







https://blog.csdn.net/worn_xiao/article/details/105901275 二叉查找树,平衡二叉树,红黑树
注意:最好先看一下(三)中 树红黑树的数据结构分析,可以的话数组,链表的数据结构也先复习一下,这里默认你懂数组,链表
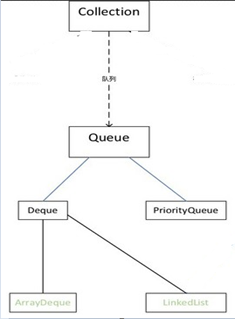
一 集合框架
-
- 集合产生的背景
“世间本没有路 走的人多了也便成了路”—周树人(鲁迅)
世间本没有集合,(只有数组参考C语言)要的人多了,便有了集合
有人想有可以自动扩展的数组就好了,所以有了List
有人想有没有不重复的数组,所以有了set
有人想有没有自动排序的组数,所以有了TreeSet,TreeList,Tree**
而几乎有有的集合都是基于数组来实现的,因为集合是对数组做的封装,所以,数组永远比任何一个集合要快,但任何一个集合,比数组提供的功能要多。
1.2 完整的java集合框架

1.3 常用集合元素
1.3.1 Collection<E>
Collection是所有单值集合的根接口,E表示集合中元素的类型.JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如List,Set等).
1.3.2 Map<K,V>
Map<K,V>是所有映射的根接口,与Collection最大的区别就是:映射中的关系是成对出现的,K表示映射关系的键,V表示映射关系的值.在映射中,K是不可重复的,V是可重复的.
二 深入理解常用集合
2.1 List
List的特征是其元素以线性方式存储,集合中可以存放重复对象。
2.1.1 List常用元素
ArrayList: 代表长度可以改变得数组。可以对元素进行随机的访问,向ArrayList()中插入与删除元素的速度慢。
LinkedList: 在实现中采用链表数据结构。插入和删除速度快,访问速度慢。
对于List的随机访问来说,就是只随机来检索位于特定位置的元素。 List 的 get(int index) 方法放回集合中由参数index指定的索引位置的对象,下标从“0” 开始。
2.1.2 List功能方法
实际上有两种List:一种是基本的ArrayList,其优点在于随机访问元素,另一种是更强大的LinkedList,它并不是为快速随机访问设计的,而是具有一套更通用的方法。
List:次序是List最重要的特点:它保证维护元素特定的顺序。List为Collection添加了许多方法,使得能够向List中间插入与移除元素(这只推 荐LinkedList使用。)一个List可以生成ListIterator,使用它可以从两个方向遍历List,也可以从List中间插入和移除元素。
ArrayList:由数组实现的List。允许对元素进行快速随机访问,但是向List中间插入与移除元素的速度很慢。ListIterator只应该用来由后向前遍历 ArrayList,而不是用来插入和移除元素。因为那比LinkedList开销要大很多。
LinkedList :对顺序访问进行了优化,向List中间插入与删除的开销并不大。随机访问则相对较慢。还具有下列方法:addFirst(), addLast(), getFirst(), getLast(), removeFirst() 和 removeLast(), 这些方法使得LinkedList可以当作堆栈、队列和双向队列使用。
2.1.3 List工作原理
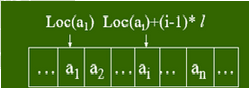
概括的说,ArrayList 是一个动态数组,允许元素为null。其底层数据结构依然是数组,它实现了List<E>, RandomAccess, Cloneable, java.io.Serializable接口,其中RandomAccess代表了其拥有随机快速访问的能力,ArrayList可以以O(1)的时间复杂度去根据下标访问元素。因其底层数据结构是数组,所以可想而知,它是占据一块连续的内存空间(容量就是数组的length),所以它也有数组的缺点,空间效率不高。
由于数组的内存连续,可以根据下标以O1的时间读写(改查)元素,因此时间效率很高。当集合中的元素超出这个容量,便会进行扩容操作。扩容操作也是ArrayList 的一个性能消耗比较大的地方,所以若我们可以提前预知数据的规模,应该通过public ArrayList(int initialCapacity) {}构造方法,指定集合的大小,去构建ArrayList实例,以减少扩容次数,提高效率。
//默认构造函数里的空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//存储集合元素的底层实现:真正存放元素的数组
transient Object[] elementData; // non-private to simplify nested class access
//当前元素数量
private int size;
//默认构造方法
public ArrayList() {
//默认构造方法只是简单的将 空数组赋值给了elementData
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//带初始容量的构造方法
public ArrayList(int initialCapacity) {
//如果初始容量大于0,则新建一个长度为initialCapacity的Object数组.
