







1.含义
线性回归是一种以线性模型来建立因变量与自变量关系的方法,通常分为一元线性回归和多元线性回归。线性回归模型根据定数据集D= {(x1, y1), (x2,y3),…,(xm,ym)},其中xi(xi1; xi2. . . ; xid(d个维度)), yi∈R"线性回归"(linear regression)试图学得一个线性模型以尽可能准确地预测连续型实值输出标记.
2.一般形式
f(x)=ω1x1+ω2x2+ω3x3+…+ωdxd+b
矩阵形式
f(x)=ωTx+b
ω直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性
3.误差分析

上面的红点表示预测值,我们都想让预测值尽可能的去靠近真实值。
线性回归有个很重要的点,假设误差ℇ(i)是独立并且具有相同的分布,并服从均值为0方差为⍬2的正态分布(又叫高斯分布)举个例子 小米和小明都去了银行贷款 独立:小米和小明贷多少钱与对方并没有任何关系,同分布:小米和小明都去了同一家银行。
常用误差平方和来表示线性回归问题的损失函数

4.一元线性回归
当属性只有一个时,学习得到的模型可以简化成f(xi)=ωxi+b,实际上表示的是一条直线,我们要让这条直线尽可能地拟合每个数据点,将ω和b求出就可以得到模型了。但ω和b可以有很多组,我们希望得到比较好的一组ω和b使得预测效果更好,通过衡量预测的准确性,即衡量 f(xi)于真实值 yi之间的差异可以使用最小二乘法来求,将它们的均方误差最小化。
即(ω,b)= argmin∑mi=1 ( f(xi) - yi )2=argmin∑mi=1 (ωxi+b - yi )2
要最小化,分别对ω和b进行求偏导,凸函数极值点处取到最小值,令偏导都等于0,求得ω和b的最优解
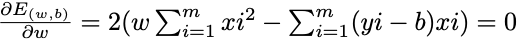
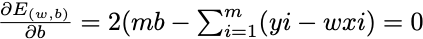
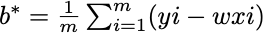
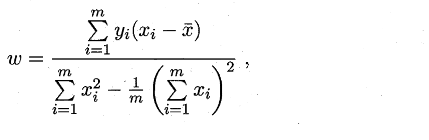
5.多元线性回归
实际生活当中一元线性回归用的不多,没有太大的价值,因为能够影响预测值的属性往往不止一个,可能几十个甚至上百的。ω=(ω1, ω2, … , ωd),ω是一个d x 1的列向量。多元线性求解参数有两种方法,一种是梯度下降,另一种利用最小二乘法来对ω和b进行估计。这里使用最小二乘法利用矩阵进行求解,为了便于运算与表达将 f(x)=ωTx+b中的b收进ω中,变成了f(x)=ωTx,此时ω=(ω1, ω2, … , ωd,ωd+1),其中ωd+1表示b,相应的在x后面添加一个维度,值都为1,下面进行推导:
首先,把数据集D表示成一个m x (d + 1)大小的矩阵X,每一行代表一个样本的特征,也便于建立模型时对数据的使用,Y表示真实值的一个m x 1的列向量Y=(y1, y2, y3,…, ym)
先看看这些要用到的变量

进行推导
1.实际上这里是对矩阵装置的变化过程,也可以直接利用线性代数转置的性质进行变化

2.对ω求偏导
L(ω) = ( ωT XT - YT )( X ω - Y)
= ωT XTX ω - ωT XTY - YT X Y + YT Y
因为ωT XTY 和YT X Y均表示一个一维的数,所以转置一样
L(ω) = ωT XTX ω - 2ωT XTY + YT Y

最终得到ω = (XTX)-1XTY,但这个公式有一定的局限性,当(XTX)不满秩时,有一个比较简单的情况,属性个数大于样本数时一定不满秩,就会得到多个ω ,它们都能使均方误差最小化.
这个时候可以采取什么办法?
- 增加样本数
- 剔除一些不重要的特征或共线性特征,进行降维
- 常见的做法是引入正则化(regularization)项
处理1和2往往治标不治本,而且数据也不能随随便便的增删,一般进行正则化处理。本质上是对权重W的约束,将某些无关紧要的特征的权重调小,该特征就越不能起决定作用,就可以让模型更专注于有决定性作用的那些特征。
6.简单的多元线性回归实现
导入模块
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
简单实现
class LinearReg():
def __init__(self):
self.coef = None
self.interception = None
self.theta = None
#模型
def fit(self,x_train,y_train):
b0 = np.ones((len(x_train),1))
x = np.column_stack((b0,x_train))#增加一个维度
x_T = x.T
self.theta = np.linalg.inv(x_T.dot(x)).dot(x_T).dot(y_train)
self.coef = self.theta[1:]
self.interception = self.theta[0]
#预测
def predict(self,x_test):
b0 = np.ones((len(x_test),1))
x = np.column_stack((b0,x_test))
pred = np.ones((len(x),1))
for i in range(len(x)):
sum = 0
for j in range(len(x[0])):
sum += x[i][j]*self.theta[j]
pred[i] = sum
return pred
#评分
def R_square_score(self,y,y_pred):
res = ((y_pred-y)**2).sum()/len(y_pred)
tot = ((y-y.mean(axis=0))**2).sum()/len(y_pred)
score_R = 1 - res/tot
return score_R
利用库里的boston数据建立模型
###引入数据###
load_data=datasets.load_boston()
data_x=load_data.data
data_y=load_data.target.reshape(len(load_data.target),1)
print(data_x.shape)
x_train,x_test,y_train,y_test = train_test_split(data_x,data_y,test_size=0.3)
#训练数据得到模型
model = LinearReg()
model.fit(x_train,y_train)#得到模型
print(model.coef)
print(model.interception)
test_pred = model.predict(x_test)
test_score = model.R_square_score(y_test,test_pred)
print('test_score:',test_score)
test_score: 0.7647573944406656
【初次尝试,有什么不对的欢迎指出】















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









