







目录
set的模板参数(包含对Compare的终极无惑版本的解释)
关联式容器
在初阶阶段我们已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的
键值对pair,并且因为底层结构的特性(树形,哈希),所以在数据检索时比序列式容器效率更高。
键值对
上面说关联式容器里面存储的是<key, value>结构的键值对,那什么是键值对呢?
键值对:用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
SGI - STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};构造函数

第一个版本是默认构造;
第二个版本是拷贝构造,pair内部就两个成员,T1 first和T2 second,所以pair的拷贝构造就是调用T1类的拷贝构造去构造first,然后调用T2类的拷贝构造去构造second,又因为编译器自动生成的pair的拷贝构造都具备这些功能,所以如果我们要模拟实现pair类,拷贝构造都不用自己写。
第三个版本的示例如下图1。解释一下代码:在本例中,pair的first_type(即T1)被实例化成string,second_type(即T2)被实例化成int,“你好”是一个C语言字符串,但因为string类有下图2这样的一个单参数的通过C语言字符串构造string的构造函数,并且还没有被explicit修饰,所以“你好”这个C语言字符串被隐式转换成了一个string类的匿名对象,然后将该匿名对象赋值给了上图的a,常量1则是赋值给了b。


operator=

pair内部就两个成员,T1 first和T2 second,所以pair的operator=就是调用T1类的operator=去给first赋值,然后调用T2类的operator=去给second赋值。和拷贝构造一样,如果需要模拟实现pair类,pair的operator=都不用自己写。
relational operators (pair)

pair和【int或者string】这些类一样,也支持比较大小。
两个pair对象比较大小时,先比较first,哪个对象的first大,则哪个对象更大;如果first相同,再比较second,哪个对象的second大,则哪个对象更大;如果pair对象1的first和对象2的first相同,pair对象1的second和对象2的second也相同,则两个pair对象相等。
既然pair比较大小时是通过first和second,那first和second的类型T1和T2肯定都要支持operator>等等比较大小的函数,如果T1类或者T2类不支持这些函数,那T1和T2就不支持比较大小,导致通过T1和T2实例化出的pair类也无法比较大小。
make_pair函数(注意不是pair类的成员函数)

注意make_pair不是pair类的成员函数。
make_pair能够通过参数(x和y)推导【生成的临时pair对象】的类型,所以【通过make_pair生成临时pair对象】对比【通过pair<int,int>()生成临时对象】的优势就是前者不用写模板参数,更简洁,不用打这么多字。
示例如下。

有人可能会疑惑,pair类和make_pair函数明明在头文件utility中,为什么上图中没有包该头文件,也能使用make_pair函数生成临时的pair对象呢?答案:实际上是包了头文件的,只是包在了<map>头文件中,即<map>文件中有#include<utility>语句,毕竟map这棵树里的Node节点有一个pair<key,value>类的成员,pair类又在文件utility中,<map>文件当然要#include<utility>啦。从这里也能有一个感悟,使用某种东西一定要包头文件,可以间接包,也可以直接包。
关联式容器的种类
根据应用场景的不同,STL总共实现了两种不同结构的关联式容器:树型结构与哈希结构。树型结
构的关联式容器主要有四种:map、set、multimap、multiset。
这四种容器的共同点是:使用平衡搜索二叉树(即红黑树,注意不是AVL树)作为其底层结构,容器中的元素是一个有序的序列。接下来咱们对它们依次进行介绍。
set
简介
set底层是红黑树,红黑树又是平衡的搜索树,所以set具有BSTree的所有性质,比如天生就能排序,天生就能去重。
set与map / multimap不同,map / multimap中存储的是真正的键值对<key, value>,而set中只放value,所以set也是一个K模型的平衡二叉搜索树,对于这种模式下的二叉搜索树的应用场景,我们在<<二叉搜索树>>一文中讲解应用场景的部分已经进行过说明。同时我们要知道,虽然我们说set中只存了value,但实际上set在底层存放的是由<value, value>构成的键值对,否则set就不能被称之为关联式容器。
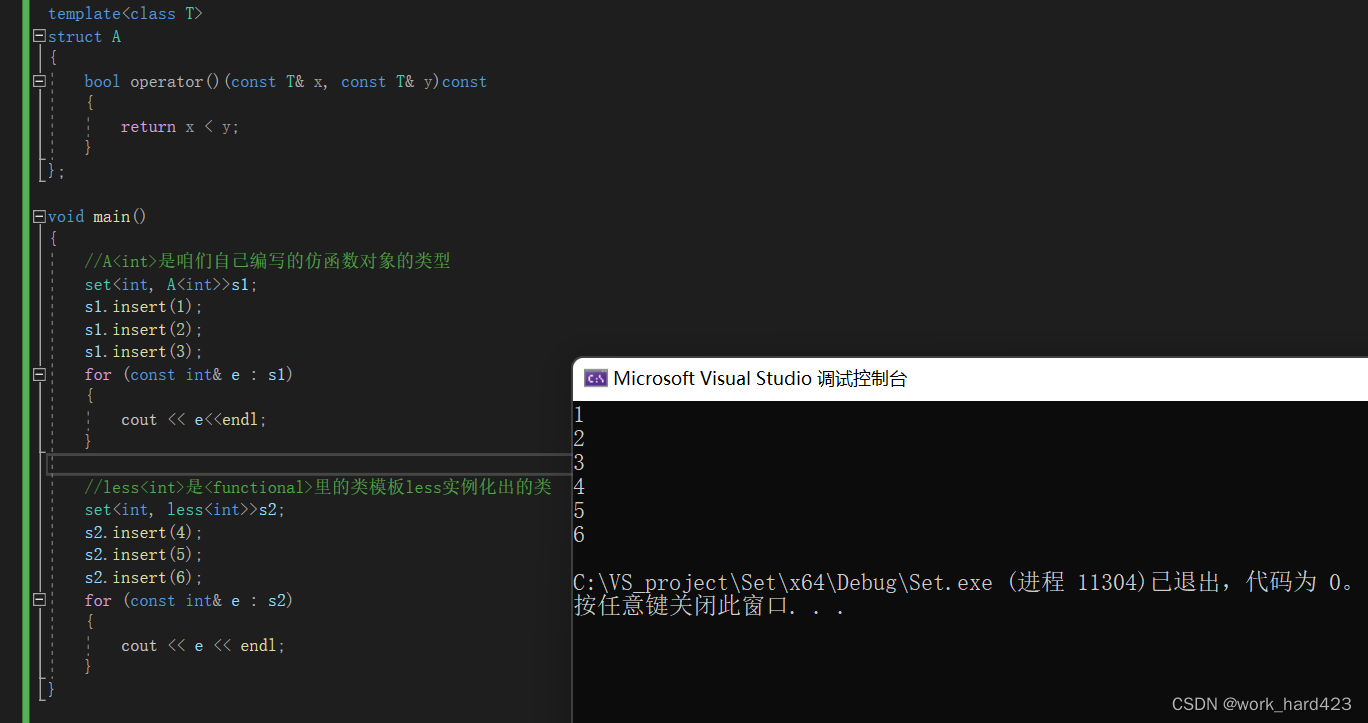
set的模板参数(包含对Compare的终极无惑版本的解释)

