









kafka消费者
1、消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速度不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络堵塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据,针对这一点,kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时间即为timeout。
2、分区分配策略
一个consumer group 中又多个consumer,一个topic又多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由那个consumer来消费。
kafka由两种分配策略,一个是RoundRobin,另外一个是Range(默认)。
range在分配的时候,首先看订阅的消费者是谁,如果订阅者里面有一个组的,会把消息的partition,分配给组内订阅这个topic的消费者。range是优先topic的,在看组的。
RoundRobin这个是按组来分的,不同消费者组只能消费到自己分配到的partition数据,其他的就不能消费到了,它因为是轮询的机制,所以消费者组之间消费的数据差不多。
下面是分区策略的源码:org.apache.kafka.clients.producer.internals.DefaultPartitioner
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
我们可以自己实现一个分区规则:只要我们实org.apache.kafka.clients.producer.Partitioner
3、offset的维护
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了那个offset,以便故障恢复后继续消费
4、kafka高效读写数据
4.1、顺序写磁盘
kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量的磁头寻址的时间。
4.2、零复制技术(零复制)
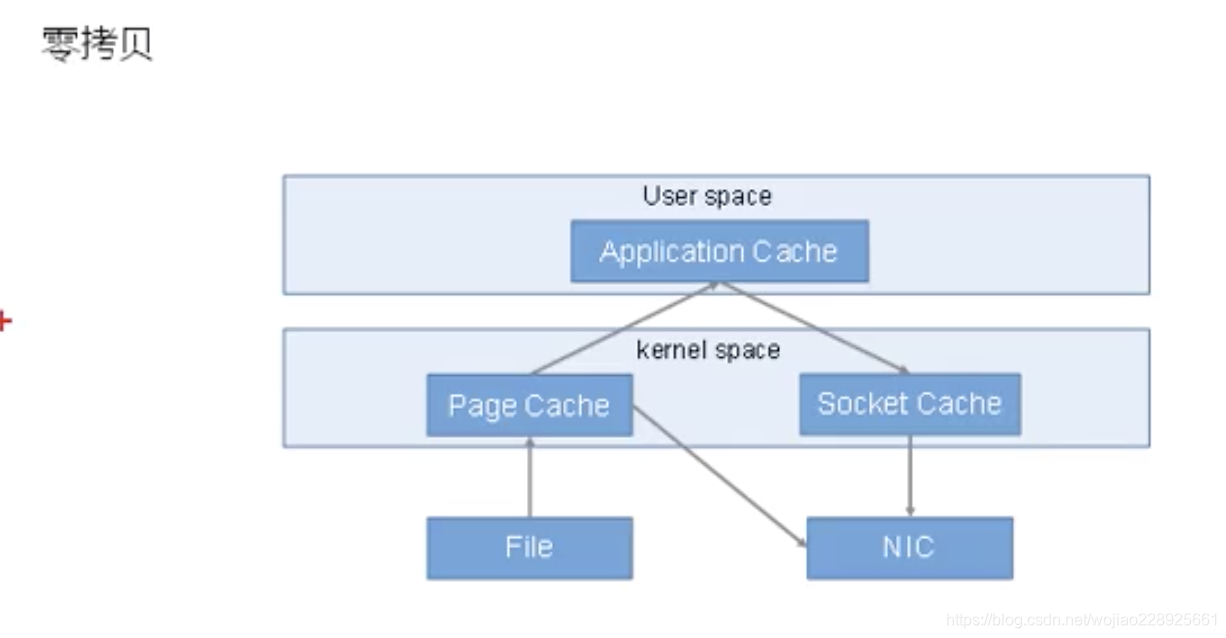
5、zookeeper在kafka中的作用
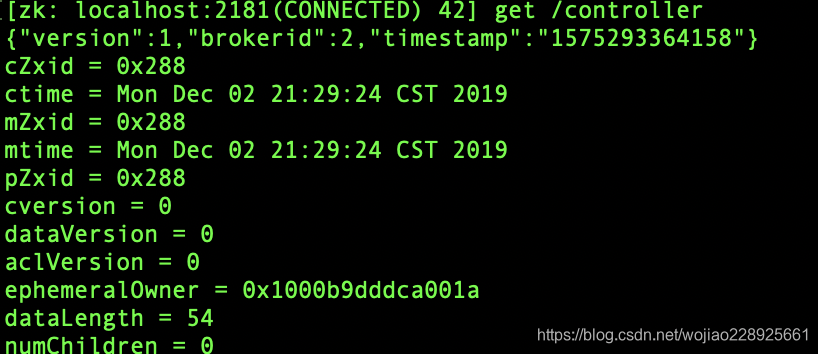
kafka集群中有一个broker会被选举为controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。controller的管理工作都是依赖于zookeeper的。
