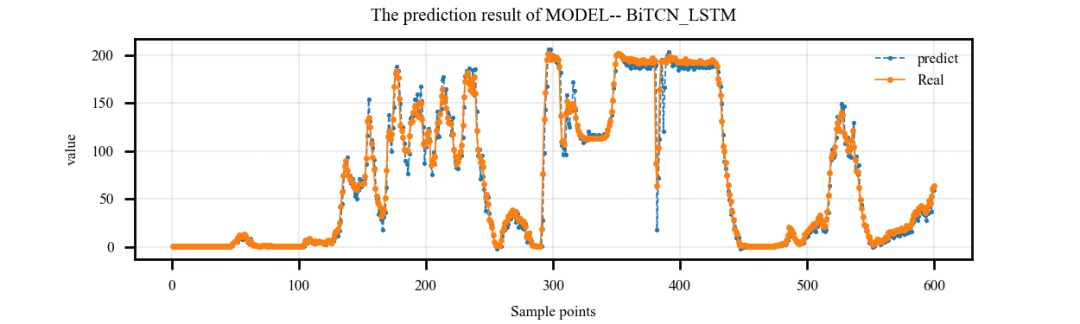
接下来让我们简单挑选几个模型进行结果展示吧!
案例1:单特征输入,单步预测案例:
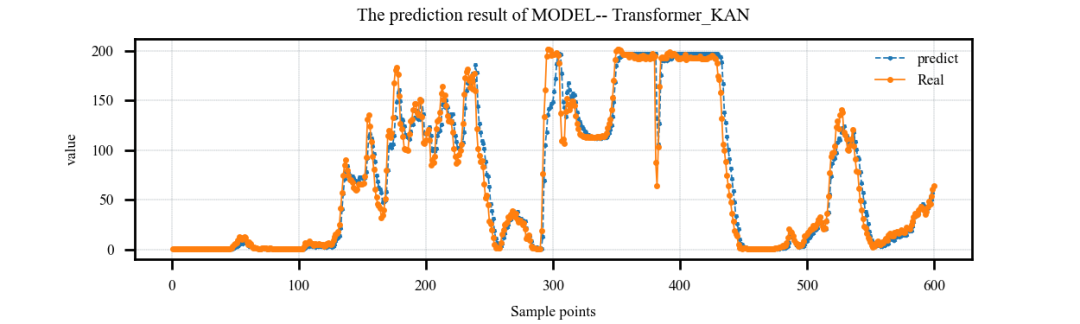
案例2:单特征输入,多步预测案例:
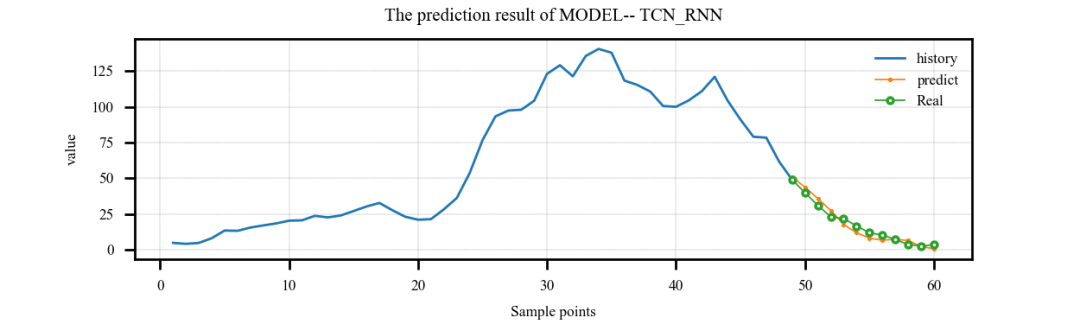
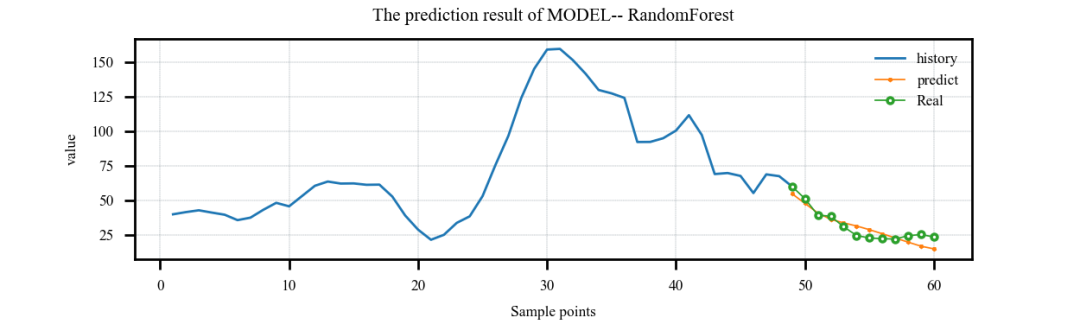
案例3:多特征输入,单步预测案例:
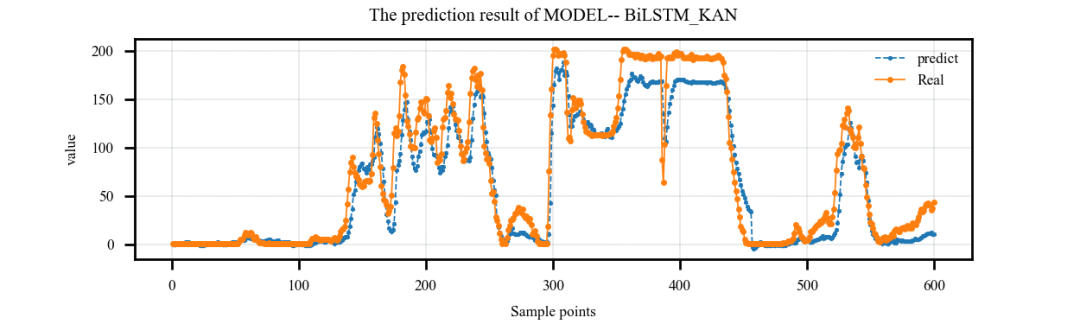
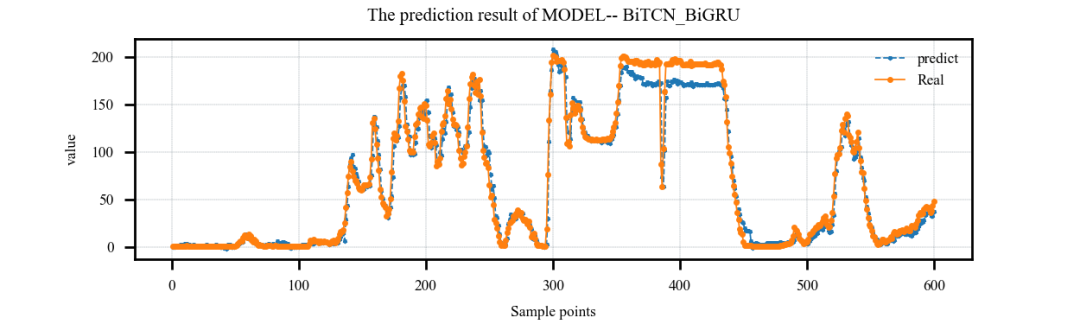