//注意这里并没有修改size(对比第三个构造函数)
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//如果容量为0,直接将EMPTY_ELEMENTDATA赋值给elementData
this.elementData = EMPTY_ELEMENTDATA;
} else {//容量小于0,直接抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//利用别的集合类来构建ArrayList的构造函数
public ArrayList(Collection<? extends E> c) {
//直接利用Collection.toArray()方法得到一个对象数组,并赋值给elementData
elementData = c.toArray();
//因为size代表的是集合元素数量,所以通过别的集合来构造ArrayList时,要给size赋值
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)//这里是当c.toArray出错,没有返回Object[]时,利用Arrays.copyOf 来复制集合c中的元素到elementData数组中
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
//如果集合c元素数量为0,则将空数组EMPTY_ELEMENTDATA赋值给elementData
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}代码小结一下,构造函数走完之后,会构建出数组elementData和数量size。
这里注意一下Collection.toArray()这个方法,在Collection子类各大集合的源码中,高频使用了这个方法去获得某Collection的所有元素。
关于方法:Arrays.copyOf(elementData, size, Object[].class),就是根据class的类型来决定是new 还是反射去构造一个泛型数组,同时利用native函数,批量赋值元素至新数组中。如下:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
//根据class的类型来决定是new 还是反射去构造一个泛型数组
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
//利用native函数,批量赋值元素至新数组中。
System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));
return copy;
}1 增
每次 add之前,都会判断add后的容量,是否需要扩容。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;//在数组末尾追加一个元素,并修改size
return true;
}
private static final int DEFAULT_CAPACITY = 10;//默认扩容容量 10
private void ensureCapacityInternal(int minCapacity) {
//利用 == 可以判断数组是否是用默认构造函数初始化的
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//如果确定要扩容,会修改modCount
// overflow-conscious code
if (minCapacity - elementData.length > 0)//这里ArrayList扩容的条件是,当前期望的容量大于数组的实际长度时候,就可以扩容了
grow(minCapacity);
}
//需要扩容的话,默认扩容一半
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//右移一位 100->010=4-2 也就是在原数组长度的基础上扩容一半
if (newCapacity - minCapacity < 0)//如果还不够 ,那么就用期望的最少容纳的最小的数量。(add后的容量)
newapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//拷贝,扩容,构建一个新数组,
}
public void add(int index, E element) {
rangeCheckForAdd(index);//越界判断 如果越界抛异常
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index); //将index开始的数据 向后移动一位
elementData[index] = element;
size++;
}
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount //确认是否需要扩容
System.arraycopy(a, 0, elementData, size, numNew);// 复制数组完成复制
size += numNew;
return numNew != 0;
}
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);//越界判断
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount //确认是否需要扩容
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);//移动(复制)数组
System.arraycopy(a, 0, elementData, index, numNew);//复制数组完成批量赋值
size += numNew;
return numNew != 0;
}总结:add、addAll。先判断是否越界,是否需要扩容。如果扩容, 就复制数组。然后设置对应下标元素值。
值得注意的是:
1 如果需要扩容的话,默认扩容一半。如果扩容一半不够,就用目标的size作为扩容后的容量。
2 在扩容成功后,会修改modCount
2 删
public E remove(int index) {
rangeCheck(index);//判断是否越界
modCount++;//修改modeCount 因为结构改变了
E oldValue = elementData(index);//读出要删除的值
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);//用复制 覆盖数组数据
elementData[--size] = null; // clear to let GC do its work //置空原尾部数据 不再强引用, 可以GC掉
return oldValue;
}
//根据下标从数组取值 并强转
E elementData(int index) {
return (E) elementData[index];
}
//删除该元素在数组中第一次出现的位置上的数据。 如果有该元素返回true,如果false。
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);//根据index删除元素
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//不会越界不用判断 ,也不需要取出该元素。