以下为partition的leader选举过程:
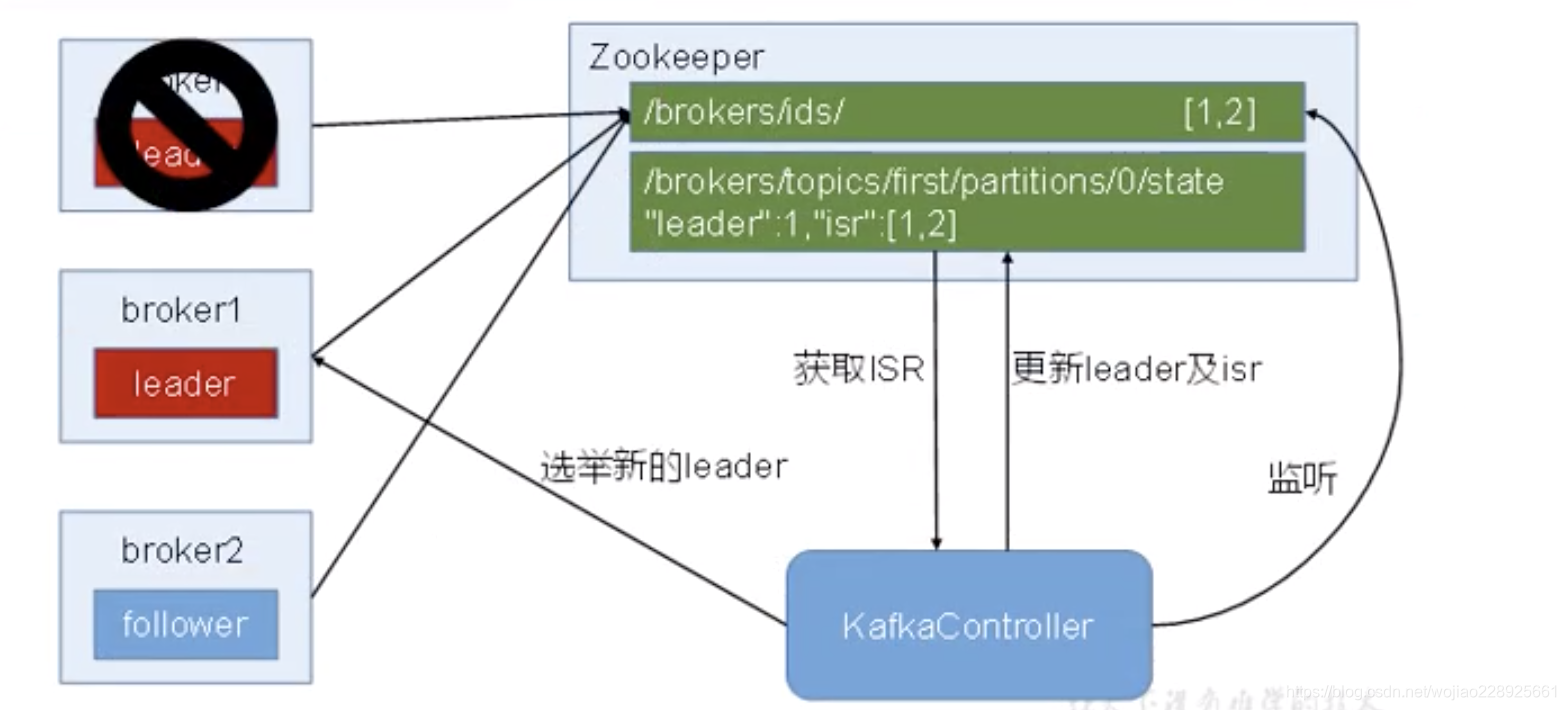
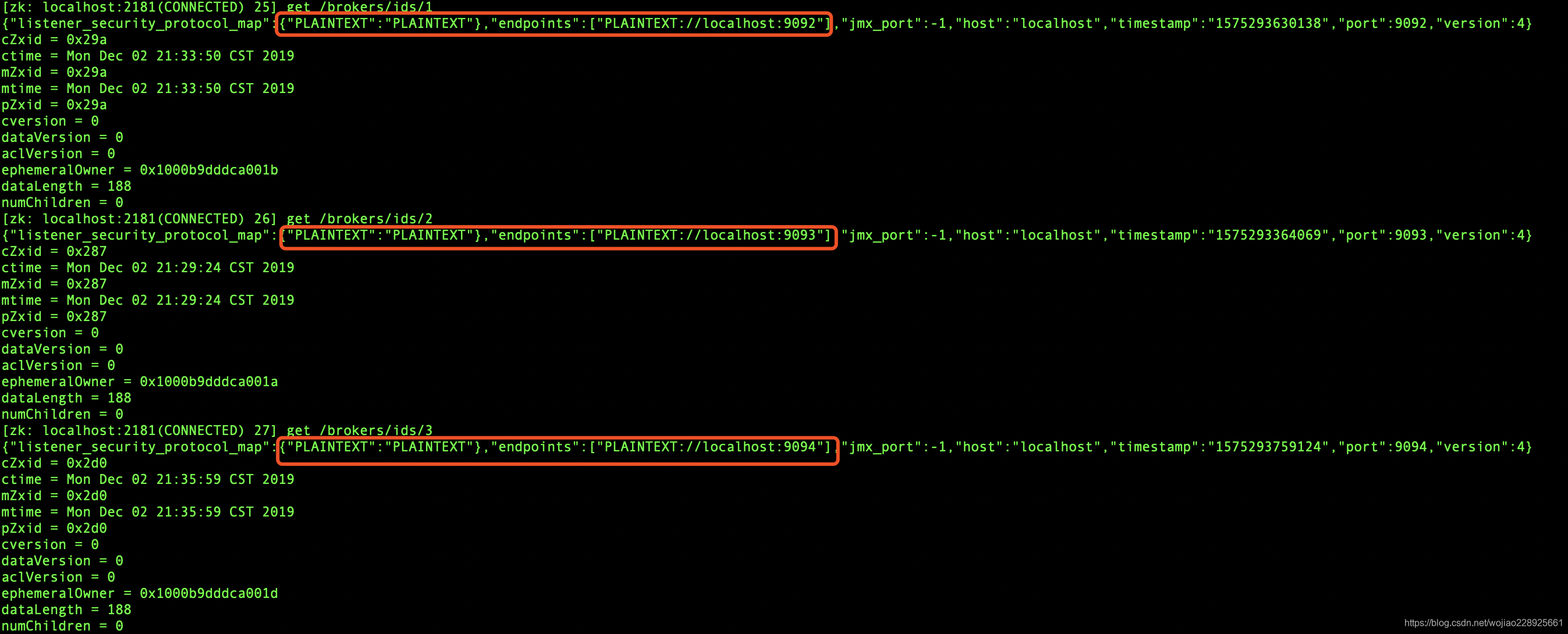
上图是kafka集群注册到zookeeper上,下图可以看到不同分区的leader,和isr的服务器
下面是在3台kafka集群上,建一个topic=TOPIC_SECOND_MESSAGE 两个分区,两个备份(备份数不能多余服务器数,也就是多少台kafka服务,分区可以是多台的) ./kafka-topics.sh --create --zookeeper localhost:2181 --topic TOPIC_SECOND_MESSAGE --partitions 2 --replication-factor 2
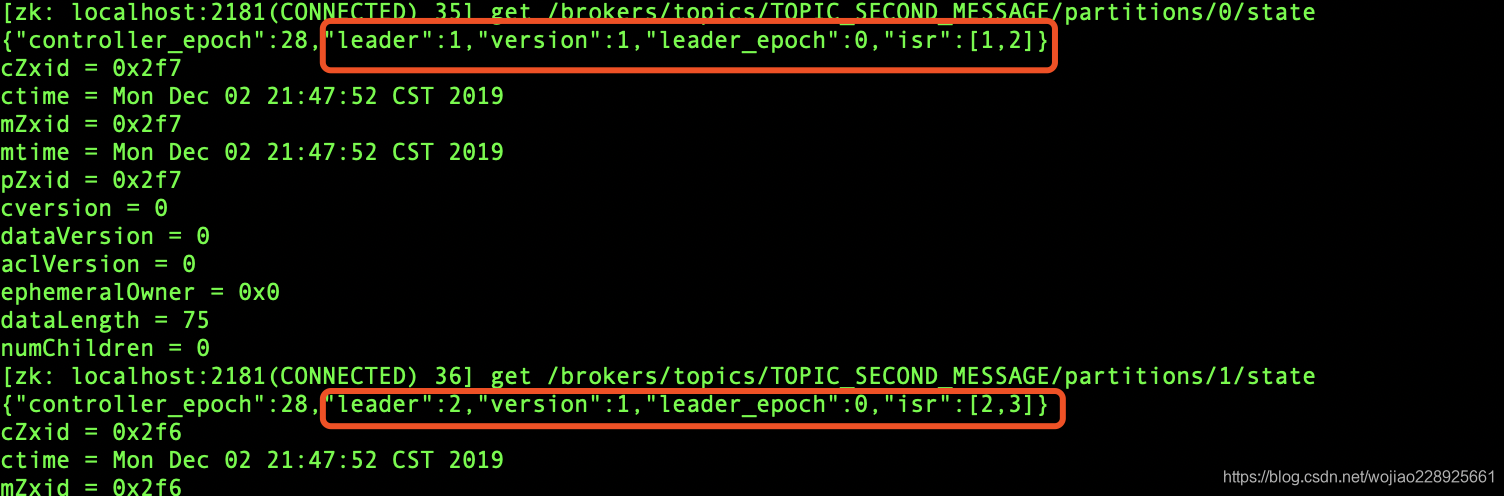
下图是3台kafka集群里面选出来的leader
6、kafka的事物
kafka从0.11版本开始引入了事物支持,事物可以保证kafka在Exactly Once 语义的语义的基础上,生产和消费可以跨分区和回话,要么全部成功,要么全部失败。
