







Spark 共享变量
1.1 广播变量

在执行map操作时,若利用到driver中的数据(即本地数据),需要复制到每个分区中。实际上每个executor进程只需要一份数据即可,所以这样做会造成内存浪费。
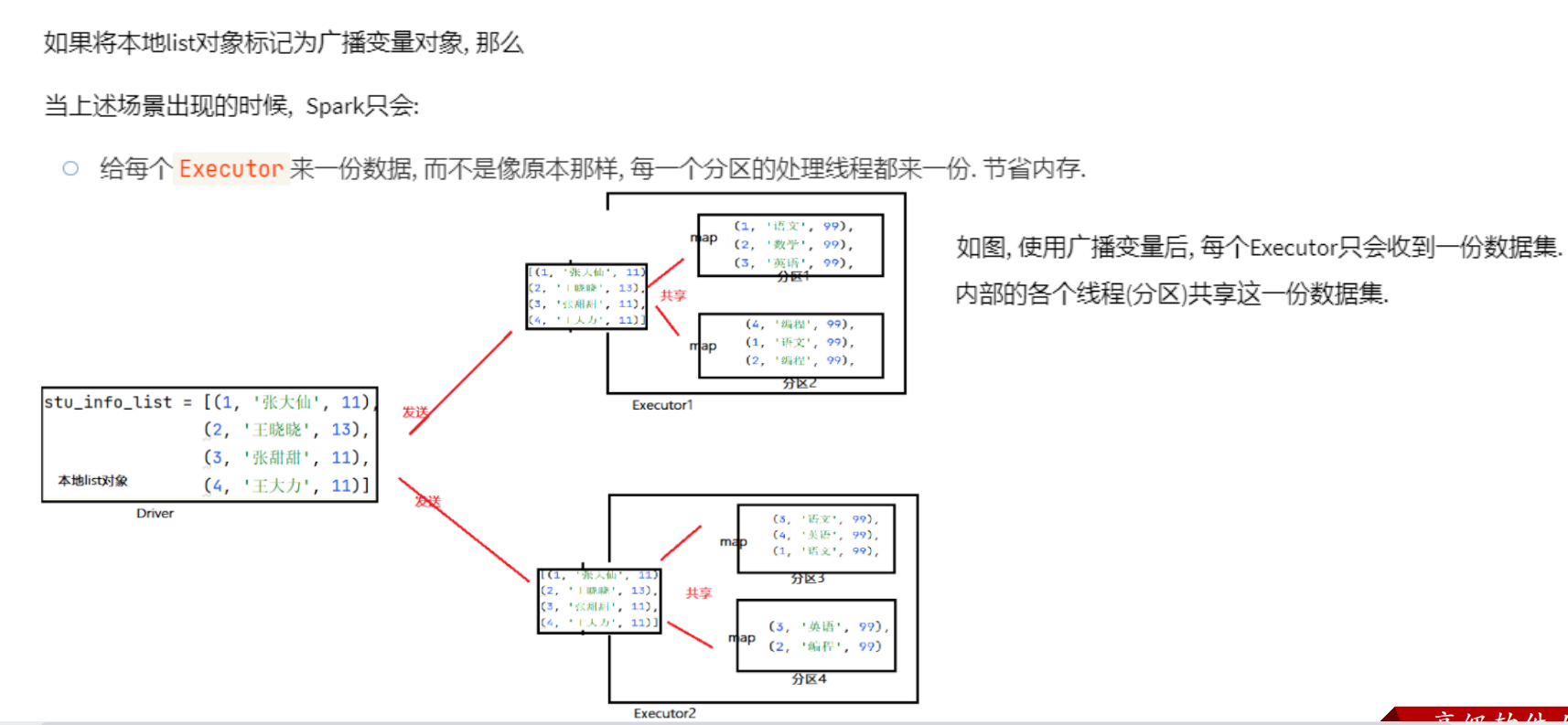
使用共享变量后,每个executor只会收到一份数据。
#1.将本地list标记成广播变量即可
broadcast = sc.broadcast(stu_info_list)
#2.使用广播变量,从broadcast对象中取出本地list对象即可
value = broadcast.value
#也就是先放进去broadcast内部,然后从broadcast内部再取出来用,中间传输的是broadcast这个对象了
#只要中间传输的是broadcast对象,spark就会留意,只会给每个executor发一份了,而不是傻傻的哪个分区要都给。
1.2 累加器
想要让executer中累加的数据最终作用到driver上。因为使用累加器前executor中的数据与driver无关。
使用 s c . a c c u m u l a t o r ( 初始值 ) \textcolor{CornflowerBlue}{sc.accumulator(初始值)} sc.accumulator(初始值) 即可构建,这个对象可以从各个executor中收集它们的执行结果,最终作用在自己身上。使用时直接使用这个变量即可。

1.3 总结
广播变量的作用:分布式RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络I/O传输,提高性能。
累加器的作用:分布式代码执行过程中,进行全局累加。















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









