









Overview
Hadoop 的任务是通过Job对像提交到系统处理的,所以Job对像带有一切运行任务所需要的信息。下图展示了,Job运行过程所经历的所有阶段:
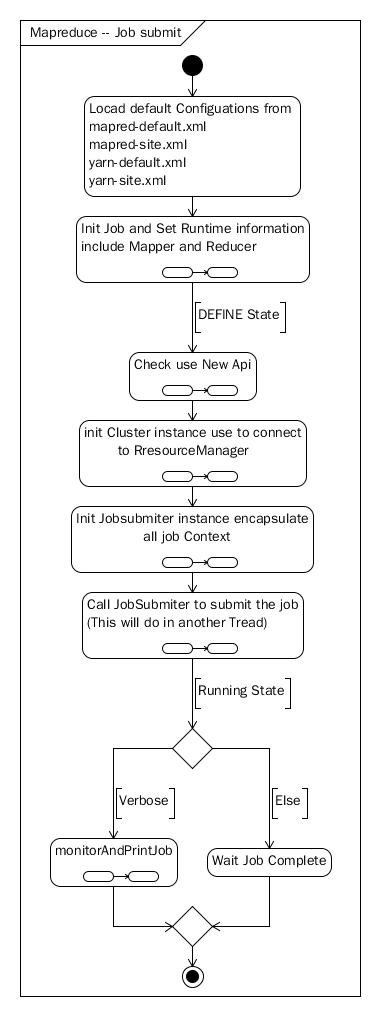
图 1-1
在配置 完Job对像之后,Job会首初始化一个Cluster对像,用来保存Cluster相关的信息,包括用来与ResourceManager通信的客户端:
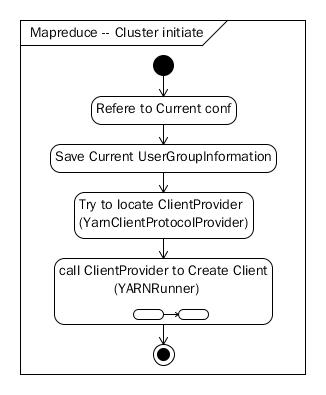
图 1-2
Cluster对像初始化的时候,会先去寻找 ClientProvider实现,配置在文件:META-INF/services/org.apache.hadoop.mapreduce.protocol.ClientProtocolProvider中, 默认为:YarnClientProtocolProvider,最后通过provider创建ClientProtocol对像,实现类为:YARNRunner
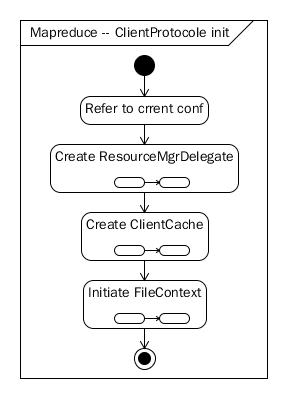
图 1-3
ClientProtocol在初始化的时候,会创建一个ResourceMgrDelegate对像用来与ResourceManager通信,创建一个ClientCache用来与ApplicationMaster及HistoryServer通信:
相关配置信息:
- yarn.resourcemanager.address
- yarn.client.app-submission.poll-interval: Default is: 1000ms
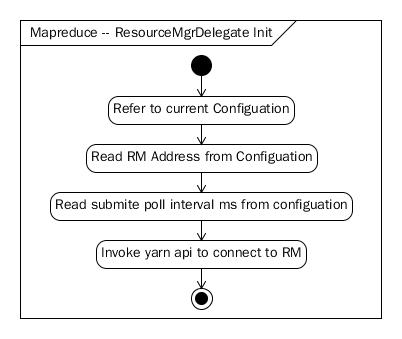
图 1-4
然后job用这些信息创建 Jobsubmiter对像。最后通过Jobsubmiter提交Job:
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
Job Submit handle:

图 2-1
Job Handle in Jobsubmitter
当Job提交到Jobsubmiter之后, submitter开始组织运行该Job的信息:
- Job的spec 信息;主要是检查输出目录是否已经存在,若已经存在,则退出;
- Job的StageArea目录;
- 提交Job的主机信息;
- 请求jobId信息;
- 生成job运行时目录信息;
- 设置hadoop.http.filter.initializers为:org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer
- 运行job所需的Tokens
- 初始化安全链接所需的keypair 信息;
- Split job;
- 生成运行时的configuration 文件;
然后submiter把job提交到ClientProtocol对像(YarnRunner)
//validate the jobs output specs
checkSpecs(job);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster,
job.getConfiguration());
//configure the command line options correctly on the submitting dfs
Configuration conf = job.getConfiguration();
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
Job Handle in ClientProtocol(YarnRunner)