private void fastRemove(int index) {
modCount++;//修改modCount
int numMoved = size - index - 1;//计算要移动的元素数量
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);//以复制覆盖元素 完成删除
elementData[--size] = null; // clear to let GC do its work //置空 不再强引用
}
//批量删除
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);//判空
return batchRemove(c, false);
}
//批量移动
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;//w 代表批量删除后 数组还剩多少元素
boolean modified = false;
try {
//高效的保存两个集合公有元素的算法
for (; r < size; r++)
if (c.contains(elementData[r]) == complement) // 如果 c里不包含当前下标元素,
elementData[w++] = elementData[r];//则保留
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) { //出现异常会导致 r !=size , 则将出现异常处后面的数据全部复制覆盖到数组里
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;//修改 w数量
}
if (w != size) {//置空数组后面的元素
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;//修改modCount
size = w;// 修改size
modified = true;
}
}
return modified;
}从这里我们也可以看出,当用来作为删除元素的集合里的元素多余被删除集合时,也没事,只会删除它们共同拥有的元素。
小结:
1 删除操作一定会修改modCount,且可能涉及到数组的复制,相对低效。
2 批量删除中,涉及高效的保存两个集合公有元素的算法,可以留意一下。
3 改:不会修改modCount,相对增删是高效的操作。
public E set(int index, E element) {
rangeCheck(index);//越界检查
E oldValue = elementData(index); //取出元素
elementData[index] = element;//覆盖元素
return oldValue;//返回元素
}4 查: 不会修改modCount,相对增删是高效的操作。
public E get(int index) {
rangeCheck(index);//越界检查
return elementData(index); //下标取数据
}
E elementData(int index) {
return (E) elementData[index];
}5: 会修改modCount。
public void clear() {
modCount++;//修改modCount
// clear to let GC do its work
for (int i = 0; i < size; i++) //将所有元素置null
elementData[i] = null;
size = 0; //修改size
}6 包含 contain
//普通的for循环寻找值,只不过会根据目标对象是否为null分别循环查找。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
//普通的for循环寻找值,只不过会根据目标对象是否为null分别循环查找。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}7 判空 isEmpty()
public boolean isEmpty() {
return size == 0;
}8 迭代器 Iterator.
public Iterator<E> iterator() {
return new Itr();
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
int cursor; // index of next element to return //默认是0
int lastRet = -1; // index of last element returned; -1 if no such //上一次返回的元素 (删除的标志位)
int expectedModCount = modCount; //用于判断集合是否修改过结构的 标志
public boolean hasNext() {
return cursor != size;//游标是否移动至尾部
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)//判断是否越界
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)//再次判断是否越界,在 我们这里的操作时,有异步线程修改了List
throw new ConcurrentModificationException();
cursor = i + 1;//游标+1
return (E) elementData[lastRet = i];//返回元素 ,并设置上一次返回的元素的下标
}
public void remove() {//remove 掉 上一次next的元素
if (lastRet < 0)//先判断是否next过
throw new IllegalStateException();
checkForComodification();//判断是否修改过
try {
ArrayList.this.remove(lastRet);//删除元素 remove方法内会修改 modCount 所以后面要更新Iterator里的这个标志值
cursor = lastRet; //要删除的游标
lastRet = -1; //不能重复删除 所以修改删除的标志位
expectedModCount = modCount;//更新 判断集合是否修改的标志,
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
//判断是否修改过了List的结构,如果有修改,抛出异常
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}2.1.4 List线程安全问题
ArrayList是非线程安全的,Vector是线程安全的
LinkList工作原理
LinkedList实际上是通过双向链表去实现的。既然是双向链表,那么它的顺序访问会非常高效,而随机访问效率比较低。
LinkedList是通过双向链表的,但是它也实现了List接口{也就是说,它实现了get(int location)、remove(int location)等“根据索引值来获取、删除节点的函数”}。LinkedList是如何实现List的这些接口的,如何将“双向链表和索引值联系起来的”?