如上图,set也是一个类模板,咱们先来说说它的几个模板参数。
第一个类型模板参数T表示存储数据的类型;
分割线————
第二个类型模板参数Compare表示比较器的类型。因为set底层是一棵平衡搜索二叉树,搜索树的插入节点操作需要比较节点的元素大小,以此决定插入到哪个位置;搜索树的删除节点操作需要比较节点的元素大小,以此决定被删除的节点的子树被谁继承,所以Compare存在的意义就在于可以通过它比较节点的元素大小,比如在set的insert等函数中,我们就会定义Compare类的对象,然后通过Compare类的对象比较节点的元素的大小。
问题:有人会说,没有Compare这个模板参数时,只要T这个类支持operator>等这些比较大小的函数,即T类支持比较大小,那set<T>中的节点一样能通过节点的T类成员比较节点的大小,那在插入或者删除节点时就有判断依据了,那你搞个Compare不是多此一举吗?
答案:这里我想说的是:并不是多此一举,提供Compare最主要的原因是为了在需求变化时能灵活控制代码的逻辑,比如有Compare类的对象com,然后有T类对象x和y,现在插入节点时需要比较x和y的大小,判断新节点到底插入到某个节点的左子树还是右子树,如果使用com(x,y),那我可以控制让com(x,y)等价于x>y,也可以控制让com(x,y)等价于x<y,也就是说我能控制本行代码,控制让x和y中间的符号是>还是<,这样我们就能控制让set是一棵升序树还是一棵降序树,比如我们期望set不是一棵升序树,而是一棵降序树时,我们就可以传greater<T>类给Compare;反之如果传less<int>类给Compare,那set就是一棵升序树。而如果不提供模板参数Compare,那本行代码要么写死成x>y,那这个set就只能固定是一棵降序树了,要么写死成x<y,那这个set就只能固定是一棵升序树了。另一方面,通过Compare还能灵活控制该按照什么比较大小,让不同类型的比较规则也不同,比如让类A对象通过规则1比较大小,让类B对象通过规则2比较大小,而如果不提供Compare,则所有类型都只能用同一种比较规则去比较大小。举个例子,当T是Date*这样的指针类型时,STL的less<Date*>只能按照指针变量的值,即地址来比较大小,但假如我们期望按照指针被解引用后的值比较大小,此时less<Date*>就不够用了,我们就需要自己编写一个可调用对象去完成期望的功能。
————————————————
理论上我们是可以给Compare传任何可调用对象的类型的,比如函数的类型,函数指针的类型,或者是仿函数对象的类型。注意如果Compare的类型是函数的类型或者是函数指针的类型,则需要考虑如何给Compare类的对象赋值,一般是Compare类的对象作为set的某个成员函数的参数,然后靠使用者在调用该成员函数时给它传参;如果Compare的类型是仿函数对象的类型,则无需考虑给Compare类的对象赋值,因为该对象是通过自己的成员函数operator()完成比较大小的任务的。如下图是咱们模拟出的场景,不管Compare是哪种可调用对象的类型,Compare类的对象都可以完成比较大小的任务。

代码如下。
bool less1(const int& x, const int& y)
{
return x < y;
}
template<class T>
struct less2
{
//注意这里必须是const成员函数,因为myset的成员函数myinsert的参数const Compare&com被const修饰了,如果这里operator()不是const函数,则在myinsert内com(x,y)调用不了operator()
bool operator()(const T& x, const T& y)const
{
return x < y;
}
};
template<class T,class Compare>
struct myset
{
void myinsert(const T& val,const Compare&com=Compare())
{
cout<<com(val,10)<<endl;
//。。。
}
};
void main()
{
myset<int, bool(const int&, const int&)>s1;//传函数的类型给Compare
s1.myinsert(9, less1);//less1是函数,函数也是一种对象(可调用对象)或者叫变量,所以可以直接传less1函数这个变量给myinsert的参数const Compare&com,此时Compare的类型就是less1函数的类型
myset<int, bool(*)(const int&, const int&)>s2;//传函数指针的类型给Compare
s2.myinsert(10, less1);//函数名就是地址,所以这里的less1不作为函数,而是作为地址传给了myinsert的参数const Compare&com,此时的Compare是一个指针类型
myset<int, less2<int>>s3;//传仿函数对象的类型给Compare
s3.myinsert(11);//myinsert的第二个参数有缺省值,此时无需显示传
}
既然前面只是说:“在理论层面上可以传任何可调用对象的类型给Compare”,那就是说实际上不行咯?是的,在实际上,虽然函数也是一种可调用对象的类型,但是不可以传函数的类型给set的模板参数Compare,如下图1传函数的类型给Compare就会报错,为什么会这样呢?如下图2,双击错误信息会定位到key_comp()函数,key_compare这个类型是typedef出的Compare的别名,当我们传函数的类型给Compare时,key_compare就是一个函数的类型,那么key_comp()函数的返回值也就是一个函数,而在C++中,是不允许函数的返回值也是一个函数的,最多只能是函数指针、lambda表达式、或者是仿函数对象,所以这里给set的模板参数Compare传函数的类型时,报错就是因为有一个key_comp函数在捣乱,key_comp函数返回了一个函数,这就不符合C++规定了。


所以总结一下:对于STL的set来说,我们只能给Compare传仿函数对象的类型,函数指针的类型,不能传函数的类型。比如可以给Compare传头文件<functional>里的less<T>或者greater<T>类,即STL编写的仿函数对象的类型,也可以传咱们自己编写的仿函数对象的类型,如下图1所示,注意传咱们自己编写的仿函数对象的类型给set的Compare时,编写的成员函数operator()一定要是const成员函数,为什么呢?如下图2的红框处所示,当key_compare类即Compare类的对象comp被const修饰时,如果Compare类的成员函数operator()不是const成员函数,那comp(x,y)就调用不了operator()(x,y)了,因为const对象无法调用非const成员函数。
还可以给Compare传函数指针的类型,如下图2所示。最后说一下,如果传给set的可调用对象不支持比较大小,则虽然代码能编译通过,但也肯定会运行时出错的。


分割线————
第三个类型模板参数Alloc表示内存池对象的类型,学到空间配置器后再具体说明。
默认成员函数
构造函数(包含对initializer_list的说明)
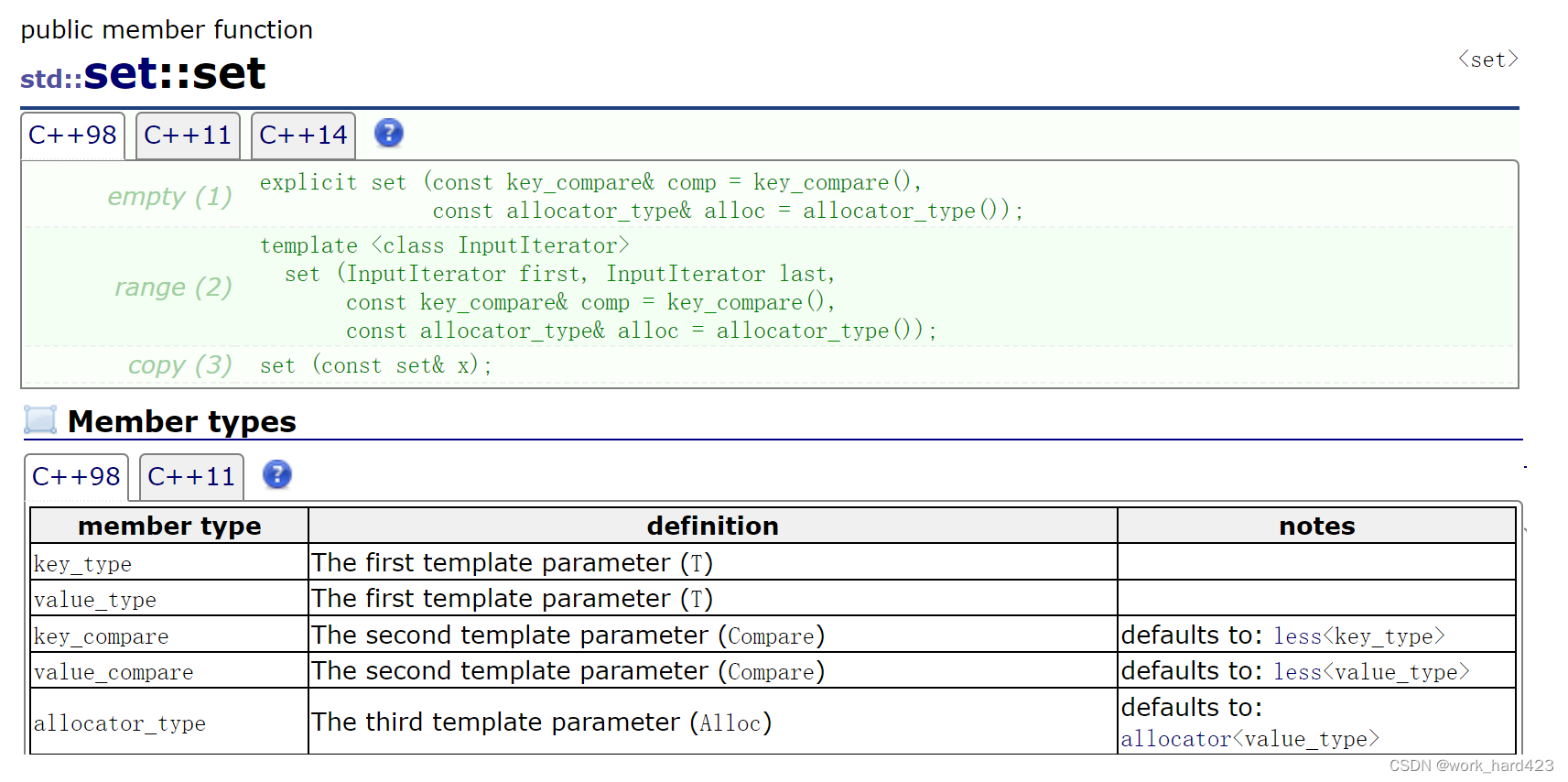
如上图,第一个构造函数可以表示无参的默认构造,因为两个参数都有缺省值。
key_compare就是模板参数Compare,key_compare()表示Compare类型的匿名对象。可以发现是允许我们传比较器对象给构造函数的,传给构造函数后,比较器的类型是什么,那set的类型模板参数Compare也就是什么。示例1如下。
第二个构造函数是通过迭代器区间构造,可以是任意容器的迭代器,如下图演示。注意数组也是具有迭代器的,因为数组的物理空间是连续的,所以原生指针就完全等价于数组的迭代器。