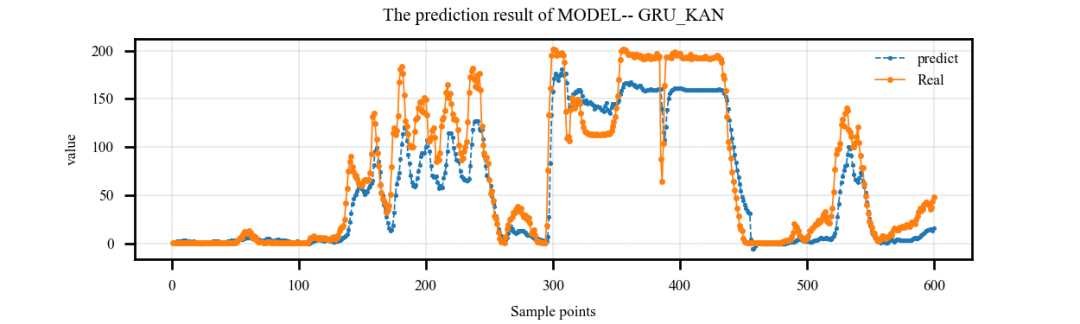
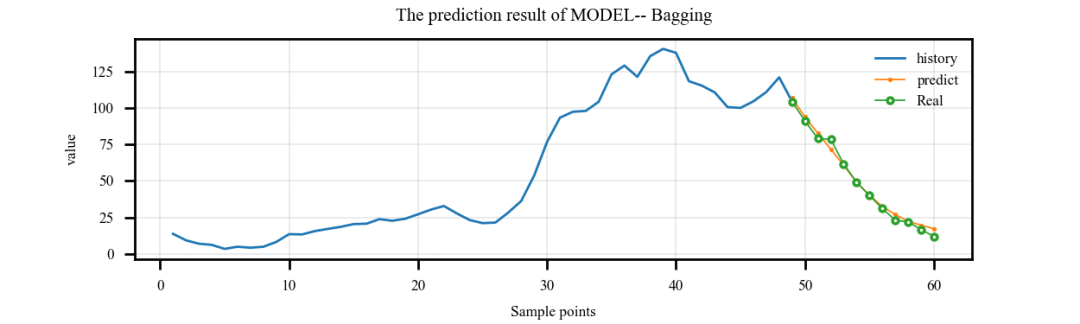
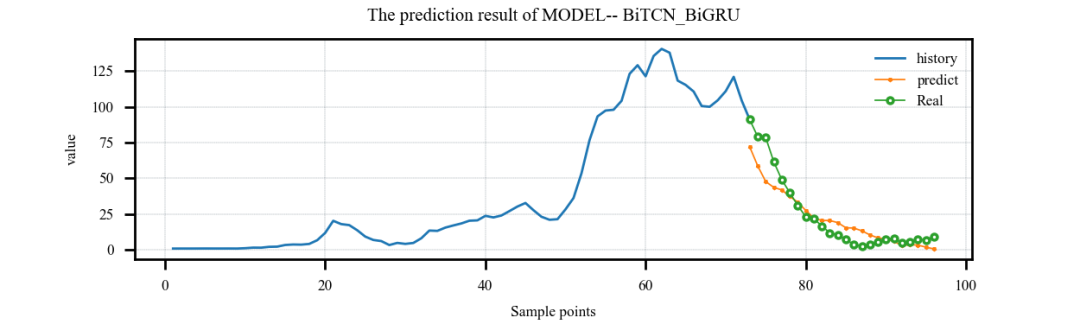
案例4:多特征输入,多步预测案例:
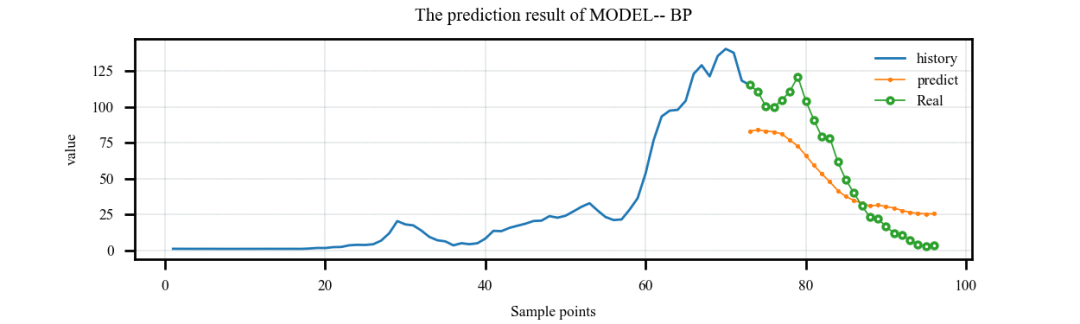
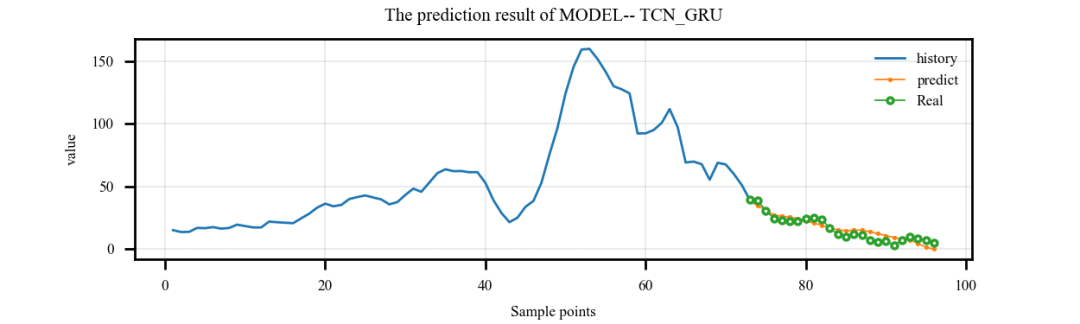
代码获取
已将本文代码更新至python预测全家桶。
后续会继续更新一些其他模型……敬请期待!
点击下方卡片关注,获取更多代码
python预测全家桶pip包推荐版如下:
tensorflow~=2.15.0
pandas~=2.2.0
openpyxl~=3.1.2
matplotlib~=3.8.2
numpy~=1.26.3
keras~=2.15.0
mplcyberpunk~=0.7.1
scikit-learn~=1.4.0
scipy~=1.12.0
qbstyles~=0.1.4
prettytable~=3.9.0
vmdpy~=0.2
xgboost~=2.0.3
mealpy~=3.0.1
torch~=2.3.1推荐使用3.9版本的python哦!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