6.1、producer事物
为了实现跨分区会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,kafka引入了一个新的组件Transaction coordinator。producer'就是通过和Transaction coordinator交互获得Transaction ID对应的任务状态。transaction coordinator还负责将事务所有写入kafka的一个内部topic,这样即使整个服务器重启,由于事务状态得到保证,进行中的事务状态可以得到恢复,从而继续进行。
6.2、consumer事务
上述事务机制主要是从producer方面考虑,对于consumer而言,事务的保证就会相对较弱,尤其无法保证commit的信息被精确消费。这是由于consumer可以通过offset访问任意信息,而且不同的segment file生命周期不同,同一个事务的消息可能会出现重启后被删除的情况。
7、kafka API
7.1、kafka消息发送流程
kafka的producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程-main线程和sender线程,以及一个线程共享变量-recordAccumulator。main线程将消息发送给RecordAccumulator,sender线程不断从RecordAccumulotor中拉取消息发送到kafka broker
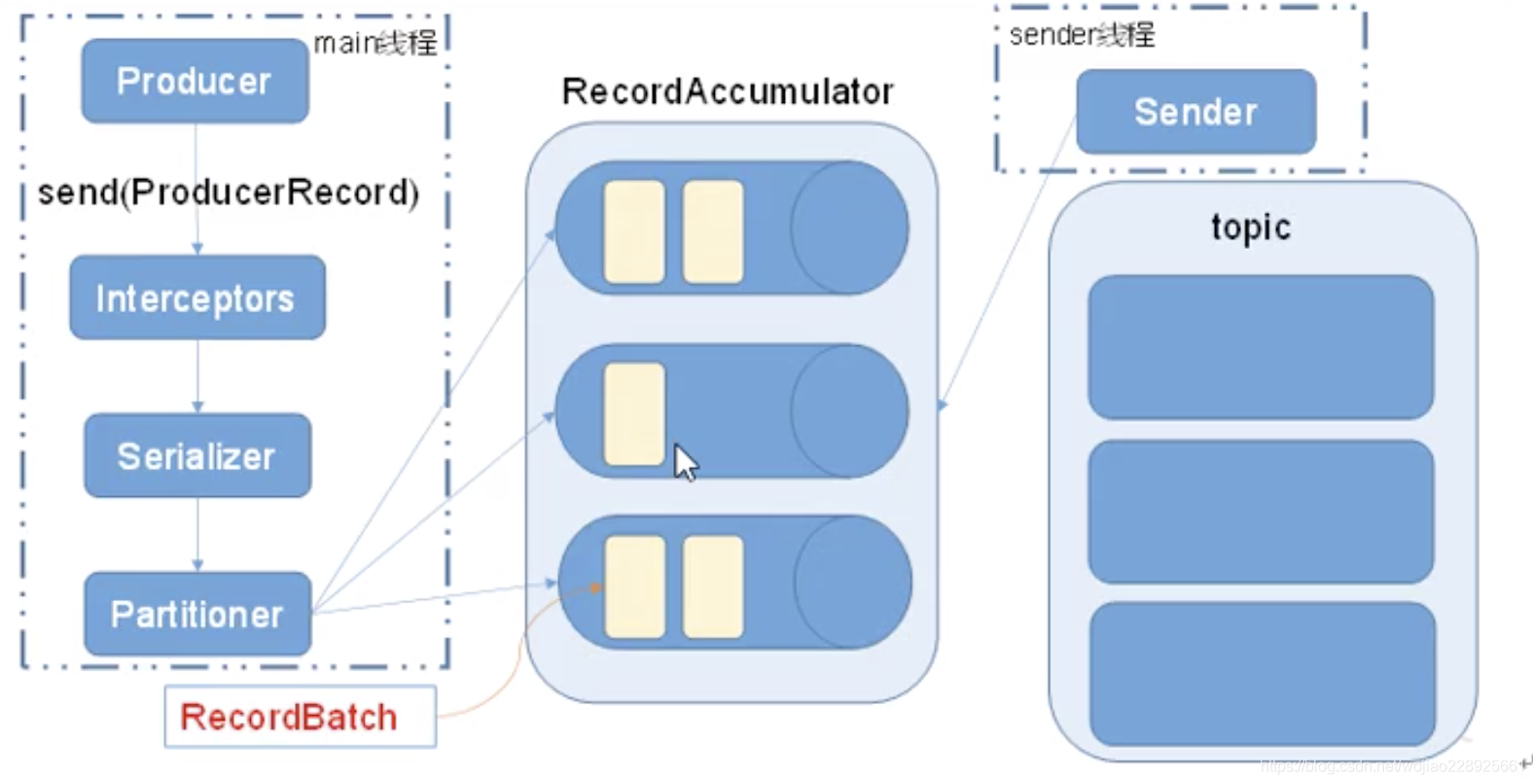
相关参数:
- batch.size:只有数据积累到batch.size之后,sender才会发送数据。
- linger.ms:如果数据迟迟未打到batch.size等待linger.time之后就会发送数据。
Interceptors:拦截器
Serializer:序列化
Partitioner:分区 ,自己写一个
源码:org.apache.kafka.clients.producer.KafkaProducer
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
// 1、拦截器
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
// 序列化
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 分区规则
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
.....