第三个是拷贝构造。需要注意set的拷贝构造是深拷贝。
如下图,学到C++11后还有一个新的构造函数,即通过std::initializer_list构造set。

initializer_list是 C++11 引入的一个特殊类型,用于简化初始化列表的使用。它允许您以一种直观的方式初始化对象,并在函数参数中传递或返回一组值。下面是一个示例,演示了如何使用initializer_list。
#include <iostream>
#include <initializer_list>
void printList(std::initializer_list<int> numbers)
{
for (const auto& num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
}
int main()
{
// 使用初始化列表初始化对象
std::initializer_list<int> numbers = {1, 2, 3, 4, 5};
// 将初始化列表作为函数参数传递
printList({6, 7, 8, 9, 10});
return 0;
}在上面的示例中,std::initializer_list<int> 用于定义一个可以包含整数的初始化列表。在 printList 函数中,参数 numbers 的类型被指定为 std::initializer_list<int>,这样可以接受一个整数的初始化列表。
在 main 函数中,我们创建了一个对象 numbers,并使用初始化列表 {1, 2, 3, 4, 5} 来初始化它。然后,我们将另一个初始化列表 {6, 7, 8, 9, 10} 作为实参传递给 printList 函数。
通过使用 std::initializer_list,您可以轻松地在函数参数中传递任意数量的值,并在函数内部使用范围循环(Range-based for loop)对它们进行处理。
需要注意的是,std::initializer_list 主要用于传递一组值,并且它本身不提供其他操作或修改元素的方法。如果您需要对值进行更复杂的处理,可能需要将它们存储在容器类(如 std::vector)中。
有了这些基础,我们就能知道如何使用set的这个构造函数了,如下图。

operator=

需要注意set的operator=会发生深拷贝。
set的迭代器

注意set的迭代器是双向迭代器,不是随机迭代器,所以只支持++和--,不支持+1或者-2等操作。

具有正向迭代器和反向迭代器。cbegin()等接口返回的const_iterator,即常量迭代器。
通过set的正向迭代器遍历set这棵红黑树(平衡搜索树的一种)时,是走中序遍历,所以遍历打印值时默认就是升序序列,如下图所示。

因为范围for的底层就是通过迭代器的傻瓜式替换实现的,所以支持了迭代器,就支持范围for,如下图所示。值得注意的是,即使set对象没有被const修饰,但因为搜索树中节点的值不允许被修改,否则可能会导致搜索树不再是搜索树,所以解引用set的迭代器时获取的元素的值也是被const修饰过的,所以在下图中的范围for循环里,e是必须被const修饰的。

既然对正向迭代器begin()开始++是走中序遍历,自动就能遍历升序序列,又因为对反向迭代器rbegin()++就是倒着走的中序遍历,所以此时自然能遍历降序序列,如下图所示。

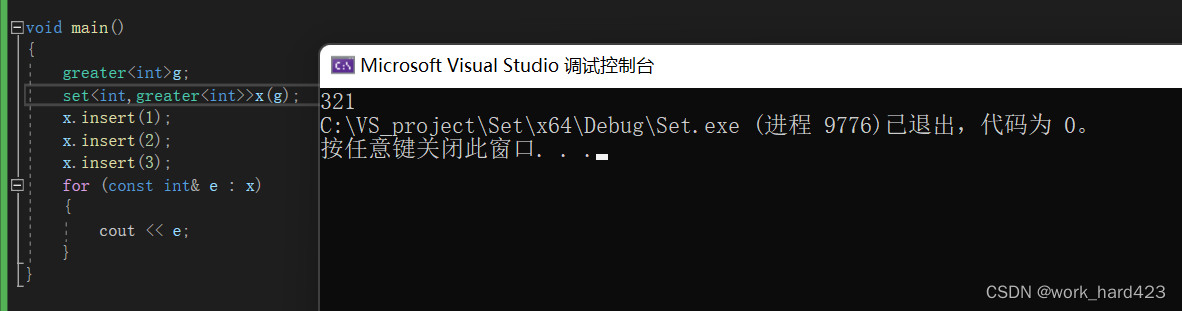
当然还有一种方法可以遍历降序序列,那就是把传给set的模板参数Compare的类型由默认的less<T>变成greater<T>。这样在insert函数插入新节点时,会通过greater<T>类的对象比较大小,新节点比当前遍历到的节点大就往左走,反之往右走,那么通过正向迭代器遍历这棵树时,自然遍历到的是降序序列,如下图所示。注意使用less或者greater这两个类模板时要包头文件functional。

insert

第一个表示插入一个值为val的节点。插入成功则返回一个键值对pair,键值对的key是指向新插入节点的迭代器,value是个bool值,此次插入节点成功,所以bool值为true。如果插入失败,则只有一种可能,就是红黑树(平衡二叉搜索树的一种)中已经存在值为val的节点了,插入失败则返回一个键值对pair,键值对的key是指向【set中值等于val的节点】的迭代器,value是个bool值,因为插入节点已经存在了,所以插入失败,所以bool值为false。
第二个表示在迭代器position指向的位置上插入一个值为val的节点。这个接口不常用,因为set是一棵红黑树,红黑树是平衡二叉搜索树的一种,而搜索树又是一棵排序树,也就是说节点之间是有次序之分的,如果值为val的节点本不该插在迭代器position指向的位置上,则它会另找一个合适的位置插入,相当于position这个参数没有起到作用,那干嘛不直接调用第一个版本的insert函数呢?返回值:插入成功时返回一个迭代器,该迭代器指向新插入的节点;只有当set中存在和val值相同的节点时,插入才会失败,此时返回一个指向【set中值等于val的节点】的迭代器。
第三个表示插入若干节点到set中,这些节点的val值依次等价于【迭代器first,迭代器last)这个区间的迭代器解引用后的值,注意这里是左闭右开。该版本的insert无返回值。
find

