






目录
最小均方(LMS:least mean square)滤波器
自适应算法可以不经人的干预,仅仅根据接收数据的变换而做出相应的变化。算法在做出改变之前,不需要人对它调整和处理,算法能够从数据中感觉到变化,并学习到数据的相应的发展,并根据自己学到的知识自行地做出改变。因此自适应和学习(learning)是相对应的。

牛顿步(Newton Step)



最速下降法考虑问题比较简单,它沿着梯度的逆方向寻找函数最小值。对于一个函数,为了寻找它的最小值,最直观的方法是沿着梯度逆方向寻找,当然这个方向有没有最小值事先很难知道,但有一点可以明确,只要沿着这个方向,函数值一定不会变大。最速下降法实现起来很简单,但寻在的问题也很多,人们在使用它的时候,总用很多条件限制来规避可能遇到的问题,比如凸优化(在凸优化问题中,只考虑凸函数,而在凸函数中,极小值就是最小值,它是唯一存在的)。
在最速下降法中,还有一个因素需要考虑:步长。步长的设置对算法的性能是非常关键的,因为步长过长,算法执行速度快,但有可能跨过最小值,在最小值附近来回跳跃;而步长过短,执行速度很慢。
最小均方(LMS:least mean square)滤波器



即便过程是遍历的,在求梯度的过程中,问题还是存在的,因为求梯度要付出时间代价,但是当前时刻所能掌握的只有N,没有其他数据。LMS做了一个非常大胆的假设,原本是要求期望的,这是一个平均效益,但是在期望无法求得的情况下,它直接放弃期望,用瞬时值代替均值,这会造成非常大的波动,且难以收敛。而事实上,无数工程实践证明,只要选取合适的步长,不仅可以收敛,而且收敛的速度还很快。所以LMS在工程实践中有广泛的应用,如回声抵消、信道均衡。
αN 的收敛性分析
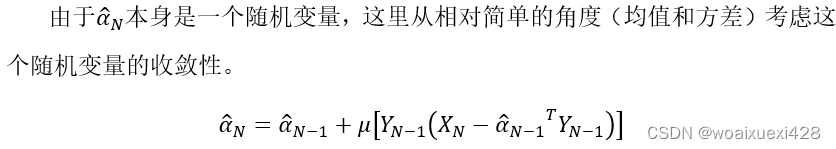
收敛性


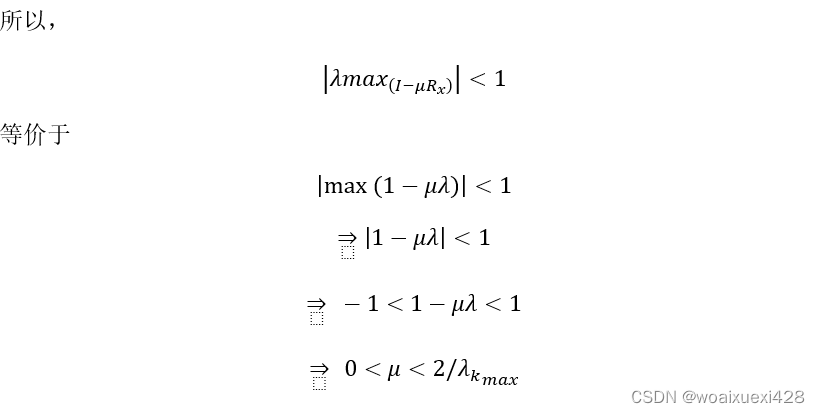
这个条件是均值收敛的充要条件,它是加在步长上的,这充分说明了步长的重要性。上式对步长的上界进行了控制,即步长不能太大,只要步长控制在一定范围内,随着N的增大,均值定会收敛,且收敛呈指数形式,速度很快。
均方误差VarαN 的收敛性


