







目录
为什么要存在非递归的操作方式?
对于遍历一棵二叉树来说,明明已经有了递归遍历的方法了,方法也很好用,为什么要设计非递归的遍历方法呢?
因为递归是有缺陷的,倒不是说效率问题,如果程序是release版本,递归不需要压调试信息,建立栈帧的时间成本就没这么大,因此递归方式和非递归方式实际上在效率上差别不大,主要的缺陷是:因为一个线程的栈空间是比较小的,所以当递归的深度太深就会导致栈溢出,程序崩溃。尤其是在debug模式下,因为要压调试信息,所以更容易栈溢出,当递归1000次时还没问题,但10000次就会溢出导致程序崩溃,如下图。
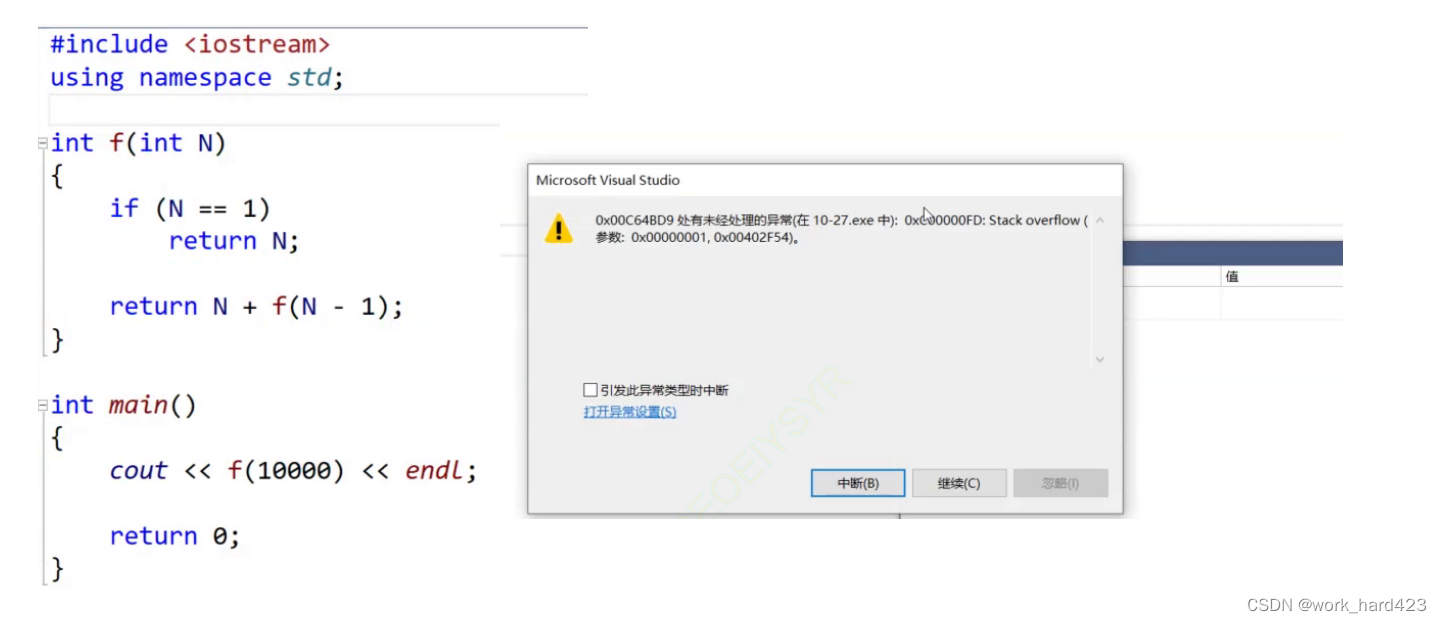
总结一下,可以看到明明递归的逻辑没问题,但当递归的次数很多时就会出现问题,所以也能看出:对于树形结构,不管是要遍历它,还是要对它进行其他操作,我们不光要掌握递归写法,还必须掌握非递归写法。
非递归的操作方式是什么?
非递归的操作方式就是在用迭代(循环)的方式模拟递归的过程。
有人会说:那非递归的写法就不会栈溢出了嘛?
