









- 概述
由facebook开源,最初用于解决海量结构化的日志数据统计问题;
构建在Hadoop上的数据仓库框架(使用MR进行计算,使用HDFS进行数据存储);
把SQL查询转换为一系列在Hadoop集群上运行的MapReduce作业。;
Hive把数据组织为表,通过这种方式为存储在HDFS的数据赋予结构。
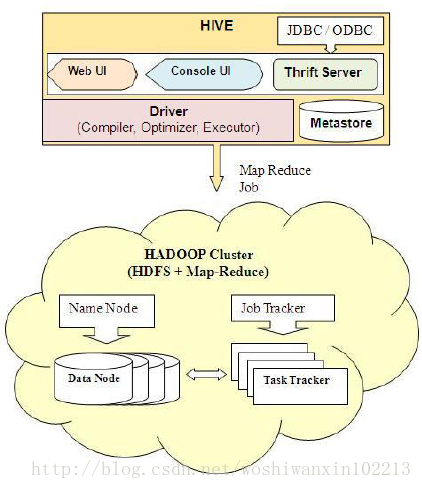
架构图:

- 搭建环境
官网参考:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
1、简要安装流程
##配置环境变量(在/etc/profile尾部添加)
export HIVE_HOME=/usr/hive
export PATH=$HIVE_HOME/bin:$PATH
##解压
$ tar -xzvf hive-x.y.z.tar.gz
$ mv hive-x.y.z /usr/
$ cd /usr
$ mv hive-x.y.z hive
##在HDFS中创建Hive数据的存放目录
hadoop@ubuntu:~$ hadoop fs -mkdir /user/hive/warehouse
hadoop@ubuntu:~$ hadoop fs -mkdir /tmp
##设置对所有用户可写,如果所有用户在同一个组里,权限设置为g+w就可以了
hadoop@ubuntu:/usr/hive/conf$ hadoop fs -chmod a+w /tmp
hadoop@ubuntu:/usr/hive/conf$ hadoop fs -chmod a+w /user/hive/warehouse
hadoop@ubuntu:/usr/hive/conf$ cp hive-default.xml.template hive-site.xml
##以连接mysql为例,需修改hive-site.xml中一下红色部分:
1、
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!--<value>jdbc:derby:;databaseName=metastore_db;create=true</value>-->
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
2、
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<!--<value>org.apache.derby.jdbc.EmbeddedDriver</value>-->
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
3、
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<!--<value>APP</value>-->
<value>root</value>
<description>username to use against metastore database</description>
</property>
4、
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!--<value>mine</value>-->
<value>aa</value>
<description>password to use against metastore database</description>
</property>
5、
<property>
<name>hive.stats.dbclass</name>
<!--<value>jdbc:derby</value>-->
<value>jdbc:mysql</value>
<description>The default database that stores temporary hive statistics.</description>
</property>
6、
<property>
<name>hive.stats.jdbcdriver</name>
<!--<value>org.apache.derby.jdbc.EmbeddedDriver</value>-->
<value>com.mysql.jdbc.Driver</value>
<description>The JDBC driver for the database that stores temporary hive statistics.</description>
</property>
7、
<property>
<name>hive.stats.dbconnectionstring</name>
<!--<value>jdbc:derby:;databaseName=TempStatsStore;create=true</value>-->
<value>jdbc:mysql://localhost:3306/hive?useUnicode=true;characterEncoding=utf8;user=root;password=aa;createDatabaseIfNotExist=true</value>
<description>The default connection string for the database that stores temporary hive statistics.</description>
</property>2、注意点:
1)通过jdbc连接时,需要复制对应的jar包,如连接mysql时,复制mysql-connector-java-5.1.23-bin.jar到/usr/hive/lib 下
2)提示这个的错误:com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Specified key was too long; max key length is 767 bytes
解决方法:在mysql中修改hive元字符集: alter database hive character set latin1;
3)提示这个错误:Caused by: MetaException(message:Version information not found in metastore. )
解决方法:By deafult the configuration property hive.metastore.schema.verification is false and metastore to implicitly write the schema version if its not matching. To enable the strict schema verification, you need to set this property to true in
hive-site.xml.
- 操作符和函数
官网手册:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
参考笔记:http://sishuok.com/forum/blogPost/list/6222.html
补充及注意点:
regexp_extract(string subject, string pattern, int index)
提取字符串subject中,满足正则表达式pattern,group(index)的值
eg:regexp_extract('foothebar', 'foo(.*?)(bar)', 2) 返回'bar.'
parse_url(string urlString, string partToExtract [, string keyToExtract])
从URL中提取host, HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO等
eg: parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') 返回 'facebook.com'
- 数据类型
官网手册:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
- Hive的命令行(Cli)
官网网址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Cli
参考笔记:http://sishuok.com/forum/blogPost/list/6228.html
usage: hive
-d,--define <key=value> Variable substitution to apply to hive
commands. e.g. -d A=B or --define A=B
