







oracle数据库判断某表是否存在
1、第一种sql
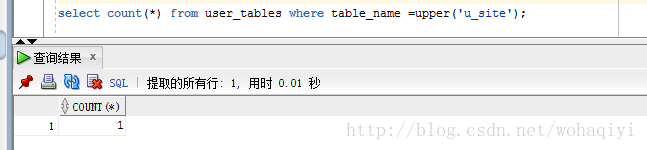
select count(*) from user_tables where table_name =upper('表名') 这个是查询当前登录用户中的所有表中是否存在该表。注意表名区分大小写,如果参数不限制,那这里就必须要加上upper函数 。
效果如下:
2、第二种sql
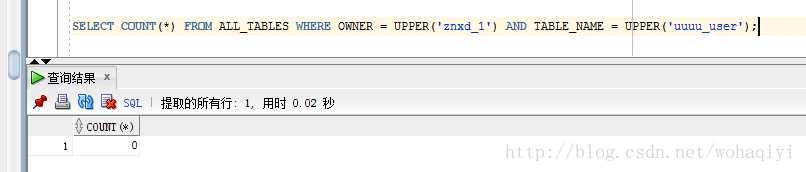
SELECT COUNT(*) FROM ALL_TABLES WHERE OWNER = UPPER('znxd_1')
AND TABLE_NAME = UPPER('sys_user') 这个是查询 znxd_1 这个用户下的表中是否存在该表。比如你登录的是znxd_gateway 这个用户,在它的查询面板上执行上边的sql,就可以查询znxd_1 这个用户下是否存在某表。
效果如下:
















 2009
2009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











