







Pig专门用来处理来自于HDFS的数据,它提供了一套流式的数据处理语言,转化为Map-Reduce来处理HDFS的数据;
Pig包括用来描述数据分析程序的高级程序设计语言,以及对这些程序进行评估的基础结构。Pig突出的特点就是它的结构经得起
大量并行任务的检验,这使得它能够处理大规模数据集。
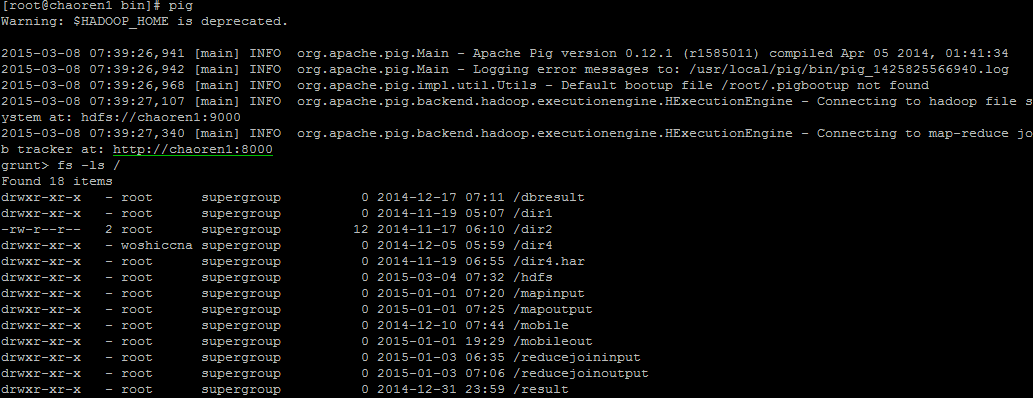
使用pig命令直接进入命令行模式;
在命令行模式照样可以使用hadoop管理HDFS的命令,如fs ls /,运行结果如上图所示,
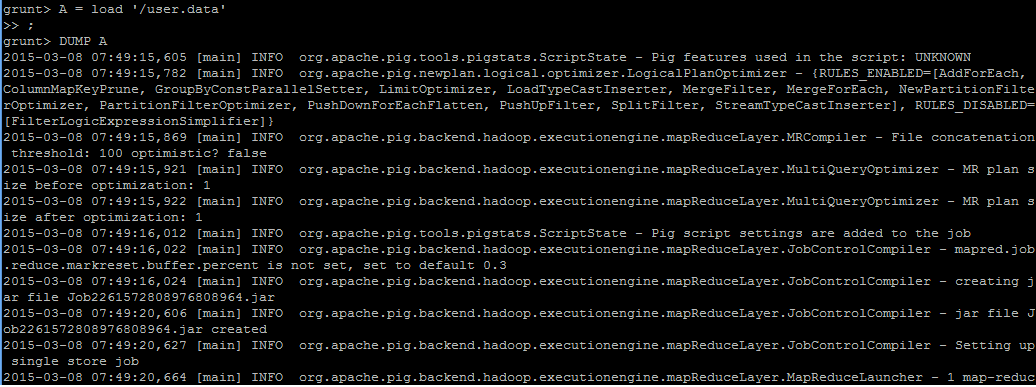
使用A = load '/user.data'来把HDFS中的数据加载到A中,并使用DUMP A来读取出A中的数据信息,此时会把读取的任务做成一个Map-Reduce的任务来
执行;
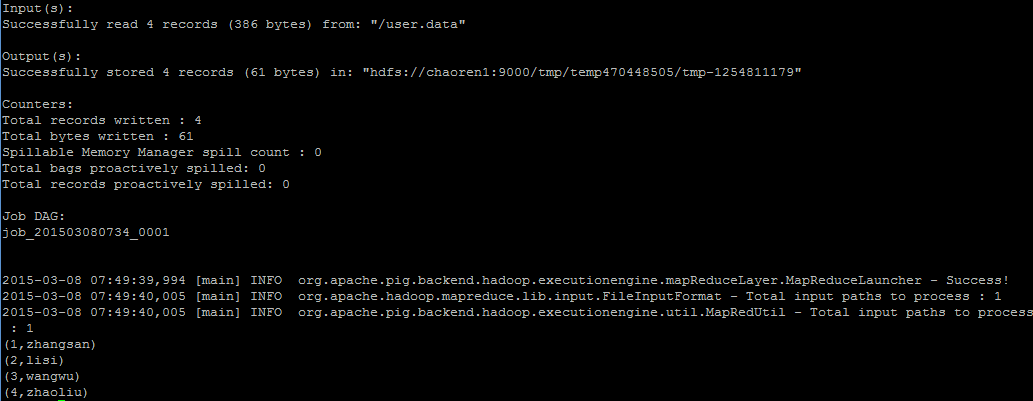
图:程序最后的运行结果
LOAD默认支持是以\t(制表符)分割的文件,如果记录是以(,)逗号分割的呢,
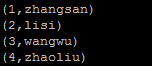
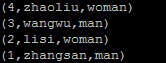
1;zhangsan
2;lisi
3;wangwu
4;zhaoliu
那么应该使用命令 A = LOAD '/user.data' USING PigStorage(';');
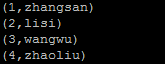
图:程序执行结果
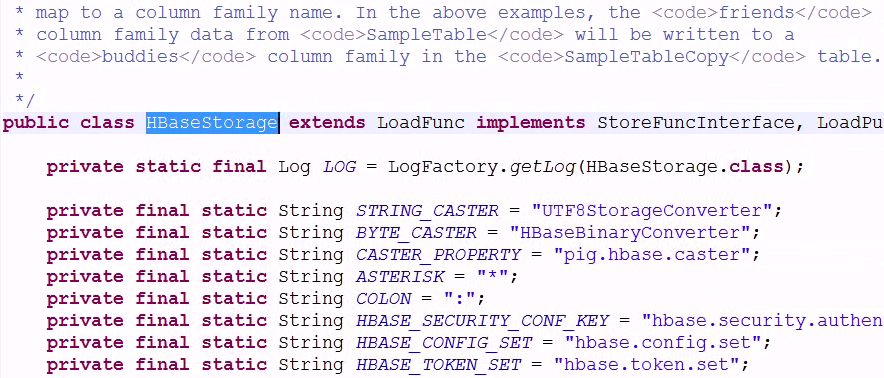
图:HBaseStorage用来加载HBASE中的数据信息