-e <quoted-query-string> SQL from command line,常用
-f <filename> SQL from files
-H,--help Print help information
-h <hostname> Connecting to Hive Server on remote host
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable substitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-p <port> Connecting to Hive Server on port number
-S,--silent Silent mode in interactive shell,强制不显示多余信息,只显示结果
-v,--verbose Verbose mode (echo executed SQL to the
console)
- Hive QL之SELECT
官网参考手册:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select更多相关资料:
set hive.map.aggr=true;//在map task阶段进行聚合,可提高效率
- SORT BY, ORDER BuoY, CLUSTER BY, DISTRIBUTE BY
- JOIN(关于连接的手册)
- UNION ALL
- TABLESAMPLE
- Subqueries
- Virtual Columns
- Operators and UDFs(操作和函数)
- LATERAL VIEW(用于集合元素查询,和explode函数配合使用)
- Windowing, OVER, and Analytics
补充及注意点:1、ORDER BY是全排序,通过一个Reducer完成,对于大规模数据集,效率较低。可以考虑使用SORT BY,SORT BY为每个reducer产生一个排序文件。DISTRIBUTE BY可控制某个特定行应该到那个reducer,通常为了后续的聚集操作。比如下面例子:hive>FROM records>SELECT year,temperature DISTRIBUTE BY year SORT BY year ASC, temperature DESC;同一个年份的气温在同一个文件中分好组并且排好序。把这个查询作为内嵌子查询时,可利用这一点。如果SORT BY 和DISTRIBUTED BY中所用的列相同,可以缩写为CLUSTER BY以便同时指定两者所用的列。2、使用关键字EXPLAIN或EXPLAIN EXTENDED可查看查询时的执行计划。如:EXPLAIN SELECT .....3、MAP连接:如果一个连接表小到足以放入内存,可把较小的表放入每个mapper的内存来执行连接操作,这样执行时不会使用redcuer。如下:SELECT /*+ MAPJOIN(b) */ a.*, b.* FROM a JOIN b ON (a.id=b.id)这种写法对RIGHT或FULL OUTER JOIN无效。MAP连接可以利用分桶表,因为作用于分桶的mapper加载右侧表中对应的桶即可执行连接,语法和上面的一样,不过要启动以下优化选项:SET hive.optimize.bucketmapjoin=true;4、在HIVE QL中可使用MapReduce脚本,示例如下:.....
- Hive QL之DDL
补充及注意点:1、通过Hive管理Hbase:
2、分区(PARTITION):数据文件并不包含分区列值,分区列和列值构成存储的目录名。但是分区列可以在select语句中使用,读取的是目录名示例:create table logs(ts BIGINT,line STRING) PARTITIONED BY(dt STRING,country STRING);LOAD TABLE logs PARTITION(dt='2014-02-02',country='GB');查看存储的目录结构:/user/hive/warehouse/logs/dt=2014-02-01/country=GB/file1..file2/dt=2014-02-02/country=GB/file3..file4/country=US/file5..file6查询语句(只扫描country=GB下的文件,dt是目录名):select ts,dt,line from logs where country='GB';3、分桶(bucket):好处:可以获得更高的查询效率,比如:连接两个在相同列上划分了桶的表,可以使用map端连接(map-side join)高效地实现;取样更高效。示例:--创建分桶表 CREATE TABLE user_info_bucketed(user_id BIGINT, firstname STRING, lastname STRING) COMMENT 'A bucketed copy of user_info' PARTITIONED BY(ds STRING) CLUSTERED BY(user_id) INTO 4 BUCKETS; --填入数据 set hive.enforce.bucketing = true; //设置此参数后,Hive用表定义时的桶数量来创建桶 FROM user_id INSERT OVERWRITE TABLE user_info_bucketed PARTITION (ds='2009-02-25') SELECT userid, firstname, lastname WHERE ds='2009-02-25'; --取样(约1/4的数据行) select * from user_info_bucketed TABLESAMPLE(BUCKET 1 OUT OF 4 ON userid)hive.enforce.bucketing设置为true时,hive用表定义中声明的数量来分桶,并设置相同数量的reduce。3、存储格式(Row Format, Storage Format, and SerDe) Hive从两个维度对表的存储进行管理:行格式(row format)和文件格式(file format); 行格式:由SerDe(序列化和反序列化工具,把Hive数据行内部表示形式序列化成字节写到输出文件或把文件中的字节数据反序列化为Hive内部操作数据行时使用的对象形式)。 文件格式:指一行中字段容器的格式,纯文本文件、面向行或面向列的二进制格式文件。 Hive的默认存储格式是分隔的文本,默认行分隔符为换行符,行内分隔符是Control-A(^A或八进制形式001),集合元素(ARRAY、STRUCT、MAP)的默认分隔符Control-B,Map的键和值分隔符为Control-C。默认SerDe为LazySimpleSerDe 默认建表语句: CREATE TABLE ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' LINES TERMINATED BY '\n' STORED AS TEXTFILE; 常用的Serde: LazySimpleSerDe:默认使用的SerDe,采用分隔的文本格式,延迟的字段访问 LazyBinarySerDe:LazySimpleSerDe的一个更高效实现,二进制形式的的延迟字段访问。用于像临时表这样的内部使用。 BinarySortableSerDe:类似LazyBinarySerDe,但针对排序进行了优化,损失了部分空间(但仍然比LazySimpleSerDe精简很多) ColumnarSerDe:针对RCFile格式,基于列存储的LazySimpleSerDe变种 RegexSerDe: ThriftByteStreamTypedSerDe HBaseSerDe:用于在HBase中存储数据的SerDe。HBase存储使用Hive存储句柄(handler),存储句柄通过STORED BY子句指定,代替了ROW FORMAT和STORED AS。具体参考https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
- Hive QL之DML
1、把文件(本地文件或HDFS文件)加装(LOAD)到数据表内2、把查询结果插入(INSERT)数据表内3、把查询结果写入(INSERT)本地文件或HDFS
- 配置属性(Configuration Properties)
官网手册:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
参考笔记:http://sishuok.com/forum/blogPost/list/6225.html















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