实际原理非常简单,它就是通过一个计数索引值来实现的。例如,当我们调用get(int location)时,首先会比较“location”和“双向链表长度的1/2”;若前者大,则从链表头开始往后查找,直到location位置;否则,从链表末尾开始先前查找,直到location位置。这就是“双线链表和索引值联系起来”的方法。
LinkedList底层的数据结构是基于双向循环链表的,且头结点中不存放数据,如下

public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0; // 实际元素个数
transient Node<E> first; // 头结点
transient Node<E> last; // 尾结点
}
private static class Node<E> {
E item; // 数据域
Node<E> next; // 后继
Node<E> prev; // 前驱
// 构造函数,赋值前驱后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}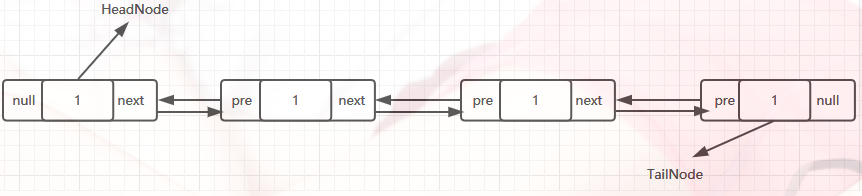
说明:linkedlist的底层数据结构是个双向链表结构,也意味着linkedlist在进行查询时效率会比ArrayList的慢,而插入和删除只是对指针进行移动,相对于ArrayList就会快很多
LinkList 核心函数
public LinkedList() {}
public LinkedList(Collection<? extends E> c) {
this();// 调用无参构造函数
addAll(c); // 添加集合中所有的元素
}
public boolean add(E e) {
// 添加到末尾
linkLast(e);
return true;
}
void linkLast(E e) {
// 保存尾结点,l为final类型,不可更改
final Node<E> l = last;
// 新生成结点的前驱为l,后继为null
final Node<E> newNode = new Node<>(l, e, null);
// 重新赋值尾结点
last = newNode;
if (l == null) // 尾结点为空
first = newNode; // 赋值头结点
else // 尾结点不为空
l.next = newNode; // 尾结点的后继为新生成的结点
// 大小加1
size++;
// 结构性修改加1
modCount++;
}
add(int index, E element) 插入函数
// 插入元素
public void add(int index, E element) {
checkPositionIndex(index); // 检查是否越界
if (index == size) // 在链表末尾添加
linkLast(element);
else // 在链表中间添加
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);//前驱后继关系建立
succ.prev = newNode; //后继节点的前驱指向当前节点
if (pred == null)
first = newNode;
else
pred.next = newNode; //前驱的后继指向当前节点
size++;
modCount++;
}
addAll函数
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
// 添加一个集合
public boolean addAll(int index, Collection<? extends E> c) {
// 检查插入的的位置是否合法
checkPositionIndex(index);
// 将集合转化为数组
Object[] a = c.toArray();
// 保存集合大小
int numNew = a.length;
if (numNew == 0) // 集合为空,直接返回
return false;
Node<E> pred, succ; // 前驱,后继
if (index == size) { // 如果插入位置为链表末尾,则后继为null,前驱为尾结点
succ = null;
pred = last;
} else { // 插入位置为其他某个位置
succ = node(index); // 寻找到该结点
pred = succ.prev; // 保存该结点的前驱
}
for (Object o : a) { // 遍历数组
@SuppressWarnings("unchecked") E e = (E) o; // 向下转型
// 生成新结点
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null) // 表示在第一个元素之前插入(索引为0的结点)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) { // 表示在最后一个元素之后插入
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
// 修改实际元素个数
size += numNew;
// 结构性修改加1
modCount++;
return true;
}
addAll有两个重载函数,addAll(Collection<? extends E>)型和addAll(int, Collection<? extends E>)型,我们平时习惯调用的addAll(Collection<? extends E>)型会转化为addAll(int, Collection<? extends E>)型。
参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下
Node<E> node(int index) {
// 判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) { // 插入位置在前半段
Node<E> x = first;
for (int i = 0; i < index; i++) // 从头结点开始正向遍历
x = x.next;
return x; // 返回该结点
} else { // 插入位置在后半段