如果找到了,则返回一个迭代器,迭代器指向值为val的节点;如果没找到,则返回一个【和函数end()返回的迭代器】相同的迭代器,也就是返回指向最后一个元素的后一个位置的迭代器,注意即使容器中不存在任何元素,前面说的这个end迭代器也存在。
find函数通常配合erase使用。
如果是const set对象调用的find,则返回常量版本的迭代器(const_iterator)。
erase
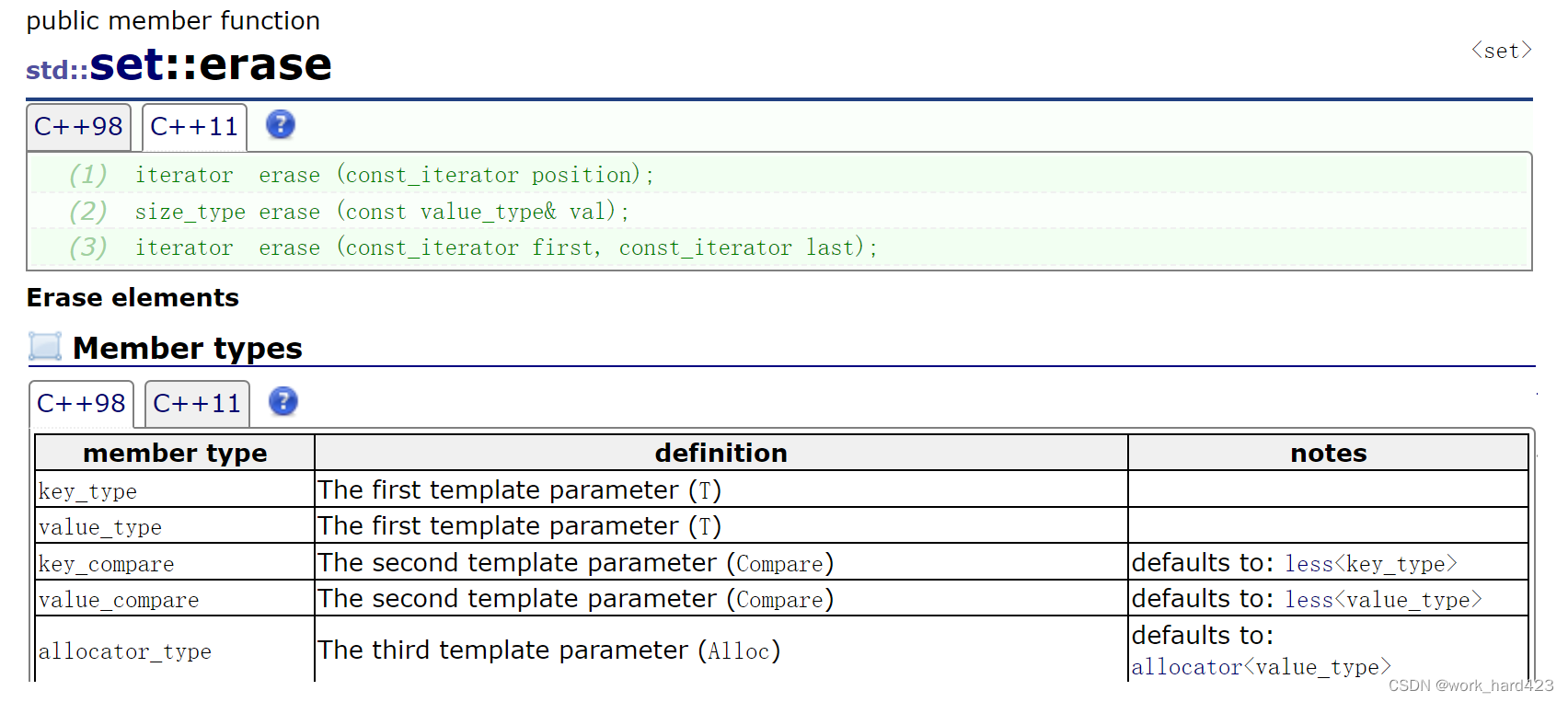
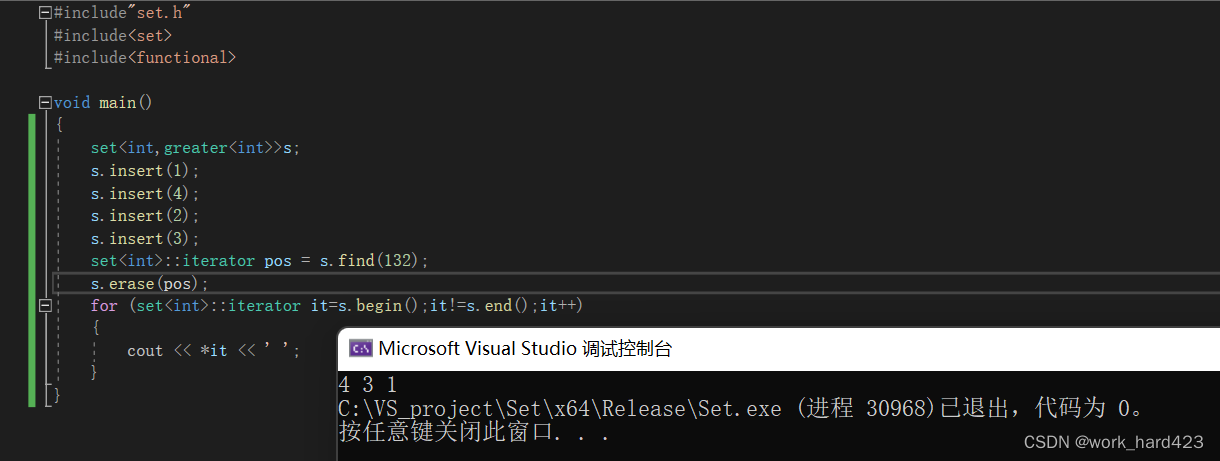
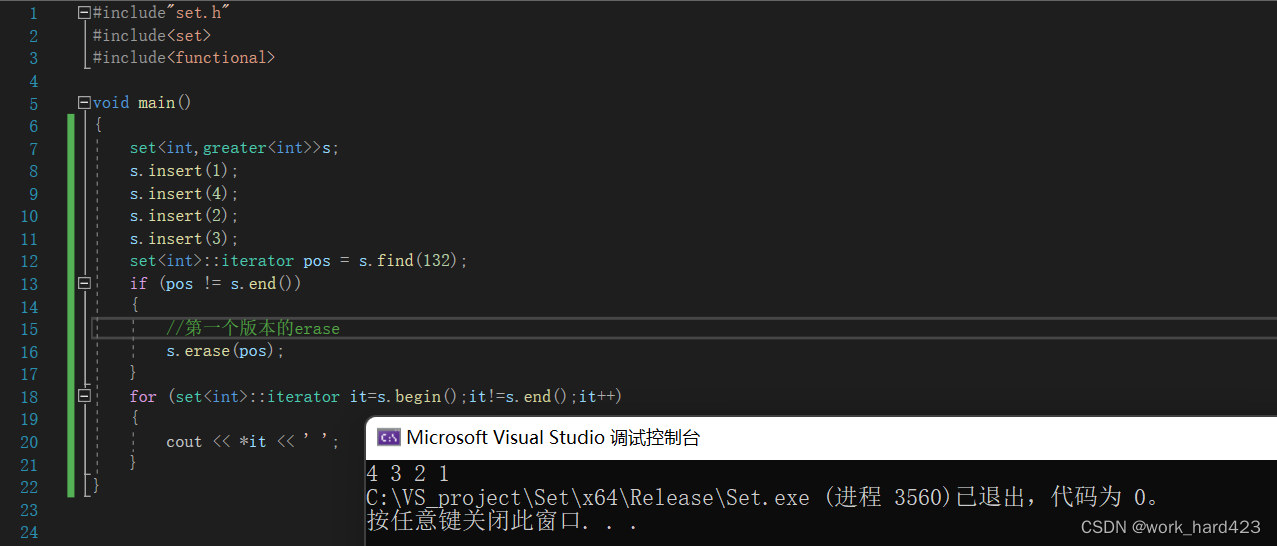
第一个表示删除迭代器position指向的节点,删除成功则返回指向【position指向的位置的下一个位置】的迭代器,如果是最后一个元素被删除时,则返回和【成员函数end()返回的迭代器】指向相同的迭代器。如果删除失败,只有一种可能,就是传给position的实参即迭代器已经越界了,此时函数会调用失败,断言报错。这里还有一个坑,断言assert只在debug模式下生效,release模式下assert就无效了,如果此时迭代器越界,就会发生各种意向不到的错误,如下图1,此时find(132)时查找不到132,就会返回和【end()函数返回的迭代器】指向相同的迭代器,此时erase删除这个迭代器指向位置的元素时,却把无辜的2删除了,这是不符合常理的。为此,我们使用第一个版本的erase函数时最好配合find函数,如下图2所示,如果find没找到,返回了和【end()返回的迭代器】指向相同的迭代器,则不要删,删了就会出现意想不到的问题。