答案:不会,因为循环本身是没有空间复杂度的,空间复杂度为O(1)。
二叉树的前序遍历(非递归版本)
先给出代码,然后用代码结合实际案例进行讲解。
代码如下。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void preorderTraversal(TreeNode* root)
{
stack<TreeNode*>s;
while(root!=nullptr||s.empty()!=true)
{
while(root!=nullptr)
{
cout<<root->val;
s.push(root);
root=root->left;
}
root=s.top();
s.pop();
root=root->right;
}
return v;
}
};前面也说过,非递归就是用循环写法模拟递归的过程,接下来我们看看实际案例。
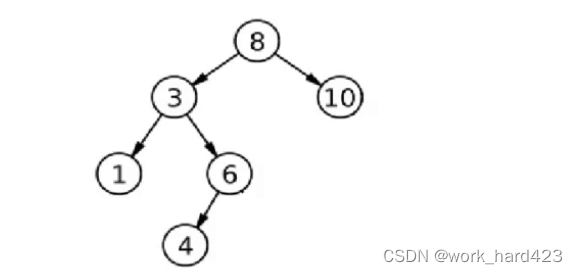
前序遍历的顺序是【根,左子树,右子树】,因此对于上面这样一棵树,前序遍历首先肯定会遍历到8、3、1,nullptr,按照递归算法,此时遍历到空就会先return到节点1,然后试图往1的右子树递归,也就是说递归算法是能通过return找到1的,找到1后自然能找到1的右子树,但迭代算法循环遍历到1的左孩子nullptr后就找不到1了,为了解决这个问题,我们可以使用stack这个数据结构,每向左访问完一个节点,只要该节点不是nullptr,就将它入栈,比如向左访问8、3、1后,1最后入栈,所以1就是栈顶元素,遍历到1的左孩子nullptr后,因为该节点是nullptr,所以不入栈,并且因为向左遍历到nullptr了,无法继续向左或者向右遍历,此时就要回退,需要回退到哪呢?此时是向左遍历访问到nullptr,如果是向左遍历遇到nullptr,则需要回退到nullptr的父亲节点,然后访问父亲节点的右子树,所以当前情景就是回退到节点1,然后访问1的右子树。那么如何找到nullptr的父亲节点1呢?因为从节点1向左遍历前,我们把1入栈了,所以栈顶元素就是1,top一下就能找到1了,然后pop()把1从栈里移除,找到1后自然能找到1的右子树,此时向右遍历访问1的右子树时又遍历到nullptr了,无法继续向左或者向右遍历,此时就要回退,需要回退到哪呢?此时是向右遍历访问到nullptr,如果是向右遍历访问到nullptr,则要分情况,但记住,不管是哪种情况,只要向右遍历访问到nullptr,则需要会回退到栈顶元素对应的节点,在当前情景下,因为栈内的节点1已经被移除,所以当前栈顶元素是3,所以需要回退到3,然后访问3的右子树。前面说要分情况,有哪几种情况呢?第一:如果nullptr的父亲节点是左孩子,则回退到nullptr父亲节点的父亲节点;第二:如果nullptr的父亲节点是右孩子,则回退到nullptr父亲节点的父亲节点的父亲节点;第三:如果nullptr的父亲节点既不是左孩子,也不是右孩子,则表明nullptr的父亲节点是根节点,因为是从根节点开始向右遍历时遇到nullptr,即根节点没有右子树,所以不用再次回退,遍历直接结束。
流程的精髓就是:不管是哪个节点,每从一个节点开始向左遍历前,都把该节点入栈,为什么要入栈呢?你现在即将向左遍历访问左子树,但别忘了当你左子树访问结束后还需要向右访问当前节点的右子树,假如你每次从一个节点向左遍历前,都不把该节点入栈,那当你向左遍历访问完该节点的左子树后,你是无法知道该节点是谁的,也就无法从该节点开始向右遍历访问该节点的右子树了。结合本段可以得到一个结论:因为不管是哪个节点(空节点除外),都会向左遍历访问左子树,所以每个节点都会入栈,所以整棵树中的所有节点,在某个时期的都是栈顶元素。
从上面流程可以发现一个规律:不管是向左遍历还是向右遍历,只要且只有遍历到nullptr,才会需要回退。回退到哪呢?需要回退到目前的栈顶元素A对应的节点A,然后pop一次将栈顶元素A从栈里移除,然后root=root->right访问节点A的右子树。这个规律也说明了回退到某个节点的目的就是访问该节点的右子树,并且如果想访问某节点的右子树,必须在访问完该节点的左子树后先回退到该节点。
问题:如何判断一个节点root的右子树是否被访问过?