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, tp, e);
throw e;
}
}同步发送:(有序)用feture的get方法来阻塞主线程来达到同步的效果
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。
由于send方法返回的是一个Future对象,根据Future对象的特点,我们也可以实现同步发送的效果,只需在调用Future对象的get方法即可
如何重新消费数据?spring.kafka.consumer.auto-offset-reset
第一种方案:换组,把offset参数auto.offset.reset设置为earliest(最早的offset,由于数据只保留7天的)参数就可以了。
为什么要换组:是因为我们原来的那个组已经消费了,它的offset是不能在修改了,只能建一个新组才能从开始消费数据(消费保留下来的数据,kafka默认只保留7天的数据)。
auto.offset.reset有两个值:
- earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费,或者没有有效的offset时,设置从头开始消费
- latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
当设置成earliest时:(新加一个组,KAFKA_GROUP_ID_THIRD)
原来的组test-hello-group是消费完的,拉去消费的offset:
TOPIC_SECOND_MESSAGE-0 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 1 rack: null), epoch=1}
KAFKA_GROUP_ID_THIRD:这个会重头消费一遍
[Consumer clientId=consumer-3, groupId=test-hello-group] Setting offset for partition TOPIC_SECOND_MESSAGE-0 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 1 rack: null), epoch=1}}
[Consumer clientId=consumer-2, groupId=test-hello-group] Setting offset for partition TOPIC_FIRST_MESSAGE-0 to the committed offset FetchPosition{offset=34, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9093 (id: 2 rack: null), epoch=1}}
[Consumer clientId=consumer-3, groupId=test-hello-group] Setting offset for partition TOPIC_SECOND_MESSAGE-1 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9093 (id: 2 rack: null), epoch=3}}
[Consumer clientId=consumer-1, groupId=KAFKA_GROUP_ID_THIRD] Successfully joined group with generation 1
[Consumer clientId=consumer-1, groupId=KAFKA_GROUP_ID_THIRD] Setting newly assigned partitions: TOPIC_SECOND_MESSAGE-0, TOPIC_SECOND_MESSAGE-1
[Consumer clientId=consumer-1, groupId=KAFKA_GROUP_ID_THIRD] Found no committed offset for partition TOPIC_SECOND_MESSAGE-0
[Consumer clientId=consumer-1, groupId=KAFKA_GROUP_ID_THIRD] Found no committed offset for partition TOPIC_SECOND_MESSAGE-1
[Consumer clientId=consumer-1, groupId=KAFKA_GROUP_ID_THIRD] Resetting offset for partition TOPIC_SECOND_MESSAGE-1 to offset 0.
[Consumer clientId=consumer-1, groupId=KAFKA_GROUP_ID_THIRD] Resetting offset for partition TOPIC_SECOND_MESSAGE-0 to offset 0.当设置成latest:(新加一个组KAFKA_GROUP_ID_FOURTH)
他不会重新消费,只会拉去现在消费的offset,
[Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Resetting offset for partition TOPIC_SECOND_MESSAGE-0 to offset 6
2019-12-03 17:40:57.320 INFO 65835 --- [ntainer#3-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=KAFKA_GROUP_ID_THIRD] Setting offset for partition TOPIC_SECOND_MESSAGE-0 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 1 rack: null), epoch=1}}
2019-12-03 17:40:57.320 INFO 65835 --- [ntainer#2-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-1, groupId=test-hello-group] Setting offset for partition TOPIC_SECOND_MESSAGE-0 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 1 rack: null), epoch=1}}
2019-12-03 17:40:57.321 INFO 65835 --- [ restartedMain] o.a.kafka.common.utils.AppInfoParser : Kafka version: 2.3.1
2019-12-03 17:40:57.321 INFO 65835 --- [ntainer#2-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-1, groupId=test-hello-group] Setting offset for partition TOPIC_SECOND_MESSAGE-1 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9093 (id: 2 rack: null), epoch=3}}
2019-12-03 17:40:57.321 INFO 65835 --- [ restartedMain] o.a.kafka.common.utils.AppInfoParser : Kafka commitId: 18a913733fb71c01