第二个表示删除值为val的节点,函数返回被删除的元素的个数,如果删除成功,则返回1,失败则返回0。这个版本的erase在删除失败时什么都不会发生,不会像第一个版本那样产生意想不到的问题,为什么呢?可以认为第二个版本的erase就是复用了find和第一个版本的erase,如下图,如果没找到,则不删。
第三个表示在set中删除【first,last)这个迭代器区间内的所有迭代器指向的节点,区间左闭右开,注意这个迭代器区间是set的迭代器区间,而不是其他容器的迭代器区间。成功则返回【和last迭代器指向位置相同的迭代器】,注意last迭代器是const_iterator,而返回的迭代器则是非const的迭代器。如果在release版本下,即断言不起作用的情况下,erase时迭代器的指针还越界,则也和第一个版本的erase一样,会发生意想不到的错误。
key_comp和value_comp

这两个函数的功能、用法、以及参数和返回值都是一样的,用于返回一个比较器对象,即Compare类型的对象。明明set是K模型的BSTree,只有value,没有key,为什么存在key_comp这个接口呢?原因一:是为了更规范,让set和map保持一致;原因二:set底层也是键值对,只是key和value相同,是<value,value>的键值对。
count

在set中,该接口其实没有什么用,只能用于判断一个值为val的节点是否存在于set中,如果存在,则返回1,不存在则返回0。因为multieset中的count的有价值,为了让set和multiset的接口保持一致,所以也为set提供了该接口。
lower_bound

如果set类的Compare是用默认比较类型(less)实例化的,那么函数会返回指向【大于等于val,并且和val值最接近的元素】的迭代器,比如说有序列2、1、3、4,调用lower_bound(0)时,因为序列中的1是大于等于0(即val)并且和0最接近的元素,所以该函数返回指向元素1的迭代器;调用lower_bound(2)时,因为序列中的2是大于等于2(即val)并且和2最接近的元素,所以该函数返回指向元素2的迭代器;调用lower_bound(5)时,因为序列中没有元素大于等于5(即val),所以该函数返回【和end()函数返回的迭代器】指向相同的迭代器。
如果set类的Compare是用greater类模板实例化的类,那么函数会返回指向【小于等于val,并且和val值最接近的元素】的迭代器,比如说有序列2、1、3、4,调用lower_bound(5)时,因为序列中的4是小于等于5(即val)并且和5最接近的元素,所以该函数返回指向元素4的迭代器;调用lower_bound(2)时,因为序列中的2是小于等于2(即val)并且和2最接近的元素,所以该函数返回指向元素2的迭代器;调用lower_bound(0)时,因为序列中没有元素小于等于0(即val),所以该函数返回【和end()函数返回的迭代器】指向相同的迭代器。
upper_bound

如果set类的Compare是用默认比较类型(less)实例化的,那么函数会返回指向【大于val,并且和val值最接近的元素】的迭代器,比如说有序列2、1、3、4,调用lower_bound(0)时,因为序列中的1是大于0(即val)并且和0最接近的元素,所以该函数返回指向元素1的迭代器;调用lower_bound(2)时,因为序列中的3是大于2(即val)并且和2最接近的元素,所以该函数返回指向元素3的迭代器;调用lower_bound(5)时,因为序列中没有元素大于5(即val),所以该函数返回【和end()函数返回的迭代器】指向相同的迭代器。
如果set类的Compare是用greater类模板实例化的类,那么函数会返回指向【小于val,并且和val值最接近的元素】的迭代器,比如说有序列2、1、3、4,调用lower_bound(5)时,因为序列中的4是小于5(即val)并且和5最接近的元素,所以该函数返回指向元素4的迭代器;调用lower_bound(2)时,因为序列中的1是小于2(即val)并且和2最接近的元素,所以该函数返回指向元素1的迭代器;调用lower_bound(0)时,因为序列中没有元素小于0(即val),所以该函数返回【和end()函数返回的迭代器】指向相同的迭代器。
lower_bound和upper_bound的应用场景
(先说明一下,lower_bound()和upper_bound()这两个函数实际上不常用,了解一下即可。)
假如有set<int,less<int>>s={12,1,2,9,5,7};
此时s.lower_bound(1)就能拿到指向1的迭代器pos1,s.upper_bound(7)就能拿到指向9的迭代器pos2,那么此时erase(pos1,pos2)就能删除set中值大于等于1,小于9的所有元素,不包括9是因为erase(first,last)时,【first,last)是左闭右开区间。
示例如下图。

常见误解:认为上面场景中,因为pos1指向1,pos2指向9,而set对象在初始化时是{12,1,2,9,5,7},所以1到9之间的元素只有1、2、9,所以erase(pos1,pos2)删除1到9之间的元素后,会剩下的元素是{12,5,7}。如果你这么想,那你就搞错了,虽然初始化set时给出的元素的顺序像{12,1,2,9,5,7}这样,但不代表set被初始化完毕后元素的排列依然是{12,1,2,9,5,7},因为set不是数组,它是树形结构,并且还是搜索树。
equal_range

equal_range函数与【lower_bound和】这俩函数没啥区别,只不过equal_range返回一个pair<iterator,iterator>键值对类的对象,对象的key值和value值都是一个迭代器,key迭代器等价于lower_bound()函数返回的迭代器,value迭代器等价于upper_bound()函数返回的迭代器。
multiset
multiset和set只有一个区别,就是multiset允许键值冗余,而set不允许,其他所有性质,multiset和set都保持一致,所以如果会用set,那么一定会用multiset。
什么叫做键值冗余呢?说人话就是multiset中可以存在重复的元素,如下图所示。

也因为multiset允许键值冗余,导致multiset有一些接口的性质和set相比也会发生变化,请往下看。
count

上面说count在set中没啥用,但在multiset中就有一定价值了,他能返回set中有几个值为val的元素,返回值为size_t类型。
find

因为multiset中可以存在重复值,所以multiset的find会返回指向【中序遍历时最先遍历到的值为val的节点】的迭代器,如下图情况,find(1)时就会返回指向【根节点1的左孩子节点1】的迭代器,而不是返回指向根节点1的迭代器。

erase

第一个版本用于删除指定迭代器position位置上的节点。如果迭代器越界,在debug下会断言报错,在release下会产生意想不到的错误,详情见讲解set的find部分。
第二个版本用于删除set中所有值为val的节点,比如set中有4个1,那么erase(1)时,就会把4个值为1节点全部删除,返回值就是4。第二个版本的erase的返回值表示删除了几个元素。
第三个版本用于删除一个迭代器区间指向的若干节点,给出的迭代器越界会和第一个版本的erase一样出现问题。
map
简介