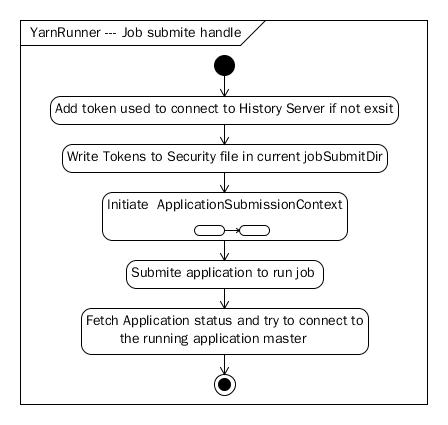
图 2-2
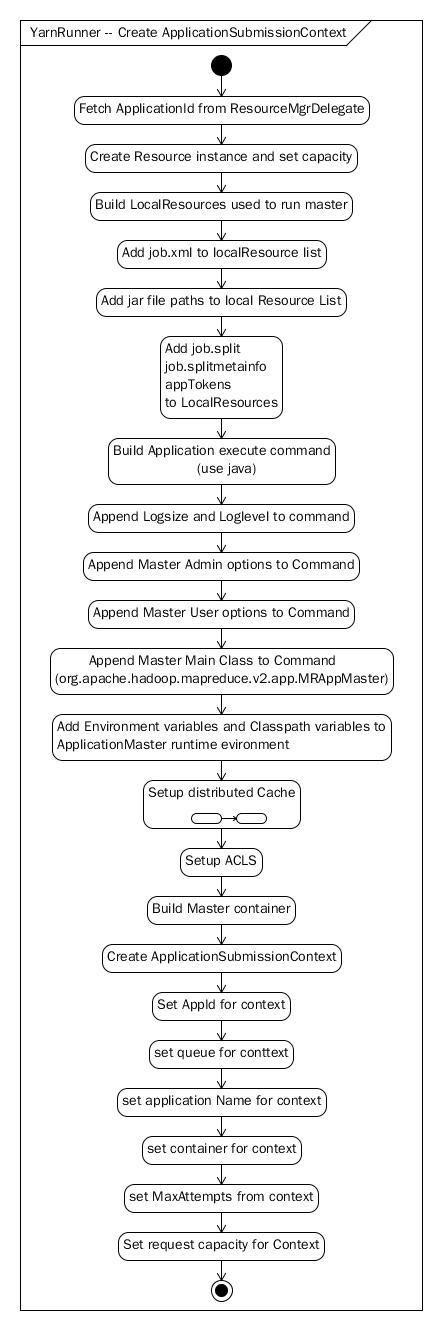
图 2-3
ApplicationId applicationId = resMgrDelegate.getApplicationId();
// Setup resource requirements
Resource capability = recordFactory.newRecordInstance(Resource.class);
capability.setMemory(
conf.getInt(
MRJobConfig.MR_AM_VMEM_MB, MRJobConfig.DEFAULT_MR_AM_VMEM_MB
)
);
capability.setVirtualCores(
conf.getInt(
MRJobConfig.MR_AM_CPU_VCORES, MRJobConfig.DEFAULT_MR_AM_CPU_VCORES
)
);
LOG.debug("AppMaster capability = " + capability);
// Setup LocalResources
Map<String, LocalResource> localResources =
new HashMap<String, LocalResource>();
Path jobConfPath = new Path(jobSubmitDir, MRJobConfig.JOB_CONF_FILE);
URL yarnUrlForJobSubmitDir = ConverterUtils
.getYarnUrlFromPath(defaultFileContext.getDefaultFileSystem()
.resolvePath(
defaultFileContext.makeQualified(new Path(jobSubmitDir))));
LOG.debug("Creating setup context, jobSubmitDir url is "
+ yarnUrlForJobSubmitDir);
localResources.put(MRJobConfig.JOB_CONF_FILE,
createApplicationResource(defaultFileContext,
jobConfPath, LocalResourceType.FILE));
if (jobConf.get(MRJobConfig.JAR) != null) {
Path jobJarPath = new Path(jobConf.get(MRJobConfig.JAR));
LocalResource rc = createApplicationResource(defaultFileContext,
jobJarPath,
LocalResourceType.PATTERN);
String pattern = conf.getPattern(JobContext.JAR_UNPACK_PATTERN,
JobConf.UNPACK_JAR_PATTERN_DEFAULT).pattern();
rc.setPattern(pattern);
localResources.put(MRJobConfig.JOB_JAR, rc);
} else {
// Job jar may be null. For e.g, for pipes, the job jar is the hadoop
// mapreduce jar itself which is already on the classpath.