Node<E> x = last;
for (int i = size - 1; i > index; i--) // 从尾结点开始反向遍历
x = x.prev;
return x; // 返回该结点
}
}在根据索引查找结点时,会有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
indexOf函数
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
说明:indexOf操作非常简单,就是从头开始遍历整个链表,如果没有就反-1,有就返回当前下标
remove函数
public E remove() {
return removeFirst();
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
E unlink(Node<E> x) {
// 保存结点的元素
final E element = x.item;
// 保存x的后继
final Node<E> next = x.next;
// 保存x的前驱
final Node<E> prev = x.prev;
if (prev == null) { // 前驱为空,表示删除的结点为头结点
first = next; // 重新赋值头结点
} else { // 删除的结点不为头结点
prev.next = next; // 赋值前驱结点的后继
x.prev = null; // 结点的前驱为空,切断结点的前驱指针
}
if (next == null) { // 后继为空,表示删除的结点为尾结点
last = prev; // 重新赋值尾结点
} else { // 删除的结点不为尾结点
next.prev = prev; // 赋值后继结点的前驱
x.next = null; // 结点的后继为空,切断结点的后继指针
}
x.item = null; // 结点元素赋值为空
// 减少元素实际个数
size--;
// 结构性修改加1
modCount++;
// 返回结点的旧元素
return element;
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item; //获取删除节点的元素值(f是头结点)
final Node<E> next = f.next; //存储要删除节点指向的下一个节点地址
f.item = null;
f.next = null; // help GC //将要删除节点的指针以及值全部设置为null,等待 垃圾回收
first = next; //将头结点向下移动
if (next == null)
last = null; //如果要删除节点的下一个为null,则当前链表只有一个节点存在
else //如果不为null,则将前驱设置为null
next.prev = null;
size--;
modCount++;
return element;
}
小结:
ArrayList查询快是因为底层是由数组实现,通过下标定位数据快。写数据慢是因为复制数组耗时。LinkedList底层是双向链表,查询数据依次遍历慢。写数据只需修改指针引用。
ArrayList和LinkedList都不是线程安全的,小并发量的情况下可以使用Vector,若并发量很多,且读多写少可以考虑使用CopyOnWriteArrayList。因为CopyOnWriteArrayList底层使用ReentrantLock锁,比使用synchronized关键字的Vector能更好的处理锁竞争的问题。
Queue&Deque- (数据结构-栈,队列,堆)
Queue 队列的api
public interface Queue<E> extends Collection<E> {
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E element();
E peek();
}
Queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。 如果要使用前端而不移出该元素,使用element()或者peek()方法。
Queue queue=new LinkedList<String>();
queue.offer("A");
queue.offer("B");
queue.offer("C");
String str=null;
while((str= (String) queue.poll())!=null){
System.out.println(str);
}
Deque 双端队列&队列
public interface Deque<E> extends Queue<E>
一个线性 collection,支持在两端插入和移除元素。名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。大多数 Deque 实现对于它们能够包含的元素数没有固定限制,但此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。

在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 Queue 接口继承的方法完全等效于 Deque 方法
Deque 双端队列&栈
用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出


public class Stack {
Deque deque=new LinkedList();
public Stack(){}
public void push(Object o){
deque.offerFirst(o);
}
public Object pop(){
return deque.pollFirst();
}
public Object peek(){
return deque.peekFirst();
}}
由于空栈或者操作失败的情况下直接出栈会抛异常,不好控制,所以我们在用Deque做栈的时候尽量,封装双端队列,作为栈,或者是直接调用双端队列的非异常方法作为栈。

Deque的两种个实现子类
Deque linkedList=new LinkedList();
Deque arrayDeque=new ArrayDeque();
那么双端队列在什么时候使用LinkedList,什么时候使用ArrayDeque呢?