关于map的模板参数,Compare就不再提了,因为set中说的已经非常详细了;Alloc等学完了空间配置器再谈。我们说过,map是一棵KV模型的平衡二叉搜索树,所以模板参数Key和T分别代表键值对pair<T1,T2>类中的T1和T2。
map是关联容器,它按照特定的次序存储由T1类型的键值key和T2类型的值value组合而成的pair<T1,T2>元素。如何决定次序呢?通过Compare类的对象(即比较器)按照T1类型的key值来比较大小,大小决定次序。
在map中,键值key通常用于排序和唯一地标识元素,而值value中存储与此键值key关联的
内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型
value_type绑定在一起,它是pair的别名,如下图所示。可以看到pair类的成员对象first,是const Key类的对象,被const修饰,所以不能被修改,但是pair类的成员对象second是可以被修改的。

构造函数

第一个是默认构造;
第二个是迭代器区间构造,可以是任意容器的迭代器;
第三个是拷贝构造。
map的迭代器
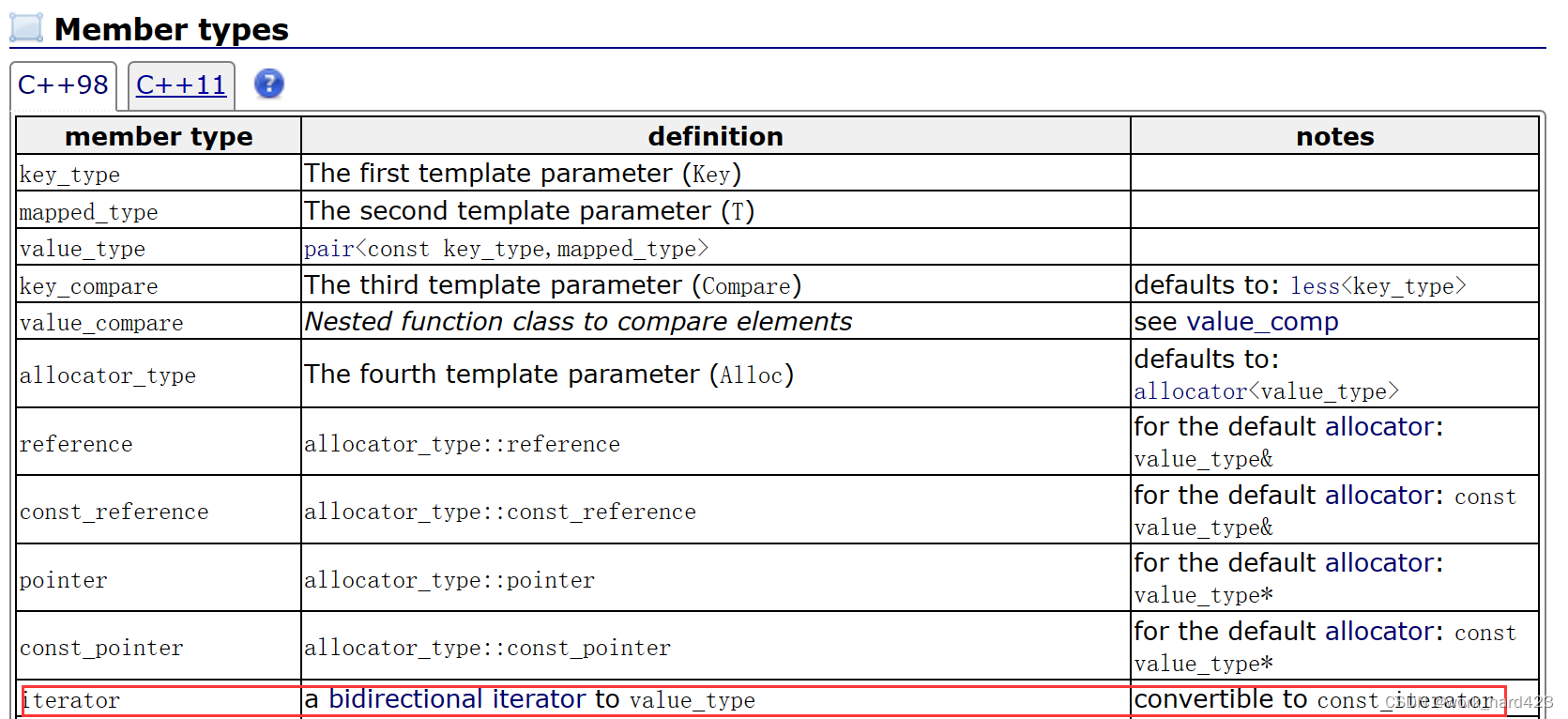
如上图红框处,map的迭代器是一个双向迭代器。
map是一棵树(红黑树),所以map的迭代器指向树中的节点node。
map这棵树上的节点的值的类型是pair<T1,T2>。
虽然map的迭代器指向树中的节点node,但解引用map的迭代器时,获取的不是node对象,而是pair<T1,T2>对象,如下图所示。

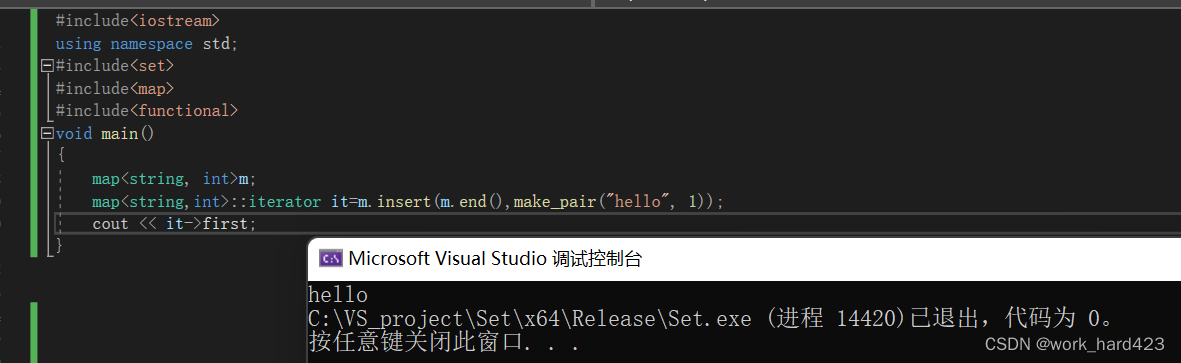
如果你对迭代器解引用it->first操作不太熟悉,可以看看下图逻辑。

正向遍历的方法如下图,上面说过:虽然map的迭代器指向树中的节点node,但解引用map的迭代器时,获取的不是node对象,而是pair<T1,T2>对象,所以下图的e就是pair对象,这边为了避免深拷贝string,所以e是引用类型。
map和set一样都是红黑树,所以通过正向迭代器遍历红黑树时,都是走中序遍历,因为Compare现在是默认的less<string>,所以排升序,所以im在hi的后面,有人会说,不对啊,如果是升序为什么2在1的前面?答案:这是因为map比较节点大小时(在map里,节点的值是pair对象),只按照节点的值(即pair对象)的first成员变量比较,和其他因素无关,所以2排在1前面是正常现象。