答案:如果栈里存在该root节点,则说明该root节点的右子树一定没有被访问过;反之如果不存在root节点,则说明root节点的右子树一定已经被访问完毕了或者正在被访问。
问题:凭什么得出上面这样的答案呢?
答案:因为上面规律说过:如果想访问某节点的右子树,则必须在访问完该节点的左子树后先回退到该节点,所以如果想访问root节点的右子树,则必须先把root节点的左子树访问完后回退到root节点。上面规律还说过:回退是只能回退到目前的栈顶元素对应的节点上的,所以所以证明了root节点一定是目前的栈顶元素。所以通过调用一次top()函数取栈顶元素就能找到该root节点,找到root节点后还会调用一次pop()函数把root节点从栈里移除,然后root=root->right访问root节点的右子树。问题就在于调用了一次pop()函数,因为访问root的右子树前,咱们会调用一次pop()函数把root从栈里移除,所以当栈中不存在root节点时,root节点的右子树一定已经被访问完毕或者正在被访问,反之,如果栈中还存在root节点,则说明从来没有回退到root节点上过,root的右子树一定没有被访问过。
理解完上文,我们又能得出一个结束遍历的条件:只要栈里还存在元素,说明还有节点的右子树没有被访问,遍历就不能结束;反之只要栈里的元素为空,则要么表示所有节点的右子树都已经被访问过了,此时需要结束遍历;要么表示正在访问根节点的右子树,只要根节点的右子树访问完毕,就需要结束遍历。那在【正在访问根节点的右子树】的情况下,怎么判断根节点的右子树访问完毕了呢?只要同时满足两个条件就表示根节点的右子树访问完毕了,第一:当栈里为空,第二:并且此时在根节点的右子树中遍历到了nullptr。为什么同时满足这两个条件就表示根节点的右子树被访问完毕了呢?答案:前面说过:“不管是向左遍历还是向右遍历,只要遍历到nullptr,则需要回退到栈顶元素对应的节点”。现在的情景是在根节点的右子树中遍历到了nullptr,所以需要回退,但因为此时栈里为空,没法再次回退了,所以就代表根节点的右子树访问完毕了。所以此时就需要结束遍历。
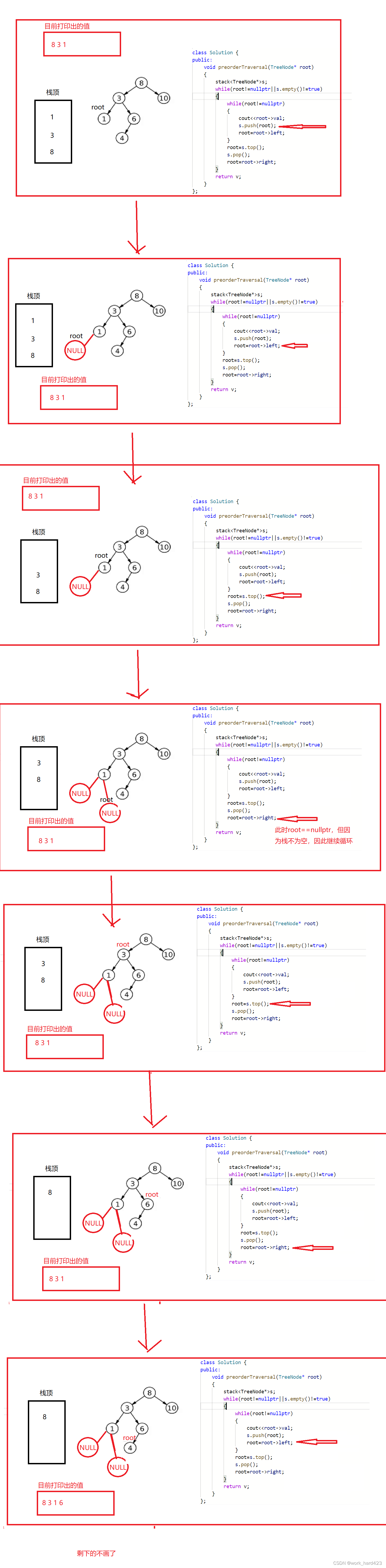
代码流程图如下。下图有个root指针,它的指向表示当前遍历到了哪个节点。
二叉树的中序遍历(非递归版本)
中序和前序的框架完全一致,只不过访问每个节点的时机和前序不同,所以前序遍历里总结的结论和规律,在中序遍历中同样适用。
上文中产生过一个结论:树中的每一个节点都会入栈,所以每一个节点都是某个时期的栈顶元素。而中序遍历就是需要在回退后,即top获取栈顶元素后就立刻访问栈顶元素。
代码如下。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void inorderTraversal(TreeNode* root) {
stack<TreeNode*>s;
while(s.empty()!=true||root!=nullptr)
{
while(root!=nullptr)
{
s.push(root);
root=root->left;
}
root=s.top();
s.pop();
cout<<root->val;
root=root->right;
