







推荐系统概述
个性化推荐系统需要依赖用户的行为数据,通过分析大量用户行为日志,个不同用户提供不同的个性化推荐。
(1)基于邻域的方法:
基于用户的协同过滤算法:这种算法给用户推荐和他兴趣相似而其他用户喜欢的物品。
基于物品的协同过滤算法。这种算法给用户推荐和他之前喜欢的物品相似的物品。
评测指标:召回率,覆盖率,新颖度等
新颖度:用推荐列表中物品的平均流行度度量推荐结果的新颖度。如果推荐的物品都很热门,说明新颖度很低。
(A) 基于用户的协同过滤算法
(a) 找到和目标用户兴趣相似的用户集合
(b) 找到这个集合中用户喜欢的,且目标没有听说过的物品推荐给目标用户。
用户相似度衡量指标:
Jaccard相似度: Wuv =( N(u)^N(v) )/ ( N(u)UN(v) )
即 两个用户的历史行为的交集/两个用户的并集
余弦相似度:Wuv = |(N(u)^N(v)| /(Math.Sqrt( N(u) N(v) ))
(B) 基于物品的协同过滤算法
基于物品的协同过滤算法并不是利用物品内容属性的相识度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为物品A和物品B具有很高的相似度是因为喜欢物品A的用户大部分也喜欢物品B。即好多人同时喜欢AB,说明AB具有很高的相似性。
基于物品的协同过滤与基于用户的协同过滤比较:
|
| 用户 | 物品 |
| 性能 | 适用于用户较少的场景 | 适用于物品较少的场景 |
| 领域 | 时效性强,用户个性化兴趣不太明显的区域 | 长尾物品丰富,用户个性化需求强烈的区域 |
| 实时性 | 用户有新行为,不一定造成推荐结果的立即变化 | 用户有新行为,一定会造成推荐结果的实时变化 |
| 冷启动 | 不能立即进行个性化推荐 | 新用户只要对一个物品产生行为,就可以推荐 |
| 推荐解释 | 解释性不强 | 比较信服 |
长尾分布:

举例来说,我们常用的汉字实际上不多,但因出现频次高,所以这些为数不多的汉字占据了上图广大的红区;绝大部分的汉字难得一用,它们就属于那长长的蓝尾。 Chris认为,只要存储和流通的渠道足够大,需求不旺或销量不佳的产品共同占据的市场份额就可以和那些数量不多的热卖品所占据的市场份额相匹敌甚至更大。
打破了原先的二八定律。
· 无物不销,无时不售!”—JimTreacher
· “一个小数乘以一个非常大的数字等于一个大数!”
· 长尾就是过去%80不值得一卖的东西。
(2)隐语义模型LFM
隐含语义分析技术都是采用基于用户行为统计的自动聚类
LFM模型通过如下公式计算用户u对物品i的兴趣:
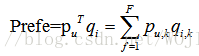
其中度量了用户u对兴趣和第K个隐类之间的关系
度量了物品i和第k个隐类之间的关系。
推荐系统的用户行为分为显性反馈与隐性反馈。LFM在显性反馈数据(评分数据)解决评分预测问题达到了很好的精度。如果是在隐性数据集上,即只有正样本(用户喜欢什么),没有负样本(用户对什么物品不感兴趣),这种情况下要进行采样,使得正负样本平衡。

R=P.Q
P,Q的初始化可以是等概率设置,也可以是随机设置。
r矩阵是user-item矩阵,矩阵值r(ij)表示的是user i 对item j的兴趣度,这正是我们要求的值。对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户U对物品I的兴趣度
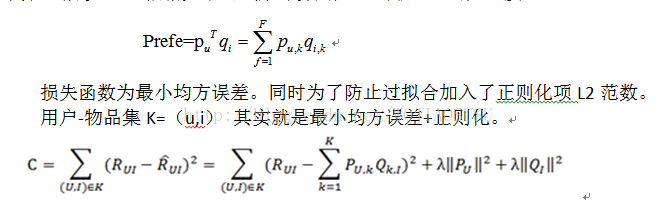
利用随机梯度下降法。负梯度方向。固定步长。
LFM算法与基于邻域的算法的比较:
(1)LFM是基于机器学习的算法,基于邻域的方法是基于统计的方法,无学习过程。
(2)基于邻域的方法需维护一张离线的相关表,会占据很大的内存。而LFM则可以很好地节省计算的内存,对于用户数很大的数据量来说较合适。
(3)总体来说,二者的时间复杂度没有质的区别。
(4)基于邻域的算法可较好的实现实时性。LFM不能在线实时推荐。
(5)ItemCF支持很好的推荐解释,而LFM无法提供。
(3)LDA主题模型
首先介绍主题模型(TopicModel)的基本内容。
主题模型是一种生成式模型,而且是通过主题来生成的。就是说,我们认为一篇文档的每个词都是通过以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语这样一个过程得到的。
何谓“主题”呢?其含义就是诸如一篇文章、一段话、一个句子所表达的中心思想,只不过不同的是,从统计模型的角度来说,我们是用一个特定的词频分布来刻画主题的,不同主题的词相同,但是词频不同。一篇文档一般有多个主题,这样,我们就可以认为,一篇文档是有多个主题来生成的。
举例:如果我们要生成一篇文档,它里面的每个词语出现的概率为:
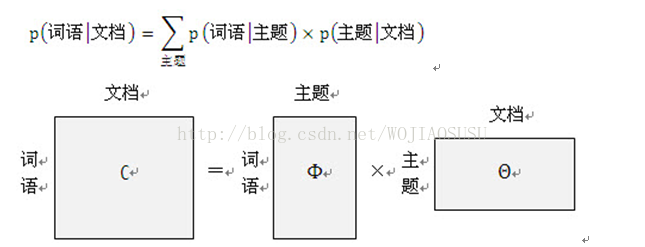
其中”文档-词语”矩阵表示每个文档中每个单词的词频,即出现的概率;”主题-词语”矩阵表示每个主题中每个单词的出现概率;”文档-主题”矩阵表示每个文档中每个主题出现的概率。
LDA两种含义:(1)线性判别分析。(2)概率主题模型:隐含狄利克雷分布。
LDA是典型的词袋模型,即一篇文档是由词语构成的,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中的每个主题都由其中的一个词组成。
表面上理解LDA比较简单,无非就是:当看到一篇文章后,我们往往喜欢推测这篇文章是如何生成的,我们可能会认为某个作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。
在LDA模型中一篇文档生成的方式如下:
(1)从狄利克雷分布中取样生成文档i的主题分布 。
(2)从主题的多项式分布 中取样生成文档i第j个词的主题 。
(3)从狄利克雷分布 中取样生成主题 的词语分布 。
(4)从词语的多项式分布 中采样最终生成词语。
LDA要素:一个函数:gamma函数,两个分布:beta分布、Dirichlet分布,一个模型:LDA(文档-主题,主题-词语),一个采样:Gibbs采样”。
冷启动问题:
主要分为三类:
(1) 用户冷启动:解决如何给新用户做个性化推荐的问题。
(2) 物品冷启动:解决如何将新物品推荐给用户的问题。
(3) 系统冷启动:解决如何在新一个新开发的网站上进行推荐。
解决方法:
(1) 利用用户注册信息:人口统计学特征,用户兴趣的描述等
(2) 物品冷启动:LDA主题模型,文档,话题、词语
(3) 发挥专家的作用。














 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









