







介绍
-
定义:
概念学习是指从有关某个布尔函数的输入输出训练样例中,推断出该布尔函数。其结果是布尔函数,即true or false。
每个概念可被看作一个对象或事件集合,它是从更大的集合中选取的子集(如从动物的集合中选取鸟类) -
每个属性值可使用的符号:
- 由“?”表示任意值
- 明确指定的属性值(如 AirTemp=Warm)
- 由“∅”表示不接受任何值
如果某些实例x满足假设h的所有约束,就将x分类为正例。
比如,为判定 Aldo 只在寒冷和潮湿的日子里进行水上运动(并与其他属性无关),这样的假设可表示为下面的表达式:
< ? , C o l d , H i g h , ? , ? , ? > <?, Cold, High, ?, ?, ?> <?,Cold,High,?,?,?>
最一般的假设是每一天都是正例,可表示为:
< ? , ? , ? , ? , ? , ? > <?, ?, ?, ?, ?, ?> <?,?,?,?,?,?>
而最特殊的假设即每一天都是反例,表示为:
< ∅ , ∅ , ∅ , ∅ , ∅ , ∅ > <∅, ∅, ∅, ∅, ∅, ∅ > <∅,∅,∅,∅,∅,∅>
-
术语
目标概念:待学习的概念或函数,记作c。
在学习目标概念时,必须提供一套训练样例(training examples),每个样例为 X 中的一个实例 x 以及它的目标概念值 c(x)(如表 2-1 中的训练样例)。对于 c(x)=1 的实例被称为正例(positive example),或称为目标概念的成员。对于 c(x)=0 的实例为反例(negative example),
或称为非目标概念成员。
归纳学习:从特殊的训练样例(关于概念的正/反样例)中归纳出一般的概念描述(函数),它的一般操作是泛化和特化。这也是机器学习的中心问题。
归纳学习算法最多只能保证输出的假设能与训练样例相拟合。如果没有更多的信息,我们只能假定,对于未见实例最好的假设就是与训练数据最佳拟合的假设。这是归纳学习的一个基本假定。
概念学习
概念学习可以看作是一个搜索的过程,范围是假设的表示所隐含定义的整个空间。搜索的目标是为了寻找能最好地拟合训练样例的假设。
如果属性 Sky有 3 种可能的值,而 AirTemp、 Humidity、 Wind、 Water 和 Forecast 都只有两种可能值,则:
不同实例: 3×2×2×2×2×2=96
语法不同:5×4×4×4×4×4=5120
语义不同:1+4×3×3×3×3×3=973
语法不同和语义不同对于每个属性包括?和∅,而在语义不同条件下,但凡每个属性出现∅的假设都只视为一种,这就是1的来源。
假设的一般到特殊序
为说明一般到特殊序,考虑以下两个假设:
h
1
=
<
S
u
n
n
y
,
?
,
?
,
S
t
r
o
n
g
,
?
,
?
>
h
2
=
<
S
u
n
n
y
,
?
,
?
,
?
,
?
,
?
>
h_1=<Sunny, ?, ?, Strong, ?, ?>\\ h_2=<Sunny, ?, ?, ?, ?, ?>
h1=<Sunny,?,?,Strong,?,?>h2=<Sunny,?,?,?,?,?>
由于
h
2
h_2
h2的包含的实例约束条件更少,他划分出正例也较多,所以,我们说
h
2
h_2
h2比
h
1
h_1
h1更一般。
也就是说含括更多样本的集合,就更一般,因为一般人会比特殊的人更多。
首先,对
X
X
X中任意实例
x
x
x和
H
H
H中任意假设
h
h
h,我们说
x
x
x 满足
h
h
h 当且仅当
h
(
x
)
=
1
h(x)=1
h(x)=1。现在以实例集合的形式定义一个more-general-than-or-equal-to 的关系:
给定假设
h
j
h_j
hj和
h
k
h_k
hk,
h
j
h_j
hj more-general-than-or-equal-to
h
k
h_k
hk,当且仅当任意一个满足
h
k
h_k
hk的实例同时也满足
h
j
h_j
hj。

定义逆向关系:“比…更特殊 ” more_specific_than
Find-S 寻找极大特殊假设
算法:

为说明这一算法,假定给予学习器的一系列训练样例如表 2-1 所示。 Find-S 的第一步是将 h 初始化为 H 中最特殊假设:
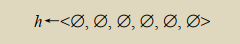
在扫描到表 2-1 中第一个训练样例时,它刚好是个正例。很清楚,这时的 h 太特殊了。h 中的每一个∅约束都不被该样例满足,因此,每个属性都被替换成能拟合该例的紧邻的更一般的值约束,也就是这一样例的属性值本身:
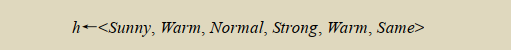
这个 h 仍旧太特殊了,它把除了第一个样例以外的所有实例都划分为反例。下一步,第2个训练样例(仍然为正例)迫使该算法进一步将 h 泛化。这次使用“?”代替 h 中不能满足新样例的属性值。之后的假设变为:
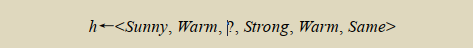
然后处理第三个训练样例,这里是一个反例, h 不变。实际上, Find-S 算法简单地忽略每一个反例!
大致流程就是如上
变型空间和候选消除算法
候选消除算法优势:它能解决 Find-S 中的若干不足之处。 Find-S 输出的假设只是 H 中能够拟合训练样例的多个假设中的一个。 而在候选消除算法中, 输出的是与训练样例一致的所有假设的集合。
表示
一致的定义:

h是训练样例,c是假设结果。
变型空间:候选消除算法能够表示与训练样例一致的所有假设。 在假设空间中的这一子集被称为关于假设空间 H 和训练样例 D 的变型空间(version space)。
算法:

更简明的表示
再一次考虑表 2-2 中描述的 EnjoySport 概念学习问题。对于表 2-1 中给定的 4 个训练样例, Find-S 输出假设:
h
=
<
S
u
n
n
y
,
W
a
r
m
,
?
,
S
t
r
o
n
g
,
?
,
?
>
h=<Sunny, Warm, ?, Strong, ?, ?>
h=<Sunny,Warm,?,Strong,?,?>
实际上,这只是 H 中与训练样例一致的所有 6个假设之一。
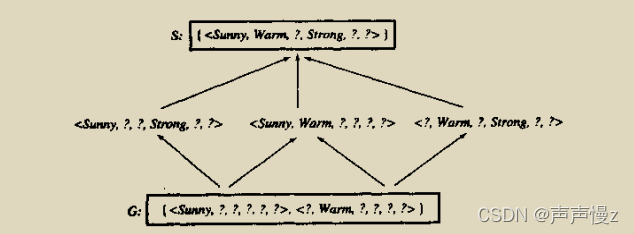
可以直观地看出,使用最一般和最特殊集合表示变型空间的作法是合理的。下面我们精确地定义 S 和 G 这两个边界集合,并且证明它们确实代表了变型空间。

一般边界就是确定条件比较少,“?”比较多的假设,从全“?”开始,慢慢消去“?”。特殊边界就是条件比较多,从全空开始。
算法过程:


样例:


可以发现:
- G和S都是要把样例划分为正的假设,只不过不满足G的样例一定是负,而S不一定。
- 如何理解G和S,G=general代表了这个假设更一般,S=special代表这个假设更特别,所以满足S假设的样例一定要满足G假设,所以S假设是G假设的上界。
- 遇到第一个反例时要去找样例中与S假设中不同的属性,这些属性就是G的改变属性。为什么?因为只能做一步的小调整,所以只能改变一个属性,而且G要满足正样例,所以只能改变负样例中与当前S不同的属性,将该属性置为负样例属性的相反值。


图中的红X是第4个样例改变的。
关于变型空间和候选消除的说明
候选消除算法是否会收敛到正确的假设
由候选消除算法得到的变型空间能够收敛到描述目标概念的假设的条件是:
(1)在训练样例中没有错误
(2)在 H 中确实包含描述目标概念的正确假设。
如果训练数据中包含错误会怎样?
这种情况下,很不幸,算法肯定会从变型空间中删除正确的目标概念。
当然,如果给定足够的训练数据,最终,我们会发现 S 和 G 边界收敛得到一个空的变型空间,从而得知训练数据有误。空的变型空间表示 H 中没有假设能够与样例一致。
归纳偏置
无偏的学习器
思路:提供一个假设空间H, 能表达所有的可教授概念, 换言之, 它能够表达实例集X的所有可能的子集, 称之为X的幂集P(X)。

假设的并。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