}
}
};二叉树的后序遍历(非递归版本)
二叉树的后序遍历和【前序与中序】不太一样,所以上文中的部分规律与结论在这里是不适用的。
先看代码,然后结合实际案例对代码进行讲解。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void postorderTraversal(TreeNode* root)
{
stack<TreeNode*>s;
TreeNode*prev;
while(s.empty()!=true||root!=nullptr)
{
while(root!=nullptr)
{
s.push(root);
root=root->left;
}
root=s.top();
if(root->right==nullptr||root->right==prev)
{
cout<<root->val;
prev=root;
s.pop();
root=nullptr;
}
else
root=root->right;
}
return v;
}
};实际案例如下。
(后序遍历解释的不好,建议结合图看代码是怎么走的)
对于后序遍历,访问某节点的顺序是【该节点的左子树,该节点的右子树,该节点】,和前序遍历一样,每从一个节点开始向左遍历前,都把该节点入栈,所以上面这棵树的入栈顺序是8、3、1,从1开始向左遍历时,把1入栈后,遍历到了nullptr,所以就要回退,因为上文说过,不管是向左遍历还是向右遍历,只要遇到了nullptr,则需要回退,并且回退只能回退到栈顶元素,因为当前的栈顶元素是1,所以回退到1,在前序遍历中回退到栈顶元素1后会立刻把栈顶元素1从栈内移除,但后序遍历不能这样做,因为我们访问完1的右子树后还得访问1本身,访问1的右子树时,分两种情况,如果右子树为nullptr,右子树无需被访问,则可以直接访问1;如果1的右子树不为nullptr,那什么时候才能访问1呢?假设在遍历这棵树时,到目前为止最后被访问的节点叫prev,如果prev是1的右孩子,才能访问1,为什么呢?因为此时是后序遍历,1的右子树被访问结束后,才能访问1,而1的右子树被访问完毕的标志就是【上一个被访问的节点】是1的右孩子节点,所以prev是1的右孩子才能访问1。从这里也能看出如何判断一个节点的右子树是否被访问完毕:如果prev是该节点的右孩子,则右子树已经被访问过了,反之则没有被访问完毕,即可能还没有被访问过,也可能正在被访问。此时因为从1开始向右遍历遇到了nullptr,按照遇nullptr就回退的原则,我们在访问完1后,把栈顶元素更新后,也应该回退,回退到栈顶元素,此时栈顶元素被更新后为3,所以该访问3的右子树,剩下的逻辑相同,不再赘述。为什么不会发生这样的情况:回退到栈顶元素后又访问栈顶元素的左子树。因为上文说过,回退的目的就是访问栈顶元素的右子树。
这里的精髓就是如何判断一个节点的右子树被访问完毕了:假设在遍历这棵树时,到目前为止最后被访问的节点叫prev,如果某个节点的右孩子是prev,则代表这个节点的右子树被访问过了,因为是后序遍历,所以此时该访问这个节点本身了。















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