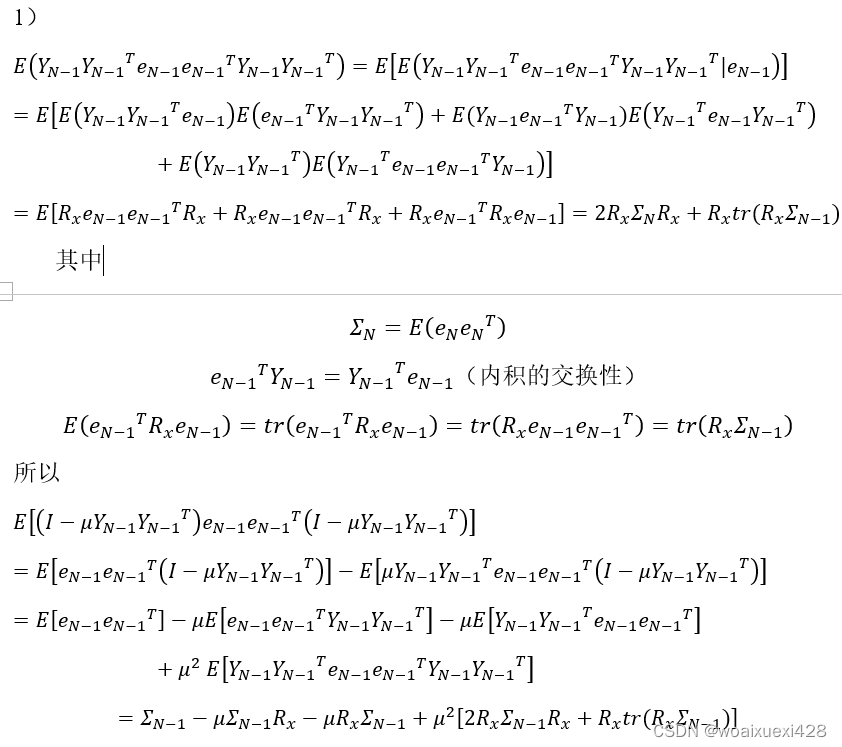
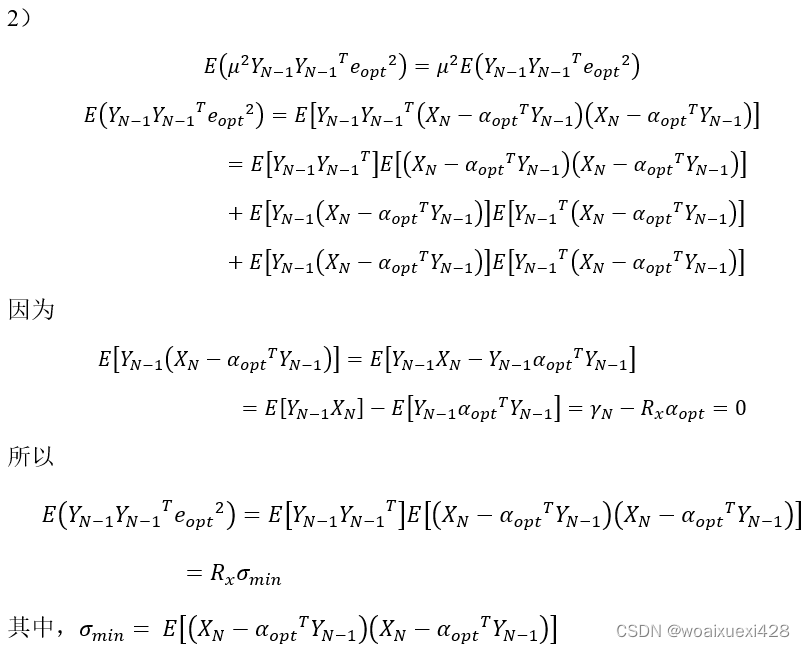
得到这个结果主要做了两个假设:一是Y是相互独立的,这使Y与e分开处理;二是Y服从联合高斯分布,这样才方便处理多个Y,因为2)中要计算误差的二阶项,而误差本事就是Y的二阶项,只有在高斯的条件下才方便处理。值得一提的是,在工程实践中,即使Y不服从高斯分布,上面的结果也成立。
直观地看,这里做的假定比前面均值要强,因为均值是一阶的,方差是高阶的。均值虽然逐渐收敛至目标值,但这并不能说明太多问题,原因在于如果不对均方误差做有效控制的话,均值的收敛可能存在较大的振荡,所以均值不能代表瞬时值,尽管LMS大胆地用瞬时值代替了平均值。因此我们要对步长做更强的假定以确保均值收敛时有较小的震荡,且随着N的增加,振荡不断减小。

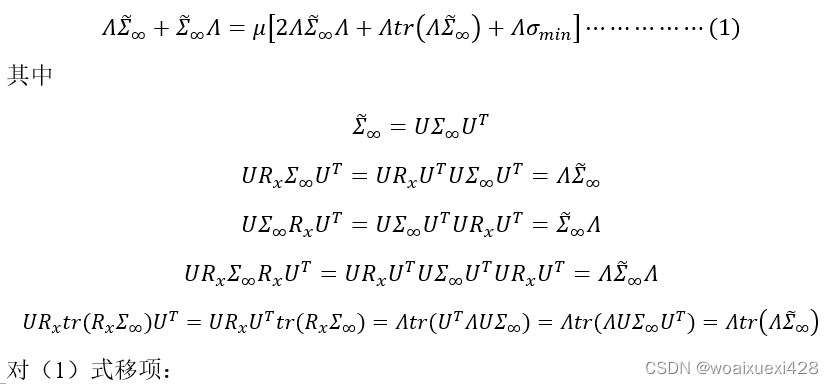

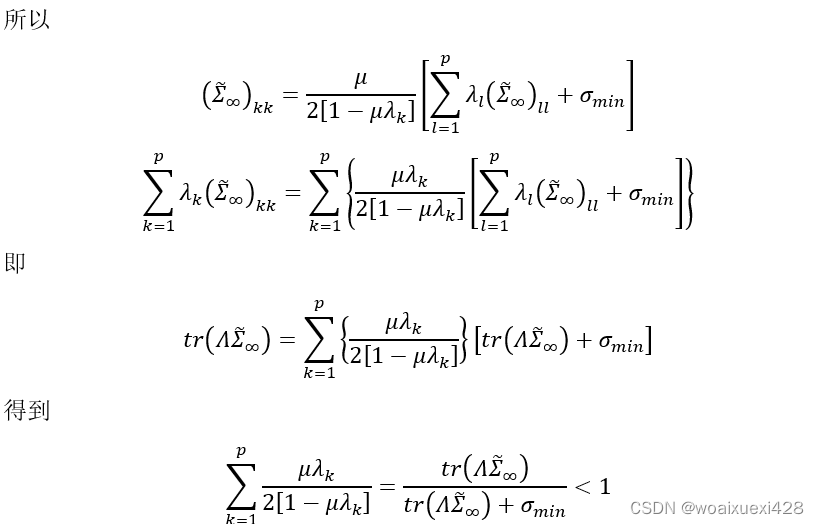


------------------------------------------------------------------------------------------------
因为文档中公式较多,不方便编辑,所以本文使用截图的方式展现。如需电子版文档,可以通过下面的链接进行下载。
链接![]() http://generatelink.xam.ink/change/makeurl/changeurl/11774
http://generatelink.xam.ink/change/makeurl/changeurl/11774















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