ArrayDeque 源码解析
ArrayDeque是Deque接口的一个实现,使用了可变数组,所以没有容量上的限制。同时,
ArrayDeque是线程不安全的,在没有外部同步的情况下,不能再多线程环境下使用。
ArrayDeque是Deque的实现类,可以作为栈来使用,效率高于Stack;也可以作为队列来使用,
效率高于LinkedList。需要注意的是,ArrayDeque不支持null值。
//用数组存储元素
transient Object[] elements; // non-private to simplify nested class access
//头部元素的索引
transient int head;
//尾部下一个将要被加入的元素的索引
transient int tail;
//最小容量,必须为2的幂次方
private static final int MIN_INITIAL_CAPACITY = 8;
public ArrayDeque() {
elements = (E[]) new Object[16]; // 默认的数组长度大小
}
public ArrayDeque(int numElements) {
allocateElements(numElements); // 需要的数组长度大小
}
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size()); // 根据集合来分配数组大小
addAll(c); // 把集合中元素放到数组中
}
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// 找到大于需要长度的最小的2的幂整数。
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1); //无符号右移一位
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++; 分配刚好大于最小容量的 最接近的2的n次方
if (initialCapacity < 0) // 如果是负的就分配最大容量
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
elements = (E[]) new Object[initialCapacity];
}
// 扩容为原来的2倍。
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
// 既然是head和tail已经重合了,说明tail是在head的左边。
System.arraycopy(elements, p, a, 0, r);
// 拷贝原数组从head位置到结束的数据
System.arraycopy(elements, 0, a, r, p);
// 拷贝原数组从开始到head的数据
elements = (E[])a;
head = 0; // 重置head和tail为数据的开始和结束索引
tail = n;
}
// 拷贝该数组的所有元素到目标数组
private <T> T[] copyElements(T[] a) {
if (head < tail) { // 开始索引大于结束索引,一次拷贝
System.arraycopy(elements, head, a, 0, size());
} else if (head > tail) { // 开始索引在结束索引的右边,分两段拷贝
int headPortionLen = elements.length - head;
System.arraycopy(elements, head, a, 0, headPortionLen);
System.arraycopy(elements, 0, a, headPortionLen, tail);
}
return a;
}
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
// 本来可以简单地写成head-1,但如果head为0,减1就变为-1了,和elements.length - 1进行与操作就是为了处理这种情况,这时结果为elements.length - 1。
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail) // head和tail不可以重叠
doubleCapacity();
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
// tail位置是空的,把元素放到这。
elements[tail] = e;
// 和head的操作类似,为了处理临界情况 (tail为length - 1时),和length - 1进行与操作,结果为0。
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public E removeFirst() {
E x = pollFirst();
if (x == null)
throw new NoSuchElementException();
return x;
}
public E removeLast() {
E x = pollLast();
if (x == null)
throw new NoSuchElementException(); //抛异常不好处理 所以一般不用来做栈和队列
return x;
}
public E pollFirst() {
int h = head;
E result = elements[h]; // Element is null if deque empty
if (result == null)
return null;
// 表明head位置已为空
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1); // 处理临界情况(当h为 elements.length - 1时),与后的结果为0。
return result;
}
public E pollLast() {
int t = (tail - 1) & (elements.length - 1); // 处理临界情况(当tail为0时),与后的结果为elements.length - 1。
E result = elements[t];
if (result == null)
return null;
elements[t] = null;
tail = t; // tail指向的是下个要添加元素的索引。
return result;
}
public E getFirst() {
E x = elements[head];
if (x == null)
throw new NoSuchElementException();
return x;
}
public E getLast() {
E x = elements[(tail - 1) & (elements.length - 1)]; // 处理临界情况(当tail为0时),与后的结果为elements.length - 1。
if (x == null)
throw new NoSuchElementException();
return x;
}
public E peekFirst() {
return elements[head]; // elements[head] is null if deque empty
}
public E peekLast() {
return elements[(tail - 1) & (elements.length - 1)];