2019-12-03 17:40:57.321 INFO 65835 --- [ntainer#3-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=KAFKA_GROUP_ID_THIRD] Setting offset for partition TOPIC_SECOND_MESSAGE-1 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=localhost:9093 (id: 2 rack: null), epoch=3}}
2019-12-03 17:40:57.321 INFO 65835 --- [ restartedMain] o.a.kafka.common.utils.AppInfoParser : Kafka startTimeMs: 1575366057321
2019-12-03 17:40:57.321 INFO 65835 --- [ restartedMain] o.a.k.clients.consumer.KafkaConsumer : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Subscribed to topic(s): TOPIC_SECOND_MESSAGE
2019-12-03 17:40:57.321 INFO 65835 --- [ restartedMain] o.s.s.c.ThreadPoolTaskScheduler : Initializing ExecutorService
2019-12-03 17:40:57.327 INFO 65835 --- [ntainer#1-0-C-1] org.apache.kafka.clients.Metadata : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Cluster ID: NYQYLPj4SVeaxs0_8Xgo6g
2019-12-03 17:40:57.328 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Discovered group coordinator localhost:9092 (id: 2147483646 rack: null)
2019-12-03 17:40:57.328 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Revoking previously assigned partitions []
2019-12-03 17:40:57.328 INFO 65835 --- [ntainer#1-0-C-1] o.s.k.l.KafkaMessageListenerContainer : KAFKA_GROUP_ID_FOURTH: partitions revoked: []
2019-12-03 17:40:57.328 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] (Re-)joining group
2019-12-03 17:40:57.340 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Successfully joined group with generation 1
2019-12-03 17:40:57.341 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Setting newly assigned partitions: TOPIC_SECOND_MESSAGE-0, TOPIC_SECOND_MESSAGE-1
2019-12-03 17:40:57.342 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Found no committed offset for partition TOPIC_SECOND_MESSAGE-0
2019-12-03 17:40:57.342 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Found no committed offset for partition TOPIC_SECOND_MESSAGE-1
2019-12-03 17:40:57.352 INFO 65835 --- [ restartedMain] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2019-12-03 17:40:57.353 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.SubscriptionState : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Resetting offset for partition TOPIC_SECOND_MESSAGE-0 to offset 6.
2019-12-03 17:40:57.353 INFO 65835 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.SubscriptionState : [Consumer clientId=consumer-4, groupId=KAFKA_GROUP_ID_FOURTH] Resetting offset for partition TOPIC_SECOND_MESSAGE-1 to offset 6.
2019-12-03 17:40:57.354 INFO 65835 --- [ntainer#1-0-C-1] o.s.k.l.KafkaMessageListenerContainer : KAFKA_GROUP_ID_FOURTH: partitions assigned: [TOPIC_SECOND_MESSAGE-0, TOPIC_SECOND_MESSAGE-1]
消费者没有设置自动提交消费信息会出现什么情况
参数:spring.kafka.consumer.enable-auto-commit
- 1、当消费者把自动提交消费消息设置成false:当消费者那个线程会一直拉取数据,只有在第一次的时候才会从kafka那获取消费的offset(0.9版本的kafka把消费记录保存在kafka服务器上,以前保存在zk上),之后在线程不重启的情况下,都不会在去获取消费的offset,也不会跟新消费的offset到kafka上,下次在启动在重新消费一次。
- 2、当消费者把自动提交消费消息设置成true:消费了,之后就会提交offset到kafka。
手动提交offset
虽然自动提交offset十分简介便利,但由于其实基于时间提交的。开发人员难以把握offset提交的时机,因此kafka还提供了手动提交的offset的api。
手动我提交offset的方法有两种,分别是commitSync(同步提交)和commitAsync(异步提交);两者的相同是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
自定义存储offset:
kafka0.9版本之前,offset储存在zookeeper,0.9版本以及之后,默认将存储在kafka的一个内置的topic中。除此之外,kafka还可以选择自定义存储的offset。
offset的维护是相当于繁琐的,因此需要考虑到消费者的rebalace。