insert
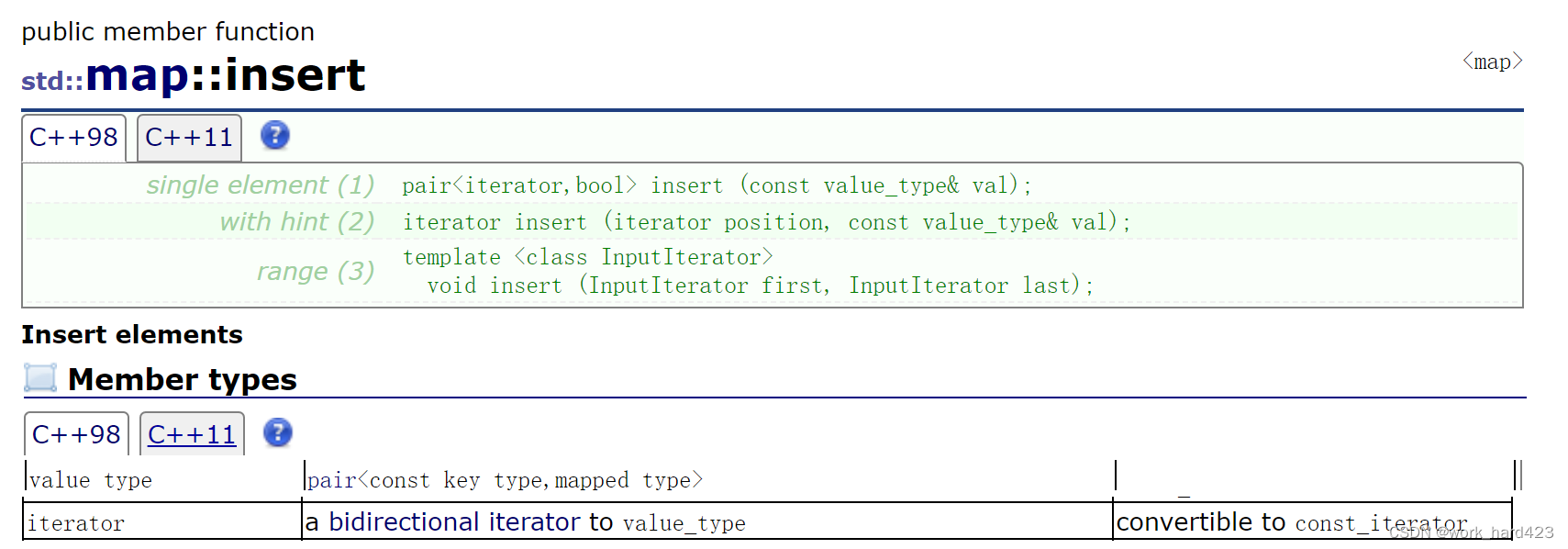
1.上面说过,value_type是在map内给pair<const Key,T>类typedef起的别名,所以第一个版本的insert就需要pair作为实参,如下图所示。

解释一下上图的流程:“你好”是一个C语言字符串,所以按理来说无法给pair<string,int>类的对象赋值,但因为string类有一个如下图般的单参数的通过C语言字符串构造string的构造函数,并且该函数还没有被explicit修饰,所以允许发生隐式转换,所以会通过“你好”这个C语言字符串隐式转换出一个临时的匿名string对象,然后把该临时的匿名对象赋值给下图pair构造函数中的参数常量引用a,把常量1赋值给常量引用b,此时pair对象就初始化完毕了,然后把pair对象传给第一个版本的insert函数,插入后程序结束。

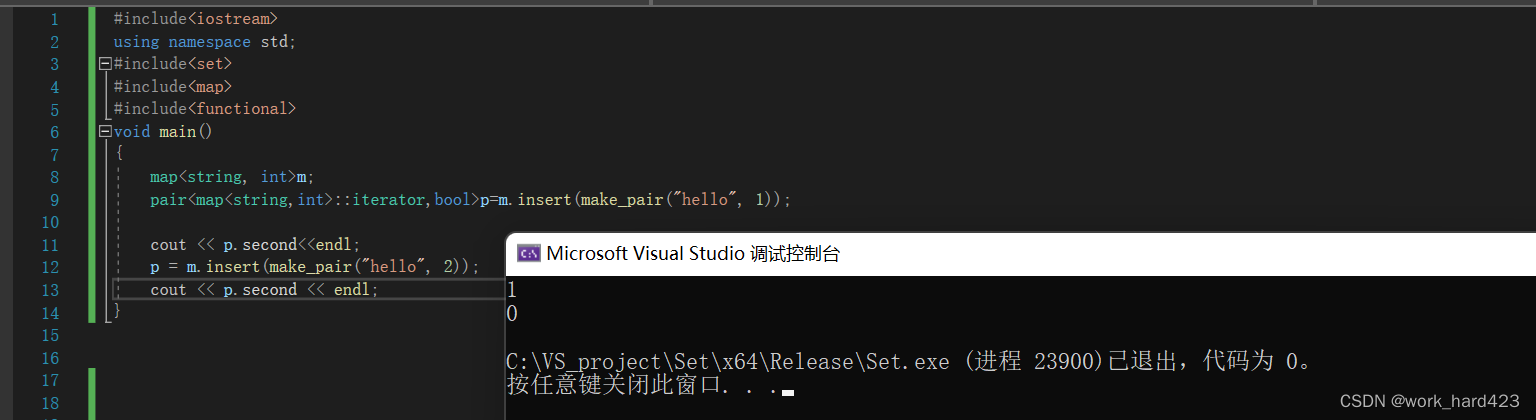
返回值:value_type类就是pair类,注意如果新插入节点的值(即pair对象val)的first成员的值在map中已经存在,则会插入失败并返回一个临时的pair对象temp,temp的first是set的迭代器,迭代器指向map中的一个节点,该节点的值(即pair对象)的first成员的值和【pair对象val的first】相等,然后temp的second是个bool值,因为插入失败了,所以值为false。如果新插入节点的值(即pair对象val)的first成员的值在map中不存在,则插入成功,返回一个临时的pair对象temp,temp的first是set的迭代器,迭代器指向刚刚被插入的新节点,temp的second是个bool值,因为插入成功了,所以值为true。
示例如下图,第一次插入时,map这棵树的节点Node的值(即pair对象)的first成员“hello”在map中不存在,所以插入成功,返回的临时pair对象temp的first成员(即迭代器)指向新插入的节点,temp的second成员(即bool值)是true,所以打印出1。第二次插入时,因为“hello”已经在map中存在了,所以boo值是false,打印出0。
2.第二个版本的insert是在迭代器position指向的位置上插入值为val的节点,val的类型是pair。这个接口不常用,因为map是一棵红黑树,红黑树是平衡二叉搜索树的一种,而搜索树又是一棵排序树,也就是说节点之间是有次序之分的,如果值为val的节点本不该插在迭代器position指向的位置上,则它会另找一个合适的位置插入,相当于position这个参数没有起到作用,那干嘛不直接调用第一个版本的insert函数呢?
返回值:注意如果新插入节点的值(即pair对象val)的first成员的值在map中已经存在,则会插入失败并返回一个迭代器,迭代器指向map中的一个节点,该节点的值(即pair对象)的first成员的值和【pair对象val的first】相等。如果新插入节点的值(即pair对象val)的first成员的值在map中不存在,则插入成功,返回一个迭代器,迭代器指向刚刚被插入的新节点。
示例如下。
3.第三个表示插入若干节点到set中,这些节点的值(即pair对象)依次等价于【迭代器first,迭代器last)这个区间的迭代器解引用后的值(即pair对象),注意这里是左闭右开。可以传任意容器的迭代器,但注意因为map节点的值是pair类型,所以迭代器解引用后拿到的值也必须是pair类型,比如vector<pair<int,int>>类的迭代器就可以传给该版本的insert函数,示例如下图。
该版本的insert无返回值。