LOG.info("Job jar is not present. "
+ "Not adding any jar to the list of resources.");
}
// TODO gross hack
for (String s : new String[] {
MRJobConfig.JOB_SPLIT,
MRJobConfig.JOB_SPLIT_METAINFO,
MRJobConfig.APPLICATION_TOKENS_FILE }) {
localResources.put(
MRJobConfig.JOB_SUBMIT_DIR + "/" + s,
createApplicationResource(defaultFileContext,
new Path(jobSubmitDir, s), LocalResourceType.FILE));
}
// Setup security tokens
DataOutputBuffer dob = new DataOutputBuffer();
ts.writeTokenStorageToStream(dob);
ByteBuffer securityTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
// Setup the command to run the AM
List<String> vargs = new ArrayList<String>(8);
vargs.add(Environment.JAVA_HOME.$() + "/bin/java");
// TODO: why do we use 'conf' some places and 'jobConf' others?
long logSize = TaskLog.getTaskLogLength(new JobConf(conf));
String logLevel = jobConf.get(
MRJobConfig.MR_AM_LOG_LEVEL, MRJobConfig.DEFAULT_MR_AM_LOG_LEVEL);
MRApps.addLog4jSystemProperties(logLevel, logSize, vargs);
// Check for Java Lib Path usage in MAP and REDUCE configs
warnForJavaLibPath(conf.get(MRJobConfig.MAP_JAVA_OPTS,""), "map",
MRJobConfig.MAP_JAVA_OPTS, MRJobConfig.MAP_ENV);
warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS,""), "map",
MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV);
warnForJavaLibPath(conf.get(MRJobConfig.REDUCE_JAVA_OPTS,""), "reduce",
MRJobConfig.REDUCE_JAVA_OPTS, MRJobConfig.REDUCE_ENV);
warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS,""), "reduce",
MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV);
// Add AM admin command opts before user command opts
// so that it can be overridden by user
String mrAppMasterAdminOptions = conf.get(MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS,
MRJobConfig.DEFAULT_MR_AM_ADMIN_COMMAND_OPTS);
warnForJavaLibPath(mrAppMasterAdminOptions, "app master",
MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.MR_AM_ADMIN_USER_ENV);
vargs.add(mrAppMasterAdminOptions);
// Add AM user command opts
String mrAppMasterUserOptions = conf.get(MRJobConfig.MR_AM_COMMAND_OPTS,
MRJobConfig.DEFAULT_MR_AM_COMMAND_OPTS);
warnForJavaLibPath(mrAppMasterUserOptions, "app master",
MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.MR_AM_ENV);
vargs.add(mrAppMasterUserOptions);
vargs.add(MRJobConfig.APPLICATION_MASTER_CLASS);
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR +
Path.SEPARATOR + ApplicationConstants.STDOUT);
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR +
Path.SEPARATOR + ApplicationConstants.STDERR);
Vector<String> vargsFinal = new Vector<String>(8);
// Final command
StringBuilder mergedCommand = new StringBuilder();
for (CharSequence str : vargs) {
mergedCommand.append(str).append(" ");
}
vargsFinal.add(mergedCommand.toString());
LOG.debug("Command to launch container for ApplicationMaster is : "
+ mergedCommand);
// Setup the CLASSPATH in environment
// i.e. add { Hadoop jars, job jar, CWD } to classpath.
Map<String, String> environment = new HashMap<String, String>();
MRApps.setClasspath(environment, conf);
// Setup the environment variables for Admin first
MRApps.setEnvFromInputString(environment,
conf.get(MRJobConfig.MR_AM_ADMIN_USER_ENV));
// Setup the environment variables (LD_LIBRARY_PATH, etc)
MRApps.setEnvFromInputString(environment,
conf.get(MRJobConfig.MR_AM_ENV));
// Parse distributed cache
MRApps.setupDistributedCache(jobConf, localResources);
Map<ApplicationAccessType, String> acls
= new HashMap<ApplicationAccessType, String>(2);
acls.put(ApplicationAccessType.VIEW_APP, jobConf.get(
MRJobConfig.JOB_ACL_VIEW_JOB, MRJobConfig.DEFAULT_JOB_ACL_VIEW_JOB));
acls.put(ApplicationAccessType.MODIFY_APP, jobConf.get(
MRJobConfig.JOB_ACL_MODIFY_JOB,
MRJobConfig.DEFAULT_JOB_ACL_MODIFY_JOB));
// Setup ContainerLaunchContext for AM container
ContainerLaunchContext amContainer = BuilderUtils
.newContainerLaunchContext(UserGroupInformation
.getCurrentUser().getShortUserName(), localResources,
environment, vargsFinal, null, securityTokens, acls);
// Set up the ApplicationSubmissionContext
ApplicationSubmissionContext appContext =
recordFactory.newRecordInstance(ApplicationSubmissionContext.class);
appContext.setApplicationId(applicationId); // ApplicationId
appContext.setQueue( // Queue name
jobConf.get(JobContext.QUEUE_NAME,
YarnConfiguration.DEFAULT_QUEUE_NAME));
appContext.setApplicationName( // Job name
jobConf.get(JobContext.JOB_NAME,
YarnConfiguration.DEFAULT_APPLICATION_NAME));
appContext.setCancelTokensWhenComplete(
conf.getBoolean(MRJobConfig.JOB_CANCEL_DELEGATION_TOKEN, true));
appContext.setAMContainerSpec(amContainer); // AM Container
appContext.setMaxAppAttempts(
conf.getInt(MRJobConfig.MR_AM_MAX_ATTEMPTS,
MRJobConfig.DEFAULT_MR_AM_MAX_ATTEMPTS));
appContext.setResource(capability);















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









