







博客数据分析大屏可视化实现的效果:
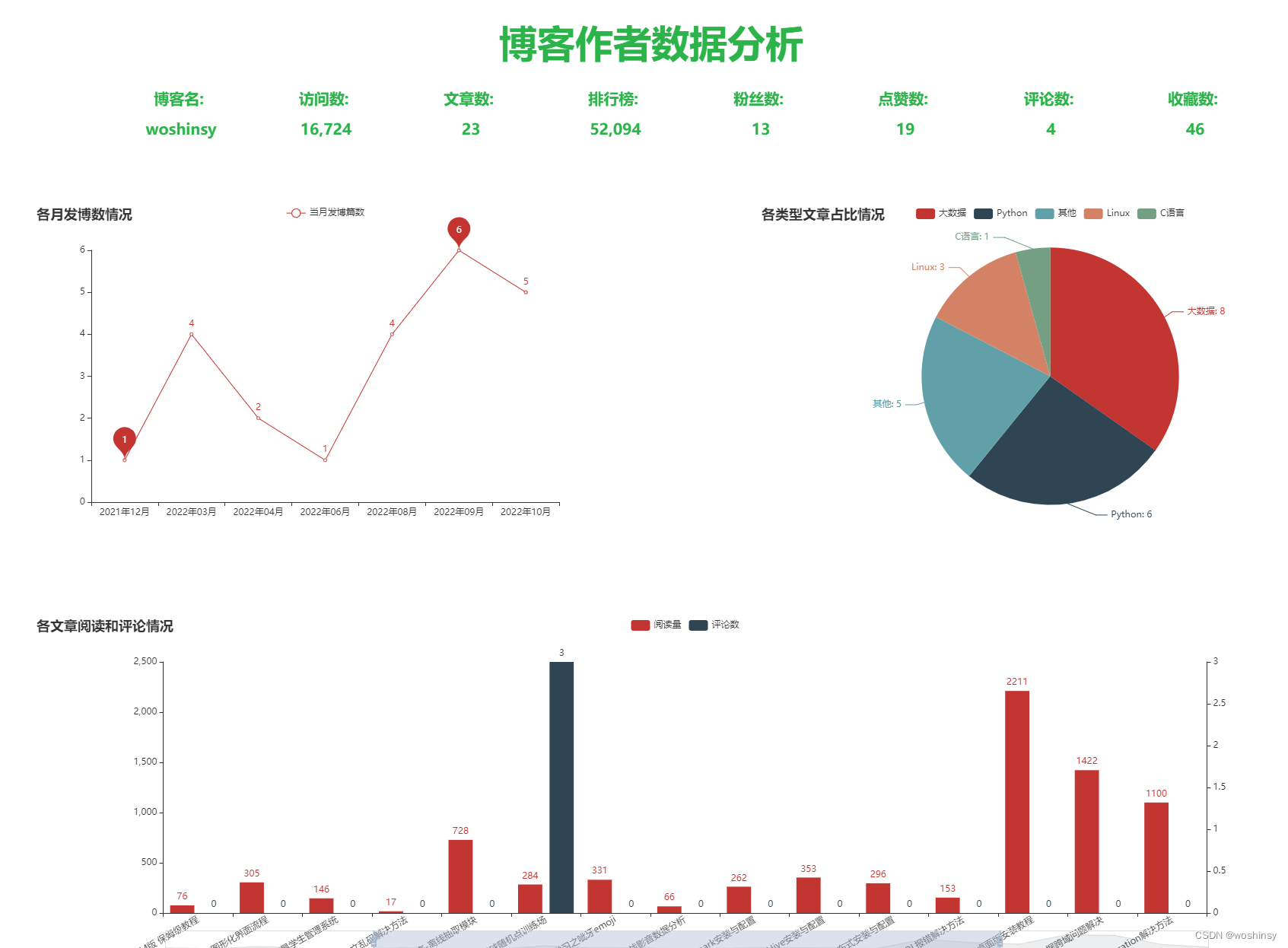
一、核心功能设计
学习笔记分享:
博客作者数据分析实现的思路大致为爬虫(用户通过控制台输入用户博客地址和博客文章地址)和大屏可视化展示两方面。
接下来我们可以通过以下几步实现需求:
- 定义好相关列表准备存储相关信息
- 读取用户收入的博客地址和博客文章地址
- 使用Beautifulsoup解析器的find_all()来进行解析,使用find()和append()实现关键字和数值的查找
- 可视化部分读取excel爬取的数据
- 使用PyEchart实现博客作者详细信息和文章信息图表
二、准备工作
1. Requests
Requests官方文档:requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求。
2. PyEchart
PyEchart官方文档:pyechart
Echarts是一个由百度开源的商业级数据图表,它是一个纯JavaScript的图表库,可以为用户提供直观生动,可交互,可高度个性化定制的数据可视化图表,赋予了用户对数据进行挖掘整合的能力。
三、实现步骤
(一)、爬虫部分实现
1. 获取网页数据并返回
核心设计代码如下:
# woshinsy
def get_html(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (MSIE 10.0; Windows NT 6.1; Trident/5.0)',
}
r = requests.get(url,headers=headers) # 使用get来获取网页数据
r.raise_for_status() # 如果返回参数不为200,抛出异常
r.encoding = r.apparent_encoding # 获取网页编码方式
return r.text # 返回获取的内容
except:
return '错误'
2. 爬取博客作者和文章相关数据
核心设计代码如下:
#woshinsy
def author_info():
# 定义好相关列表准备存储相关信息
head_img = [] # 头像
author_name = [] # 用户名
visitor_num = [] # 访问数
article_num = [] # 文章数
rank_num = [] # 排行榜
fans_num = [] # 粉丝数
like_num = [] # 点赞数
comment_num = [] # 评论数
fav_num = [] # 收藏数
url = input("请输入博客用户地址:")
print(url)
# url = 'https://blog.csdn.net/woshinsy' # 网址
html = get_html(url) # 获取返回值
# print(html) # 打印
# beautifulsoup的find_all()来进行解析。在这里,find_all()的第一个参数是标签名,第二个是标签中的class值(注意下划线哦(class_=‘info’))
soup = BeautifulSoup(html, 'html.parser') # 指定BeautifulSoup的解析器
# 头像
tx = soup.find('div', class_='user-profile-avatar').find('img')['src']
head_img.append(str(tx))
# print(head_img)
# 用户名
yhm = soup.find('div', class_='user-profile-head-name').find('div').get_text()
author_name.append(str(yhm))
# print(author_name)
# 访问量
fwl = soup.find_all('div', class_='user-profile-statistics-num')[0].get_text()
visitor_num.append(fwl)
print(visitor_num)
# 文章数
wzs = soup.find_all('div', class_='user-profile-statistics-num')[1].get_text()
article_num.append(wzs)
print(article_num)
# 排行榜
phb = soup.find_all('div', class_='user-profile-statistics-num')[2].get_text()
rank_num.append(phb)
print(rank_num)
# 粉丝数
fss = soup.find_all('div', class_='user-profile-statistics-num')[3].get_text()
fans_num.append(fss)
print(fans_num)
# 点赞数
dzs = soup.find('ul', class_='aside-common-box-achievement').find_all('span')[0].get_text()
like_num.append(dzs)
print(like_num)
# 评论数
pls = soup.find('ul', class_='aside-common-box-achievement').find_all('span')[1].get_text()
comment_num.append(pls)
print(comment_num)
# 收藏数
scs = soup.find('ul', class_='aside-common-box-achievement').find_all('span') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