概括几个LOAD操作的例子
(1) 不使用任何方式
A = LOAD 'myfile.txt'
(2)使用加载函数
A = LOAD 'myfile.txt' USING PigStorage('\t');
(3)指定模式
A = LOAD 'myfile.txt' AS (f1:int, f2:int, f3:int);
(4)加载函数和模式均使用
A = LOAD 'myfile.txt' USING PigStorage('\t') AS (f1:int, f2:int, f3:int);

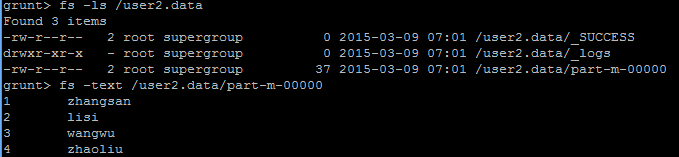
/user2.data是一个目录结构;
Store
它的作用就是将结果保存到文件系统中,STORE alias INTO 'directory' [USING function];
这里的"alias"是用户要存储的结果(关系)的名称,INTO为不可省略的关键字,Directory为用户指定的存储目录的名字,需要用单引号括起来。
另外,如果此目录已经存在,那么Store操作将会失败,输出的文件将被系统命名为part-nnnnn的格式;

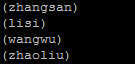
FOREACH
它的作用是基于数据的列进行数据转换,alias = FOREACH {gen_blk | nested_gen_blk} {AS Schema}
通常我们使用"FOREACH ... GENERATE"组合来对数据列进行操作,
(1) 如果一个关系A(outer bag),FOREACH语句可以按照下面的方式来使用:
x = FOREACH A GENERATE f1;
(2) 如果A是一个Inner bag, FOREACH 语句可以按照下面的方式来使用
X = FOREACH B {
S = FILTER A BY 'xyz';
GENERATE COUNT (S.$0);
}
使用$0和$1来制定占位符,当没有制定列的名称时使用,
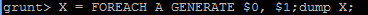




使用describe操作符来查看指定名称的模式;
以下是group的用法


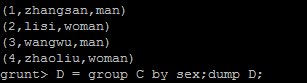


对C的id列降序排列
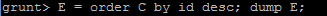
















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