当有新的消费者加入消费者组,已有的消费者推出消费者组成或者所订阅的主题的分区丰盛变化,就会触发到分区的重新分配,重新分配的过程叫做rebalance
消费者发生rebalace之后,每个消费者消费的分区就会变化。因此消费者要首先获取自己被重新分配的分区,并且定位到每个分区最近提交的offset位置继续消费。要实现自定义的offset,需要借助ConsumerRebalaceListener;
自定义拦截器Interceptor
拦截器原理:
producer拦截器(interceptor)是在kafka0.10版本引入的,主要用于实现clients端的定制化控制逻辑。
对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截器链(interceptor chain)。interceptor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,定义的方法包含:
下面就是实现拦截器的方式:
@Component
public class KafkaProducerInterceptor implements ProducerInterceptor {
@Override
public ProducerRecord onSend(ProducerRecord record) {
System.out.println("-----KafkaProducerInterceptor---->拦截器record"+ JSON.toJSONString(record));
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}1、configure(Map<String, ?> configs)
获取配置的信息和初始化数据时调用
2、close()
关闭interceptor,主要用于执行一些资源清理工作
3、onAcknowledgement(RecordMetadata metadata, Exception exception)
该方法会在消息从RecordAccumulator成功发送到kafka broker之后,或者在发送过程中失败调用。并且通常都是在producer回调逻辑触发之前,onAcknowledgement运行在producer的io线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率。
4、ProducerRecord onSend(ProducerRecord record)
该方法封装进kafkaProducer.send方法中,即它运行在用户主线程中。producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属但topic和分区,否则会影响目标分区的计算。
如前所述,interceptor可能被运行在多个线程中,因此在具体实现时需要用户自行确保线程安全。另外倘若指定了多个interceptor,则producer将按照指定顺序调用它们,并仅仅是捕获每个interceptor可能抛出的异常记录到日志中而非在向上传递。这在使用过程中要特别注意。
Kafka的监控:
eagle安装,需要的时候在进行查询。
很好的,可以监控消费的情况,消费失败,重试次数等等
kafka压力测试
kafka官方自带压力测试脚本(kafka-consumer-perf-test.sh、kafka-producer-perf-test.sh)
kafka压力测试时,可以查看那个地方出现了瓶颈(cpu,内存,网络IO)。一般都是网络IO达到瓶颈
kafka的机器数量
- kafka机器数量=2*(峰值生产速度*副本数/100)+1
kafka的日志保存时间
- 168h=7天,这个是可以修改的
kafka消息数据积压,kafka消费能力不足怎么处理?
- 1、如果是kafka消费能力不足,则可以考虑topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
- 2、如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。max.poll.records=500(默认拉取的值)
下面是一些问题
1、kafka中的ISR(InSyncRepli)、OSR(OutSyncRepli)、AR(AllRepli)代表什么?
- AR=OSR+ISR
2、Kafka中的HW、LEO等代表什么?
- HW:highwater,代表的是kafka集群里面最小的offset的值,也代表了消费者能消费的最大值offset
- LEO:log end offset每个kafka的broker的最大offset
3、kafka中是怎么体现消息顺序性的?
- 分区内有序
4、kafka中分区器,序列化器,拦截器是否了解?它们之间的处理顺序是什么?
- 首先执行的是拦截器-》序列化器-》分区器
5、kafka生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
是两个线程来处理的,一个是main线程,另外一个是send线程。
6、“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?
- 正确。
7、消费者提交位移时提交的是当前消费者的最新消息的offset还是offset+1?
- offset+1
8、有那些情形会造成重复消费
- 先处理数据,后提交offset
9、那些情景会造成消息漏消费?
- 先提交offset,后处理数据
10、当你使用kafka-topic.sh 创建(删除)了一个topic之后,kafka背后会执行什么逻辑?
- 10.1、会在zookeeper中的/brokers/topics节点下创建一个新的topic节点,如:/brokers/topics/one
- 10.2、触发controller的监听程序
- 10.3、kafka controller负责topic的创建工作,并更新metadata cache
11、topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
- 可以增加
12、topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
- 不可以减少,因为老的数据没有办法处理
13、kafka又内部的topic吗?如果有是什么?有什么作用?
- 有,__consumer_offset,给普通的消费者来存储消费的offset
14、kafka分区分配的概念
- range这个是按照主题来分的,这个是默认的,它是分配给订阅过这个topic的消费组来消费
- roundRabin是按照组来分的,轮询的分配到不同的组
15、简述kafka的日志目录结构
- topic--》多个protation-》segment->.log文件(存储数据的)和.index文件
- 首先我们找到index文件,通过二分查找法找到具体log文件里面的偏移量offset
16、聊一聊kafka controller的作用?
17、kafka中有些地方需要选举?这些地方的选举策略有那些?
- 17.1、kafka的controller的选举,也就是kafka集群服务器的leader,选举方式:抢资源,谁抢到就是谁的
- 17.2、kafka里面partation分区的leader选举,这个是在ISR里面进行选举的
18、失效副本是指什么?有那些应对措施?
19、kafka的那些设计让它如此高的性能?
- 分布式的、顺序写磁盘、零拷贝

















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