erase
第一个版本,删除迭代器position指向的节点,无返回值。
第二个版本,map中的Node节点所存储的有效数据是一个个pair<T1,T2>,key_type k就是T1类的对象,该接口用于删除map中的pair的first为k的节点。
第三个版本,删除一个迭代器区间的节点,注意这个迭代器只能是map的迭代器。
find

map中的Node节点所存储的有效数据是一个个pair<T1,T2>,key_type k就是T1类的对象,所以find接口用于找到pair的first等于k的节点,返回一个迭代器,迭代器指向该节点。
operator【】

map中的Node节点所存储的有效数据是一个个pair<T1,T2>,key_type k就是T1类的对象,mapped_type类就是T2类。
如果map中,存在节点的值(即pair)的first等于k,则本函数就是返回这个pair的second对象的引用;如果map中,没有节点的值(即pair)的first等于k,则调用本函数时,就插入一个新节点Node,Node节点的值(即pair)的成员对象first就等于k,pair的成员对象second就等于它默认构造后的值,插入完毕后,返回这个pair的成员对象second的引用。
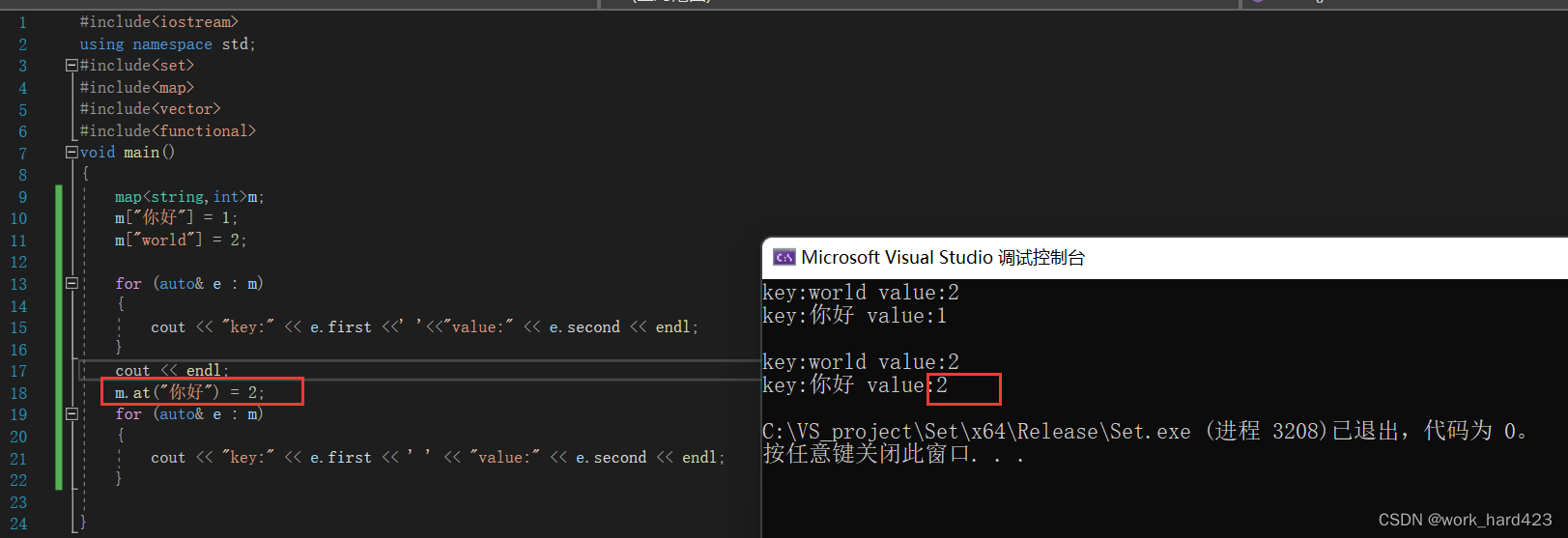
如下图演示,因为map中,没有节点的值(即pair)的first等于“你好”,所以通过m[“你好”]调用函数m.operator[](“你好”)后,能自动在map里插入一个Node节点,插入完毕后节点的值(即pair)的first对象为“你好”,second对象是int类型,调用默认构造后值为0,最后返回刚刚新插入节点的值(即pair)的second成员对象的引用,到这里operator[]函数就结束了,即m[“你好”]已经结束了,然后=2,将这个返回的int类型的引用对象second的值从0改成2。

operator[]的底层实现类似于下图。

at
map中的Node节点所存储的有效数据是一个个pair<T1,T2>,key_type k就是T1类的对象,mapped_type类就是T2类。
at函数和operator[]的功能大致一样,如果map中,存在节点的值(即pair)的first等于k,则本函数就是返回这个pair的second对象的引用,并且因为该引用不是常量引用,所以可以对second对象的值进行修改;
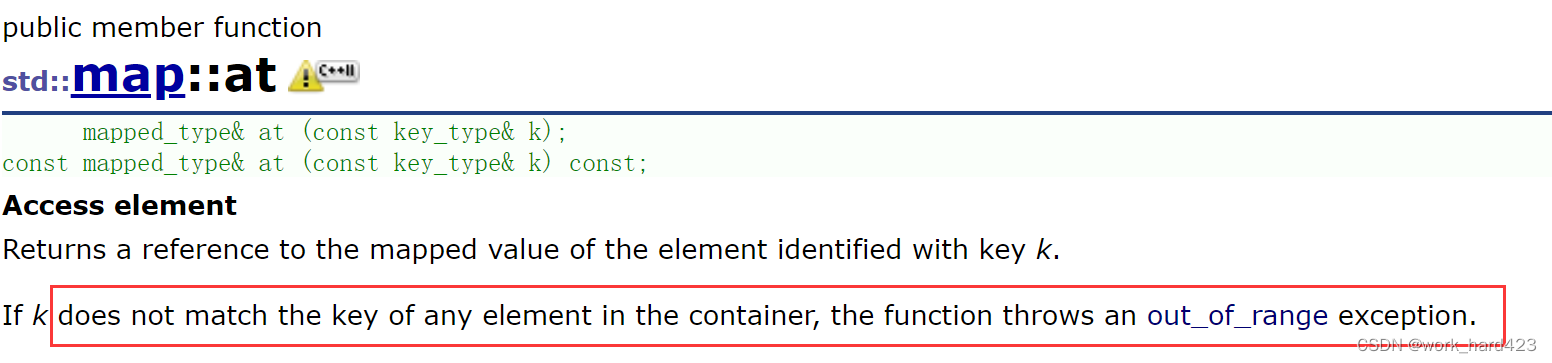
at函数和operator[]有一个区别,调用at函数时,如果map中,没有节点的值(即pair)的first等于k,则如上图红框处所示,会直接抛异常。但在调用operator[]时,如果没有节点的值(即pair)的first等于k,则operator[]的功能是插入pair(k,T2() ),然后返回pair的成员对象second的引用,详情见讲解operator[]的部分。
演示如下图。
使用场景

multimap
大部分性质和map是完全一样的,所以会了map,就相当于也会了multimap,但它们之间也有一些区别,这些区别都是因为【multimap中允许不同节点的值(即pair)的成员对象first的值相同】导致的,比如说multimap就没有了operator[]函数。
find

因为multimap中允许不同节点的值(即pair)的成员对象first的值相同,所以find函数用于找到中序遍历下第一个节点的值(即pair)的成员对象first为k的节点。
如果找到了目标节点,则返回指向该节点的迭代器;如果没找到,则返回和【end()函数返回的迭代器】指向相同的迭代器。
erase

第一个版本用于在multimap中删除迭代器position指向的节点。
因为multimap中允许不同节点的值(即pair)的成员对象first的值相同,所以第二个版本的erase用于删除multimap中节点的值(即pair)的成员first的值等于k的所有节点,返回值表示成功删除了几个节点。
删除一个迭代器区间指向的所有节点,这个迭代器只能是multimap的迭代器。















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









