




 本文深入探讨Redis缓存的设计原理,包括缓存带来的性能提升与潜在成本,如数据不一致性和增加的代码维护及运维成本。文章详细分析了内存溢出和过期策略,以及如何在应用程序中实现缓存更新,最后讨论了缓存粒度的选择及其对性能的影响。
本文深入探讨Redis缓存的设计原理,包括缓存带来的性能提升与潜在成本,如数据不一致性和增加的代码维护及运维成本。文章详细分析了内存溢出和过期策略,以及如何在应用程序中实现缓存更新,最后讨论了缓存粒度的选择及其对性能的影响。
Redis缓存设计
一、缓存的收益与成本
1.1 收益
-
加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),内存读写的速度远远高于磁盘I/O。通过缓存的使用可以有效地加速读写,优化用户体验。
-
降低后端负载:帮助后端减少访问量(Mysql设置有最大连接数,如果大量的访问同时达到数据库,而磁盘I/O的速度又很慢,很容易造成最大连接数被使用完,但Redis 理论最大)和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
1.2 成本
-
数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
-
代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
-
运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
1.3 使用场景
-
开销大的复杂计算:以MySQL为例子,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
-
加速请求响应:即使查询单条后端数据足够快,那么依然可以使用缓存,以Redis为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间
二、缓存更新策略
2.1 内存溢出淘汰策略
思考:在生产环境的 redis 经常会丢掉一些数据,写进去了,过一会儿可能就没了。是什么原因?
Redis 缓存通常都是全内存,内存是很宝贵而且是有限的,磁盘是廉价而且是大量的。可能一台机器就几十个 G 的内存,但是可以有几个 T 的硬盘空间。Redis 主要是基于内存来进行高性能、高并发的读写操作。那既然内存是有限,比如 redis 就只能用 10G,你要是往里面写了 20G 的数据,会咋办?当然会干掉 10G 的数据,然后就保留 10G 的数据了。那干掉哪些数据?保留哪些数据?当然是干掉不常用的数据,保留常用的数据了。数据明明过期了,怎么还占用着内存?这是由 redis 的过期策略来决定。
在Redis中,当所用内存达到maxmemory上限(used_memory>maxmemory)时会触发相应的溢出控制策略。具体策略受maxmemory-policy参数控制。
Redis支持6种策略:
- noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(error)OOM command not allowed when used memory,此时Redis只响应读操作
- volatile-lru:根据LRU算法删除设置了超时属性(expire)的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略
- volatile-random:随机删除过期键,直到腾出足够空间为止
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止
- allkeys-random:随机删除所有键,直到腾出足够空间为止(不推荐)
- volatile-ttl:根据键值对象的ttl(剩余时间(time to live,TTL) )属性,删除最近将要过期数据。如果没有,回退到noeviction策略
LRU :Least Recently Used ,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
内存溢出控制策略可以采用config set maxmemory-policy{policy}动态配置。写命令导致当内存溢出时会频繁执行回收内存成本很高,在主从复制架构中,回收内存操作对应的删除命令会同步到从节点来,来保障主从节点数据一致性,从而导致写放大的问题。
2.2 过期策略
Redis 服务端采用的 过期策略是 : 惰性删除 + 定期删除
惰性删除:
Redis的每个库都有一个过期字典,过期字典中保存所有key的过期时间。当客户端读取一个key时会先到过期字典内查询key是否已经过期,如果key已经超过,会执行删除操作并返回空。这种策略是出于节省CPU成本考虑,但是单独用这种方式存在内存泄露的问题,当过期键一直没有访问将无法得到及时删除,从而导致内存不能及时释放。
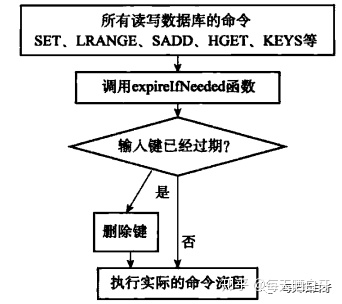
定时删除:
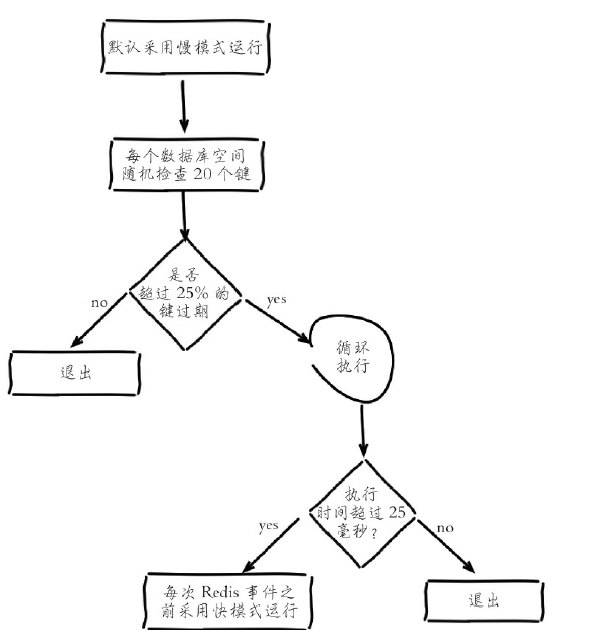
Redis内部维护一个定时任务,默认每秒运行10次过期扫描(通过 redis.conf 中通过 hz 配置 修改运行次数),扫描并不是遍历过期字典中的所有键,而是采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键:
- 从过期字典中随机取出 20 个键
- 删除这 20 个键中过期的键
- 如果过期键的比例超过 25% ,重复步骤 1 和 2
为了保证扫描不会出现循环过度,一直在执行定时删除定时任务无法对外提供服务,导致线程卡死现象,还增加了扫描时间的上限,默认是 25 毫秒(即默认在慢模式下,25毫秒还未执行完,切换为块模式,模式下超时时间为1毫秒且2秒内只能运行1次,当慢模式执行完毕正常退出,会重新切回快模式)
三、应用方更新
- 应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 先删除缓存,再更新数据库:这个操作有一个比较大的问题,更新数据的请求在对缓存删除完之后,又收到一个读请求,这个时候由于缓存被删除所以直接会读库,读操作的数据是老的并且会被加载进入缓存当中,后续读请求全部访问的老数据。
- 先更新数据库,再删除缓存(推荐)为什么不是写完数据库后更新缓存?主要是怕两个并发的写操作导致脏数据。
四、缓存粒度
1 通用性
缓存全部数据比部分数据更加通用,但从实际经验看,很长时间内应用只需要几个重要的属性。
2 占用空间
缓存全部数据要比部分数据占用更多的空间,存在以下问题:
- 全部数据会造成内存的浪费。
- 全部数据可能每次传输产生的网络流量会比较大,耗时相对较大,在极端情况下会阻塞网络。
- 全部数据的序列化和反序列化的CPU开销更大。
3 代码维护
全部数据的优势更加明显,而部分数据一旦要加新字段需要修改业务代码,而且修改后通常还需要刷新缓存数据。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