}
队列操作
public boolean add(E e) {
addLast(e);
return true;
}
public boolean offer(E e) {
return offerLast(e);
}
public E remove() {
return removeFirst();
}
public E poll() {
return pollFirst();
}
public E element() {
return getFirst();
}
public E peek() {
return peekFirst();
}
public void push(E e) {
addFirst(e);
}
public E pop() {
return removeFirst();
}
栈操作,正是因为这样所以一般不用pop,push
LinkList对队列和栈的支持核心代码
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
PriorityQueue 优先队列
队列是遵循先进先出(First-In-First-Out)模式的,但有时需要在队列中基于优先级处理对象。
每日交易时段生成股票报告的应用程序中,需要处理大量数据并且花费很多处理时间。客户向这个应用程序发送请求时,实际上就进入了队列。我们需要首先处理vip客户再处理普通用户。在这种情况下,Java的PriorityQueue(优先队列)会很有帮助。
public class Customer {
private int id;
private String name;
public Customer(int i, String n){
this.id=i;
this.name=n;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
}
//优先队列自然排序示例
Queue<Integer> integerPriorityQueue = new PriorityQueue<>(7)
//匿名Comparator实现
public static Comparator<Customer> idComparator = new Comparator<Customer>(){
@Override
public int compare(Customer c1, Customer c2) {
return (int) (c1.getId() - c2.getId());
}
};
//用于往队列增加数据的通用方法
private static void addDataToQueue(Queue<Customer> customerPriorityQueue) {
Random rand = new Random();
for(int i=0; i<7; i++){
int id = rand.nextInt(100);
customerPriorityQueue.add(new Customer(id, "Pankaj "+id));
}
}
//用于从队列取数据的通用方法
private static void pollDataFromQueue(Queue<Customer> customerPriorityQueue) {
while(true){
Customer cust = customerPriorityQueue.poll();
if(cust == null) break;
System.out.println("Processing Customer with ID="+cust.getId());
}
}
}默认还是按照ASCII码的方式排序 所以我们又学习了一个排序集合,那么已经有了TreeMap和TreeSet 为什么还要这个优先队列呢?
Processing Customer with ID=6
Processing Customer with ID=20
Processing Customer with ID=24
Processing Customer with ID=28
Processing Customer with ID=29
Processing Customer with ID=82
Processing Customer with ID=96
PriorityQueue 原理分析

PriorityQueue 刚好是一棵顺序存储的二叉树,那么它是怎么做到排序的呢?是二叉排序树的原理?接下来看源码
add()和offer()
add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,
前者在插入失败时抛出异常,后则则会返回false。对于PriorityQueue这两个方法其实没什么差别。
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
//这里找到最后一个节点的父节点
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//用自定义的比较器,比较大小
break;
queue[k] = e;//如果大了 父节点往下移
k = parent;//插入位指向父节点,依次向上,把比当前插入节点大的节点网子点移动。
}
queue[k] = x;//最后在父节点没有比自己大的地方插入
}
//peek()
public E peek() {
if (size == 0)
return null;
return (E) queue[0];//0下标处的那个元素就是最小或者最大的那个
}
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];//这里相当于是取堆顶元素
E x = (E) queue[s];
queue[s] = null;//删除最后一个节点
if (s != 0)
siftDown(0, x);
//重新做堆的调整,从堆顶选择最大的节点来做调整
return result;
}
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)// 右孩子小就用右孩子
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)//比最小的节点小就退出调整
break;
queue[k] = c;//然后用c取代原来的值
k = child;//依次把比较小的孩子替换到父节点
}
queue[k] = x;//然后把最大的元素放到合适的位置上
}
小结:
PriorityQueue调整的代码,不难发现,插入一个节点之后,整个二叉树是往小顶堆的方向调整的,那么如果把自定义的比较器反过来,就会发现又是往大顶堆的方向调整的。所以最终发现原来这里用的是堆排序。堆排序那么这个数据结构用来求解topk问题,相比TreeSet对单元素去重就有优势了。只要往PriorityQueue队列里添加k个元素,然后遍历集合,跟堆顶元素比较大小,比堆顶大的就添加到堆顶,然后从队尾移除一个元素。
PriorityQueue可以作为堆使用,而且可以根据传入的Comparator实现大小的调整,会是一个很好的选择。
ArrayDeque 通常作为栈或队列使用,但是栈的效率不如LinkedList高,所以一般用来实现非线程安全的队列。
LinkedList 通常作为栈或队列使用,但是队列的效率不如ArrayQueue高。一般用来实现非线程安全的栈。















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









